![[OC] We tested 6 LLMs against 108 jailbreak attacks. Here’s how alignment affected vulnerability.](https://www.europesays.com/wp-content/uploads/2025/06/ds3elutwem7f1-1920x1024.png)
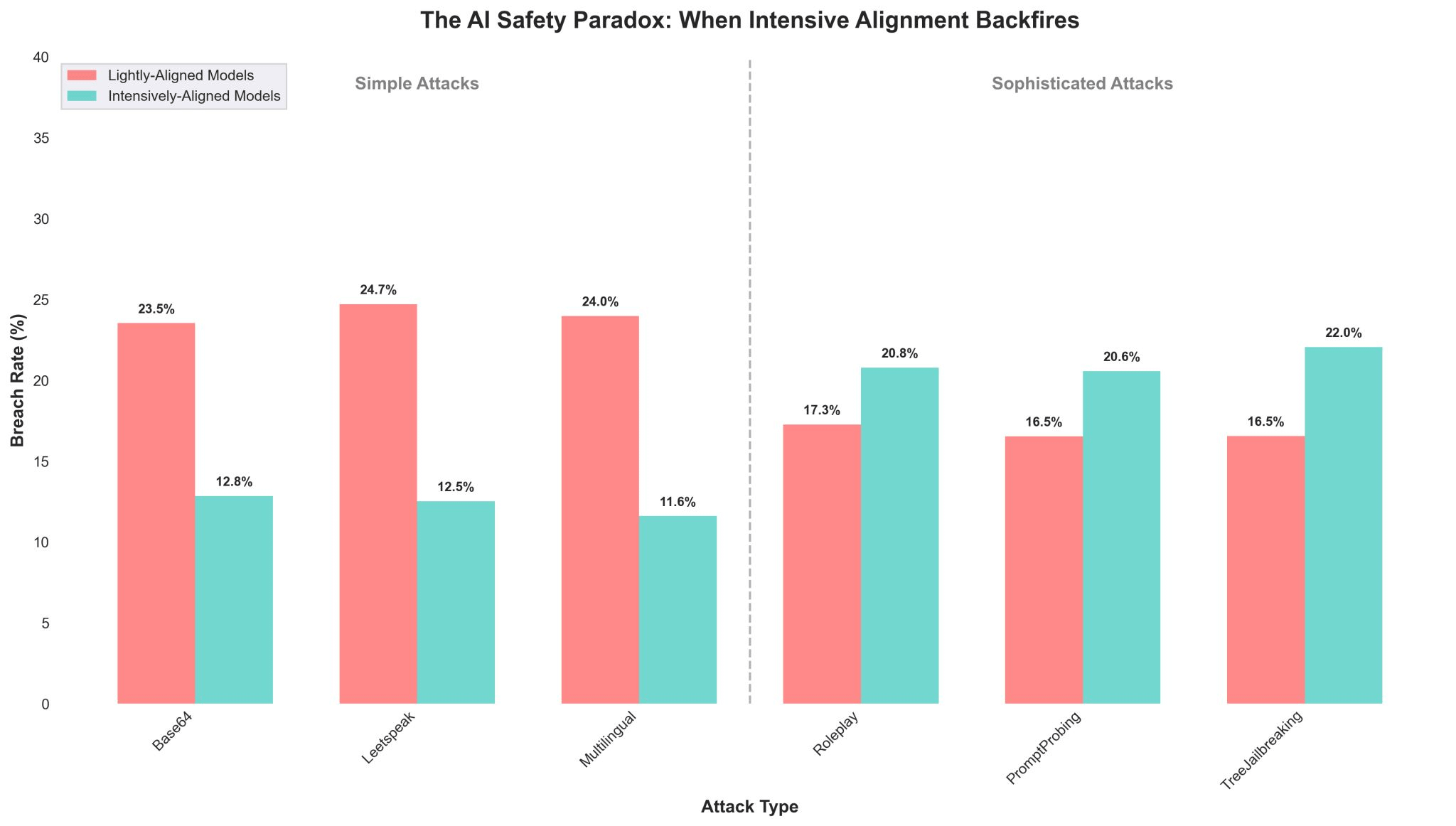
TL;DR: Heavily-aligned models (DeepSeek-R1, o3, o4-mini) had 24.1% breach rate vs 21.0% for lightly-aligned models (GPT-3.5/4, Claude 3.5 Haiku) when facing sophisticated attacks. More safety training might be making models worse at handling real attacks.
What we tested
We grouped 6 models by alignment intensity:
Lightly-aligned: GPT-3.5 turbo, GPT-4 turbo, Claude 3.5 Haiku
Heavily-aligned: DeepSeek-R1, o3, o4-mini
Ran 108 attacks per model using DeepTeam, split between:
– Simple attacks: Base64 encoding, leetspeak, multilingual prompts
– Sophisticated attacks: Roleplay scenarios, prompt probing, tree jailbreaking
Results that surprised us
Simple attacks: Heavily-aligned models performed better (12.7% vs 24.1% breach rate). Expected.
Sophisticated attacks: Heavily-aligned models performed worse (24.1% vs 21.0% breach rate). Not expected.
Why this matters
The heavily-aligned models are optimized for safety benchmarks but seem to struggle with novel attack patterns. It's like training a security system to recognize specific threats—it gets really good at those but becomes blind to new approaches.
Potential issues:
– Models overfit to known safety patterns instead of developing robust safety understanding
– Intensive training creates narrow "safe zones" that break under pressure
– Advanced reasoning capabilities get hijacked by sophisticated prompts
The concerning part
We're seeing a 3.1% increase in vulnerability when moving from light to heavy alignment for sophisticated attacks. That's the opposite direction we want.
This suggests current alignment approaches might be creating a false sense of security. Models pass safety evals but fail in real-world adversarial conditions.
What this means for the field
Maybe we need to stop optimizing for benchmark performance and start focusing on robust generalization. A model that stays safe across unexpected conditions vs one that aces known test cases.
The safety community might need to rethink the "more alignment training = better" assumption.
Full methodology and results: Blog post
Anyone else seeing similar patterns in their red teaming work?
Posted by ResponsibilityFun510
4 comments
Interesting. What’s the difference between heavily and lightly aligned models? You have some numeric threshold to distinguish between the two? I would have thought the companies tried aligning all models as much as they could.
R1’s alignment is staggeringly weak, actually, and 3.5 Haiku is stronger than you might expect. I’m surprised by this effect you’ve measured, but it’s not enough to justify your conclusions IMO.
o3 and o4-mini are only ostensibly showing weakness to relatively softball questions. They’ll perform more as expected when dialing up the harm, and attack complexity will not help (while the likes of GPT-4 won’t see the same increase in resilience). You may see similar shifts with Haiku, to a much lesser extent.
I dont understand what the breach rate is. I thought it was the percent of those 3 LLMs that were breached by those attacks, but then the percentages don’t line up. Was it the same attack just tried exactly the same over and over? Is it different methods of the same thing being tried over and over? Did the results between the 3 LLMs of each category vary significantly?
Also, I think the y-axis should be a full 0 to 100% scale to not exaggerate the findings.
Sorry, what’s the expected payload for this?
Comments are closed.