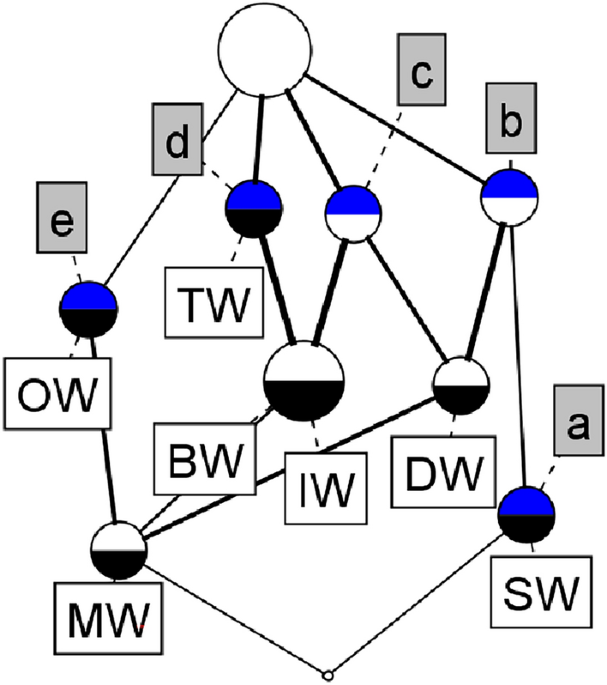
In this section we compute the ID3 values for the many-valued temperature-rain data presented in Table 7.The readers are advised to refer18,21,22 to know about the computation process of entropy values for the attributes. Using Eqs. (1) and (2) from section 4, we get the following results.
Information entropy H(S)=0.9501
IG (Winter): 0.9501–0.7254 = 0.2247
IG (Summer): 0.9501–0.8102 = 0.1399
IG (Monsoon): 0.9501–0.8917 = 0.0584
IG (Autumn): 0.9501–0.8455 = 0.1046
ID3 based precedence order of attributes
An attribute that has a greater precision value is ranked highly since it is important in the decision-making context. According to this rule, we get Winter > Summer > Autumn > Monsoon. The precedence order of attribute according to the gain measure is W > S > A > M. The notation W > S means that W is more important than S.
The information gain measure gives the quantifies the amount of information present in a datasets. The higher information gain values attribute to the higher level of useful data present in the datasets. So the priority of seasons W > S > A > M spell out that winter season has higher impact on the rainfall whereas monsoon has the least impact of the rainfall.
The variation of the results to the reality regarding the ranking that Winter > Summer > Autumn > Monsoon, is due to the individual seasons’ contribution to the overall rain yield to the entire year. It’s true that the monsoon seasons have heavy rainfall while compared with the other seasons. But it happens almost uniformly for all the years. So, it has less important role in deciding the high rainfall for the year. At the same time the other seasons play a vital role in making high rainfall for the year. For example, though the summer has few rainfall days, its contribution to the rainfall of the year is significant since it changes the rainfall yield from lower to higher level for the year. The same explanation can be made for the other seasons, too.
The set of discarded precedence relation order is then listed. According to the precedence relation, A>M implies that attribute A is the direct predecessor of attribute M.
Precedence relation-based discarded concepts
A>M
C20, C21, C26, C27, C28, C29, C30, C31, C32, C33, C36, C37, C38, C39, C40, C41, C42, C43, C44, C45, C46, C47, C48, C49.
S>A
C15, C18, C19, C20, C21, C22, C24, C26, C28, C29, C30, C31, C32, C33, C34, C35, C36, C37, C38, C41, C42, C43, C44, C45, C46, C47, C48, C49.
W>S
C16, C17, C18, C19, C22, C23, C24, C25, C28, C29, C30, C31, C32, C33, C34, C35, C36, C37, C38, C39, C40, C42, C43, C44, C45, C46, C47, C48, C49.
The following is the compressed concepts for each pairwise precedence relation.
Concept retained after precedence relation
A>M
C1, C2, C3, C4, C5, C6, C7, C8, C9, C10, C11, C12, C13, C14, C15, C16, C17, C18, C19, C22, C23, C24, C25, C34, C35, C46.
S>A
C1, C2, C3, C4, C5, C6, C7, C8, C9, C10, C11, C12, C13, C14, C16, C17, C23, C25, C27, C39, C40.
W>S
C1, C2, C3, C4, C5, C6, C7, C8, C9, C10, C11, C12, C13, C14, C15, C20, C21, C26, C27, C41.
The final reduced collection of concepts includes only those concepts that obey to the precedence order relation with regard to at least one precedence order pair of characteristics. Concepts are eliminated from the set if they do not follow the precedence order relation of attributes with regard to any of the precedence order pairs.
33 concepts have been reduced, as follows
C1, C2, C3, C4, C5, C6, C7, C8, C9, C10, C11, C12, C13, C14, C15, C16, C17, C18, C19, C20, C21, C22, C23, C24, C25, C26, C27, C34, C35, C39, C40, C41, C46.
In any given situation, we expect that an object’s attributes should adhere to at least one precedence order pair relation. Therefore, this must also be true for every concept’s attribute or intent. The union of these concepts resulting from each precedence order pair must then be the intended set of final compressed concepts. Thus out of the 50 total number of original concepts, after reduction the number of concepts obtained is 33.
Measurement of quality of compressed concepts
In this section, determine each attribute’s weight, probability, and expectation using Eqs. (3) and (4) we get the below Table 9.
Next, we use Eqs. (5) and (6) to calculate the relevant of concepts, which is the Intent Average Value (IAV), weight, and deviation for each concept. The outcomes are shown in Table 10 .
In Table 11, we tabulate the calculation related to reduced concepts.
Validation process-calculation of percentage error
The results are validated with the help of error measure. The error rate represents the percentage error of deviance for the compressed concepts with respect to the original ones for he temperature-rain data.
\(\sum D(I) = 0.7760\), \(d=0.7760/50 = 0.0155\) and \(\sum D(I^{\prime }) = 0.5840\), \(d^{\prime } = 0.5840/33 = 0.0177\) Where I, \(I^{\prime }\) stands for the intents of original and compressed concepts respectively.
Here v = \(max\{d,d^{\prime }\}\) = \(max\{0.0155, 0.0177\}\) = 0.0177.
Using these values, in equation(7), we get
\(\delta\) = \(\left| \frac{d-d^{\prime }}{v}\right| \times 100\)
\(= 0.1248 \approx 12\%\)
It is observed that there is a negligible percentage error \(\delta =12\%\) of weight deviance between compressed concepts. Since the percentage of error \(\delta , the threshold level for better model which we discussed earlier, we can conclude that the removed concepts have higher deviations by means of their intent weights than the existing (compressed) concepts.Consequently, we can draw the conclusion that the compressed concepts can be regarded as more relevant.
FCA can be an effective technique for investigating and displaying correlations particularly with smaller, more precisely defined datasets with distinct categories. However, when the dataset is huge, the representation of data with the use of FCA becomes more complex and difficult to understand. To overcome such limitations, preprocessing (such as discretisation) and supplementary techniques may be needed when applying it to continuous, sizable, or noisy datasets. This preprocessing stage is adopted by the authors in this article also. Similarly, ID3 algorithm also has limitations with regard to scalability, handling continuous data, and preventing overfitting, even though it can be helpful in some situations, particularly with smaller, simpler datasets and classification problems. Such issues are resolved here in the preprocessing stages.
Climate data is not uniform throughout any region or country. So the accuracy of data lacks as the region is expanded. Se we have collected data from a particular place in order to understand an analysis the data more accurately. If needed the analysis can be carryout for any specific region.
We have considered 15 years of temperature and rain data. Table 11 contains the important concepts that are retained. In our analysis, we find that the attribute ML (Monsoon Low temperature) occurs 21 times and it is mostly available in the 15 years period which implies that it is a vital attribute in the rainfall prediction. Next important attribute is SH (Summer High temperature) which is found 16 times. In a similar way we can understand the importance of remaining attributes. We believe that the analysis of the reduced concepts can help the farmers and other service providers who need the rainfall prediction data in understanding climatic changes that happen before rainfall.