
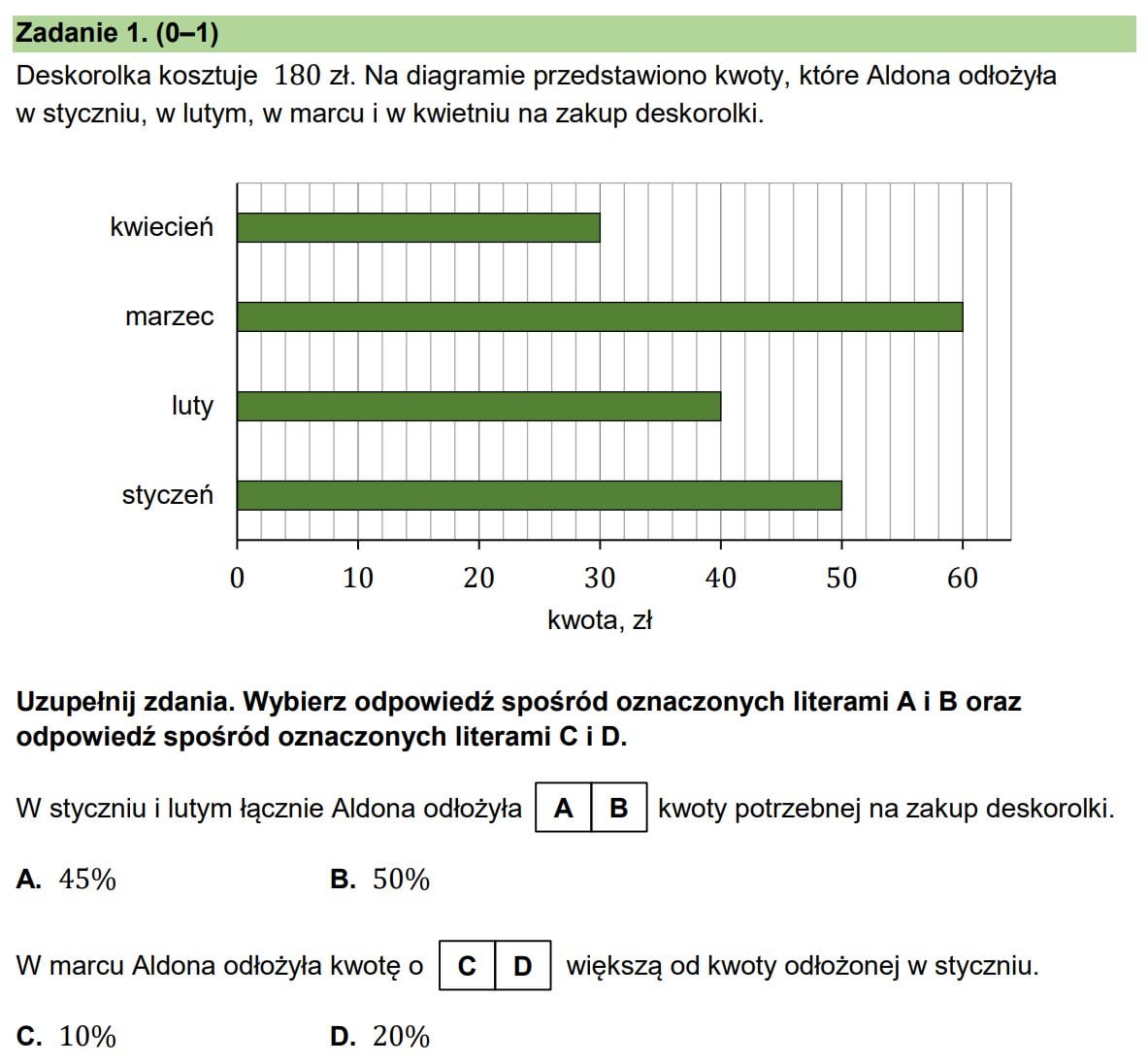
Yesterday I shared the results of the Polish eight-grade exam. In the math exam, the 16 Polish states scored between 44% and 56%.
For my little experiment I individually screenshoted the first 15 questions and one by one – without further instructions – gave them to OpenAI o3, Gemini 2.5 Pro and Claude Sonnet 4, after the initial prompt
Jesteś polskim studentem zdającym egzamin z matematyki. Otrzymujesz po jednym pytaniu na raz. Rozwiąż je i zakończ odpowiedź poprawnym rozwiązaniem.
o3 and Gemini each scored 14/15 (93.3%), both getting task 12 wrong:
Claude Sonnet 4 lags behind with 12/15 (80%), but I should add that it's not the company's strongest model. I don't have access to Claude Opus 4, safe to assume it would have performed better.
I uploaded the answers of Gemini 2.5 Pro to Imgur, if anyone wants to see how it solve the tasks. o3 was much less talkative.
Note: With such benchmarks there's always a risk of contamination, meaning public questions and answers becoming part of the training data and thus the models having them memorized. This is highly unlikely here, since questions and answers have only been made public very recently. The Gemini version I used has a knowledge cutoff of January 2025, that's before the exams were held in May.
by opolsce
8 comments
Time and time again, it’s proven that we shouldn’t apply human evaluation to ai, because their weaknesses lie in different areas.
Did you add “don’t search the web for solution”? They sometimes do even unprompted.
Interesting- yet only thing I can see a bit wrong is the prompt
Word “student” in polish refers to college students only.
So it could mislead model a bit and make it more advanced in learning than it should
I think “uczniem klasy 8” or just “uczniem” would be better
[removed]
I could have had that easier. Instead of individual screenshots one by one, I tried uploading the entire pdf with the prompt
>Jesteś polskim studentem zdającym egzamin z matematyki. Rozwiąż pytania od 1 do 15 w załączonym pliku i zakończ odpowiedź poprawnym rozwiązaniem. Na koniec, podsumuj swoje odpowiedzi w tabeli z dwiema kolumnami: Numer zadania i poprawna odpowiedź.
in AI Studio. After 196.4 seconds, just a tad faster than the three hours humans have: Same score (14/15) and again task 12 wrong.
https://preview.redd.it/fm5dlrkwmtbf1.png?width=344&format=png&auto=webp&s=ded69dbfbd642731188d9066a8d89e9b29ef459c
Okay and? What’s your conclusion? I think most people are capable of consistently scoring high on tests if you let them freely cheat. Do you think the progress of LLMs is going to make schools redundant? Education is based on the internalization of existing knowledge. Whether AI can find an answer to test questions nobody actually cares about is at best irrelevant, and at worst detrimental to the process
(83-56)/3 = 9,
83+2*9 = 101, C jest nieparzysta, **F**
83-9 = 74, B jest mniejsze niż 74, **P**
Why not all the questions?
Comments are closed.