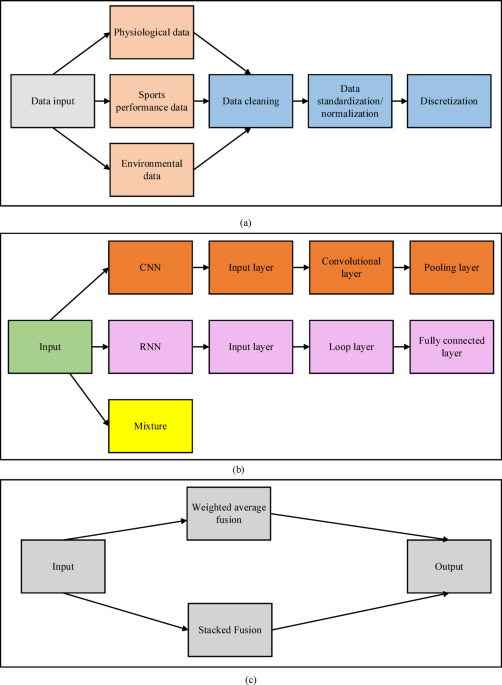
The dataset used here is Daily and Sports Activities Dataset, which is an open and high-quality sports behavior dataset. This dataset contains sensor data of 19 sports activities, such as running, cycling and skipping rope. These data are collected when eight subjects completed five minutes of exercise in their own way. Sensors record data including 3-axis accelerometers and gyroscopes. These sensors are fixed at three positions of the subject’s chest, right arm and left leg, which can fully reflect the characteristics of human movement. Specifically, the dataset contains the following key information:
1.
Sports category: It covers 19 common sports activities such as running, cycling and skipping rope.
2.
Sensor data: High-resolution 3-axis accelerometer and gyroscope signals are provided, which can describe the dynamic characteristics of different motion behaviors.
3.
Data collection method: Each activity is completed by different subjects in an autonomous way, which increases the diversity and generalization of data.
4.
Data structure: Data is presented in the form of time series, which is suitable for tasks such as behavior classification, motion pattern recognition and prediction.
This dataset is suitable for exploring the application of sensor data in sports behavior analysis, and can provide rich features for classification models and prediction models. The main reason why this dataset is selected here is that it includes 19 kinds of sports activities, has great diversity, and can simulate many different sports behaviors in real scenes. It is very meaningful to study the generalization ability of sports training data analysis. Moreover, the dataset contains the data of 3-axis accelerometer and gyroscope, which can fully reflect the movement state of the subjects and provide detailed dynamic information for analysis. In particular, the sensors are arranged in multiple positions (chest, right arm and left leg), which can capture the details in the movement process more accurately.
Datasets can be downloaded through official website (https://archive.ics.uci.edu/dataset/256/daily+and+sports+activities).
The experimental environment is as follows: The information processor is Intel Core i9-13900 K. The image processor is NVIDIA RTX 4090. The display is 64GB DDR5 3200 MHz. The hard disk is 2 TB NVMe SSD. The operating system is Ubuntu 20.04 LTS. The programming language is Python 3.8. The deep learning framework is TensorFlow 2.9.1. The data processing libraries are Pandas 1.4.3 and NumPy 1.22.0. The visualization tools are Matplotlib 3.5.1 and Seaborn 0.11.2. The parameter setting in this paper is optimized for ID3 decision tree algorithm and deep learning model to maximize the performance of the model. In ID3 decision tree, the information gain threshold is set to 0.01 to increase the decision criteria of decision nodes, prevent over-segmentation and reduce over-fitting. The maximum tree depth is set to 15 to limit the complexity of the tree, thus improving the generalization ability. The minimum sample segmentation number is set to 10 to reduce noise interference and improve model stability. At the same time, the post-pruning strategy is adopted, and the minimum number of leaf node samples is set to 5 to prevent the excessive growth of the tree. In addition, the feature selection criteria are based on information gain, and random seeds 42 are used to ensure the reproducibility of experimental results. In the parameter setting of the deep learning model, the learning rate is set to 0.001 to achieve stable model convergence. Setting the batch size to 32 is helpful to balance the convergence speed and model generalization ability in the training process. The number of convolution kernels is adjusted according to the depth of the network, the first layer is set to 64, and the second layer is set to 128, thus capturing rich features at different levels. ReLU is used as the activation function to avoid the problem of gradient disappearance, and Adam optimizer (β1 = 0.9, β2 = 0.999) is used to adapt to the dynamic learning rate requirements of the model. In addition, regularization reduces the risk of over-fitting by setting Dropout to 0.5, and further improves the robustness of the model. The optimization of the above parameters ensures the balance between training efficiency and analysis performance of the model.
The experimental contrast models are Extreme Gradient Boosting (XGBoost), Capsule Networks (CapsNets) and Temporal Fusion Transformer (TFT). XGBoost is an integrated learning algorithm. It combines multiple weak learners (usually decision trees) to improve the generalization ability and accuracy of the model. Different from traditional lifting methods, XGBoost performs well in dealing with sparse data, weighted learning and parallel computing. Compared with the traditional decision tree model, XGBoost greatly improves the training efficiency and prediction ability of the model through incremental learning. In addition, it has good automatic parameter adjustment ability and the efficiency of processing large-scale data. CapsNets is an improved neural network structure, which aims to solve the problem of spatial information loss in the process of feature extraction of CNNs. CapsNets captures the characteristics and relative position of spatial hierarchy through the “capsule” structure. CapsNets shows good performance in image recognition and sequence analysis, especially in the condition of object rotation, scaling and other deformation, maintaining the robustness of feature extraction. It replaces the traditional maximum pooling operation by dynamic routing mechanism, which improves the fidelity of features. Transformer was first used in NLP, but it was gradually applied to time series analysis. TFT model can better capture the long-term dependence in time series data by introducing self-attention mechanism, and realize efficient dynamic fusion among multi-dimensional features. Different from the traditional RNN or LSTM network, TFT can process time step data in parallel, reduce sequence dependence and improve training efficiency. In addition, it allows users to make multidimensional dynamic selection of features. These three models are novel and have great advantages in different application scenes, and can be effectively compared with ID3 decision tree and deep learning model.
Performance evaluation
Performance comparison experiment
The performance comparison experiment of the model is studied. The comparison indexes are accuracy, training time, inference time, model complexity, memory usage and misclassification rate. The experimental results are shown in Fig. 2:
Performance comparison experiment results (a) Accuracy (b) Training time (c) Inference time (d) Model complexity (e) Memory usage (f) Misclassification rate.
In Fig. 2a, in the case of data volumes of 1000, 2000 and 3000, the accuracy of the optimized model is the best in all data volumes, and the highest accuracy can reach 95.257%. The accuracy of TFT model is slightly lower, but it still performs well, reaching 93.241%. The accuracy of XGBoost and CapsNets is relatively low, especially CapsNets, whose accuracy is lower than 91% in all data volumes. In Fig. 2b, the training time of XGBoost is the shortest under different data volumes, and even on 3000 pieces of data, the training time is still controlled within 165.763 s. The training time of CapsNets and TFT is obviously longer, and the training time of TFT reaches 316.123 s when the data volume is large. The training time of the optimized model is between the two, and the performance is relatively balanced. In Fig. 2c, in terms of inference time, XGBoost is the best, and its inference time is kept within 5.567 milliseconds under all data. The inference time of TFT is longer, and that of CapsNets is the highest, which is close to 16 milliseconds. After optimization, the inference time of the model is kept at about 7.891 milliseconds. The model complexity of TFT is the highest, and the number of its parameters exceeds 16,000 regardless of the size of data. In Fig. 2d, XGBoost and the optimized model are similar in complexity, while CapsNets has the lowest model complexity under all data volumes, only about 9000 to 11,000. In Fig. 2e, XGBoost consumes the least memory. Even if the data volume increases to 3000, its memory usage is still less than 260 MB. The memory usage of CapsNets and TFT increases significantly, and the memory usage of TFT reaches 433.456 MB when the data volume increases, while the optimized model performs moderately in this respect. The result of Fig. 2f shows that the optimized model has the lowest misclassification rate in all data, especially in 2000 data, and its misclassification rate is reduced to 5.906%. The misclassification rate of TFT is also good, but it is slightly higher than the optimized model. The misclassification rate of CapsNets increases when the data volume increases. Especially, when there are 3000 data, it reaches 9.996%.
Analysis experiment of sports training data
To further verify the effectiveness of the optimized model, an experiment is conducted to analyze the sports training data. The comparison indexes are mean square error (MSE), mean absolute error (MAE), information gain, feature importance, sports performance improvement rate and training target achievement rate. Each index is divided into three different dimensions, and the experimental results are shown in Fig. 3:
Experimental results of sports training data analysis (a) MSE (b) MAE (c) Information gain (d) Feature importance (e) Sports performance improvement rate (f) Training target achievement rate.
Figure 3a shows that MSE of XGBoost fluctuates slightly in three dimensions, with the highest being 2.19 and the lowest being 1.48. The MSE of CapsNets model is stable. While TFT performs slightly better in all dimensions. The MSE value is relatively small. The MSE of the optimized model is at the lowest level in all dimensions, and the highest is 1.57. The performance of MAE shows that the optimized model has the lowest error in all dimensions, with the lowest error reaching 0.65. The result of Fig. 3b shows that TFT is slightly better than CapsNets and XGBoost in error control. The MAE value of XGBoost is high, exceeding 1.1 in all dimensions. The result of Fig. 3c shows that the optimized model performs best in each dimension, with the highest information gain of 1.02. The performance of TFT and CapsNets is close. While that of XGBoost is relatively weak, and the maximum information gain is only 0.66. In Fig. 3d, the optimized model has a high performance in all three dimensions, with the highest value of 0.94. The performances of TFT and CapsNets are similar, while XGBoost has relatively low feature importance in all dimensions. The result of Fig. 3e shows that the optimized model performs well in the promotion rate of sports performance, and maintains a high promotion rate in all three dimensions, reaching a maximum of 6.71. TFT and CapsNets perform slightly worse, and XGBoost is relatively weak in performance improvement rate. In Fig. 3f, the optimized model performs best, with the highest goal achievement rate of 78.32% in the three dimensions. The performances of TFT and CapsNets are similar, ranging from 68 to 76%. XGBoost has the lowest goal achievement rate, slightly lower than other models.
Discussion
The six performance indicators are compared under different data volumes, and the results show that the optimized model is the most balanced in key indicators such as accuracy and misclassification rate. It achieves low misclassification rate and moderate inference time while maintaining high accuracy, showing strong generalization ability. Especially in terms of MSE, MAE, information gain and target achievement rate, the optimized model is significantly better than other models. However, for practitioners, it is of great significance to deeply analyze the trade-off between resource usage (such as memory and processing time) and model performance.
XGBoost has become a lightweight choice in time-sensitive scenes because of its simple structure and high computational efficiency. For example, it performs best in inference time and is suitable for real-time feedback systems. However, its performance in accuracy and misclassification rate is relatively average, especially in complex data scenarios. Its error control ability is limited, which limits its application in high-precision demand scenarios. CapsNets performs well in information gain and feature importance, thanks to its unique advantages in capturing spatial relations and subtle features. This makes it have application potential in some scenes that need deep feature extraction, such as technical action analysis or complex behavior classification. However, the high resource demand of CapsNets, especially the high inference time and memory occupation, limits its application in resource-limited equipment or real-time scenes. TFT has shown strong performance in accuracy, especially when dealing with multi-modal time series data. However, its high model complexity and memory occupation have become the main bottlenecks limiting its practical application. For example, in the scenario of personalized training plan, although TFT can provide accurate prediction by analyzing long-time series data, its high resource demand may not be suitable for sports training environment with limited resources. The optimized model achieves a good balance between resource consumption and performance. For example, it is more efficient than CapsNets and TFT in inference time and memory occupation, while maintaining high accuracy and low misclassification rate. This advantage makes it suitable for training and reasoning in scenes with large data, especially for sports training and analysis tasks that need to balance precision and resources.
In practical application, the advantages of these models can be transformed into practical values. For example, the optimized model can be used to build a personalized training plan, and by analyzing the training data of athletes, the training intensity and content can be dynamically adjusted to improve the training effect. In addition, it can also be used to predict the performance of athletes, provide scientific decision support for coaches, and thus improve the competitive level. In scenes with limited resources, such as portable devices or real-time monitoring applications, XGBoost can be preferred, while in scenes requiring in-depth feature analysis (such as motion technology optimization), CapsNets may be more attractive. TFT is suitable for long-term monitoring and complex behavior prediction, but it needs to overcome its high requirements for computing resources.
Compared with previous studies, this paper has significantly improved in feature selection, interpretability, computational efficiency, and adaptability to sports training data analysis. For example, compared with the study of Hosseini et al. (2024), this paper has stronger adaptability in analyzing sports training data46. Their Expert Control Algorithm algorithm is more inclined towards general neural network optimization, while the model in this paper is specifically designed for the multimodal characteristics of exercise training data, including the fusion of multidimensional features such as physiological indicators, exercise performance, and environmental data. In addition, experimental verification in scenarios such as sports training prediction, health risk monitoring, and action analysis shows that the model can be applied to different types of sports training data, demonstrating higher adaptability and practical application value. This sports training data analysis method that integrates ID3 decision trees and deep learning provides new research ideas for sports science and big data analysis, promoting the development of intelligent and data-driven optimization in sports training.
To sum up, each model shows its unique advantages in different application scenarios, and the optimized model stands out with its balanced performance. It provides a reliable tool for sports training data analysis and brings new possibilities for personalized training plan and sports performance prediction in practical application. In the future, these models can be more widely used in practical scenarios by further optimizing the trade-off between resource use and model performance.