![Frequency of letters on craft beads (in a bag of 344 beads) vs frequency of letters in the English dictionary [OC]](https://www.europesays.com/wp-content/uploads/2024/12/mj4bdyga2f7e1-1708x1024.jpeg)
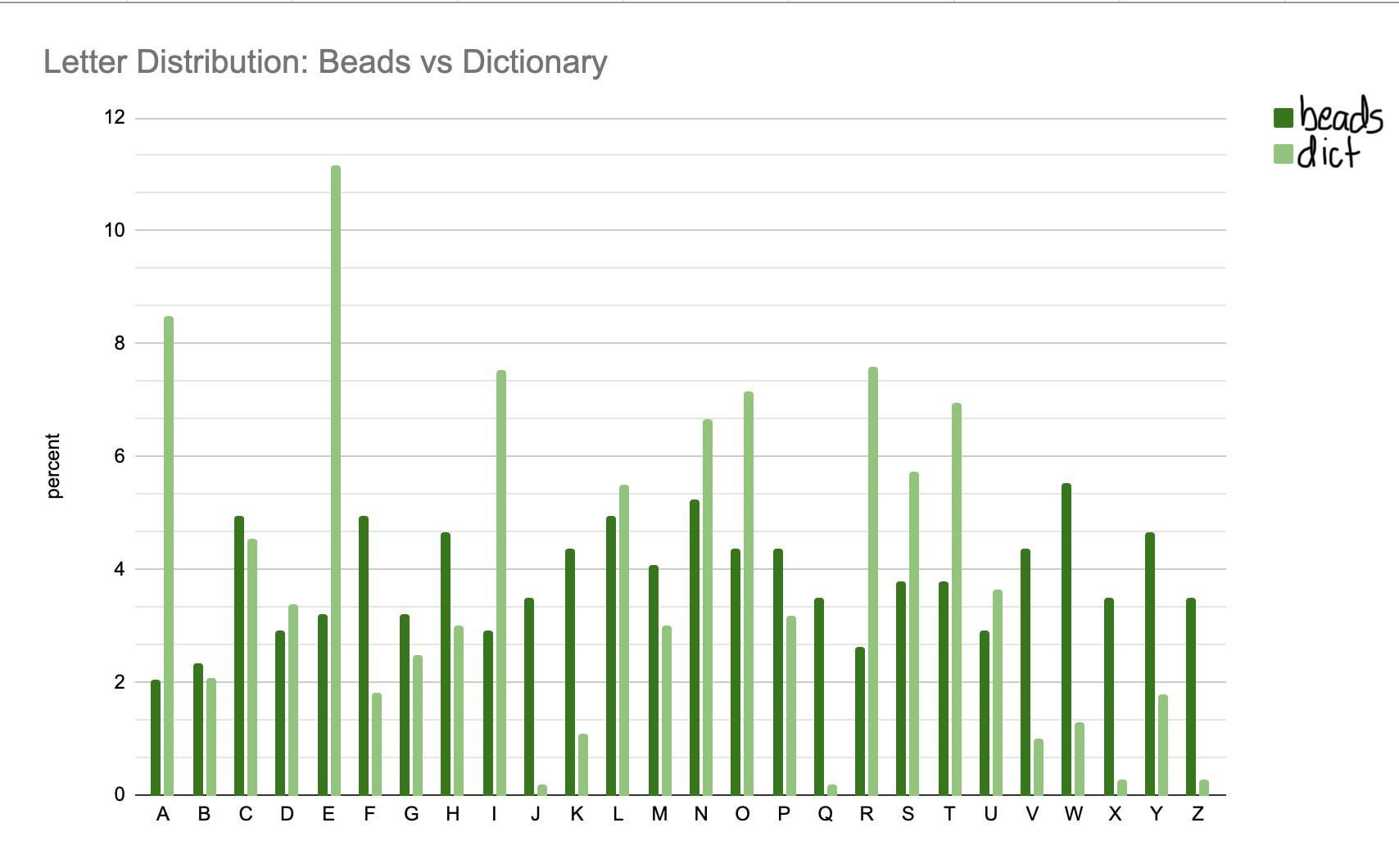
I bought a bag of craft beads with letters on them, and the distribution is wild. I decided to compare it to frequency of the letters in the dictionary. I got the dictionary data from a University of Notre Dame post. Made in Google sheets (could not figure out how to label the index for the life of me)
Posted by Scornedham
9 comments
Tilting my W sideways to get more E
I probably would have used colors that contrast more
At least you got the right amount of D
Here’s the [link to source](https://www3.nd.edu/~busiforc/handouts/cryptography/letterfrequencies.html)
I wouldn’t call the distribution “wild” — it appears to be almost perfectly random to me. With a bag of 26 letters with 344 in each bag, you’d randomly expect to see most of the 26 letters of the between 8 and 19 times, which is what happened.
The expected number for any letter is 344/26 = 13.23, but you’d only get EXACTLY 13 of a letter about 2.9% of the time — you’d also expect to get lots of 14s and 12s and 15s and 11s, etc. That’s how randomness works, and that’s what looks like happened here.
I’d be interested to see it against a frequency of letters in names.
Ive been to the edge of madness wrestling with that indexing issue in other contexts. I think you did it right though.
Maybe the beadmaker had the song “John Jacob Jingleheimer Smith” stuck in their head. Thats a lot more “J”s and “Q”s than is statistically reasonable. XD
Shocking…..”can I buy a Vowel”
Better make the most of those Es.
Comments are closed.