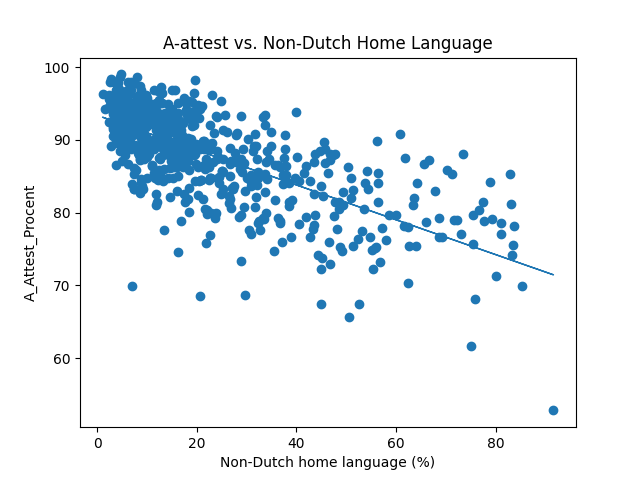
Wat is R? De correlatiecoefficiënt? Die ziet er niet al te hoog uit.
Correlation vs Causation?
“Er zit een kat in de deuk van een dak, hierdoor heeft de kat voor de deuk in het dak gezorgd”
Kan je de dataset zelf ook delen, en enige duiding geven? Stelt zo’n punt een school voor, of een gemeente, of wat? Hoeveel datapunten zijn er in totaal? Merendeel van de punten liggen duidelijk linksboven, maar het maakt wel een verschil of die cluster 80% of 90% of 99% of 99.9% van de data representeert. Ben ook wel benieuwd naar die scholen waar minder dan 70% (of zelfs maar iets meer dan de helft) van de leerlingen slaagt, da’s echt wel heel slecht.
Hoe moet ik dat percentage op de x-as interpreteren? Bij 0% spreek je dan 100% van de tijd Nederlands of ben je dan voor 100% de taal machtig?
Statistiek heeft mij nooit een A-attest bezorgd maar dit lijkt me nogal vreemd.
What does the % Non-Dutch home language actually mean?
I can only imagine it is like 0, 50 or 100%?
100% No dutch spoken at home
50% Dutch spoken with one parent
0% Dutch spoken with both parents
Zoals zo vaak in sociale wetenschappen en in feite alle wetenschap zegt deze ene grafiek in feite weinig want is maar een heel nauwe kijk op een complex gegeven.
Mogow zeg. Da had ik nu echt nie gedacht.
/s
Dit is dikke quatsch. Tenzij dit gecorrigeerd is voor een hoop covariaten (socio-economische context, scholingsgraad van de ouders, enkel/twee-ouder gezinnen, etc.) is dit nietszeggend. Er is niet eens een 95%-confidence interval voor die trend (die ook niet-lineair is en gefit is met een lineair model).
Zonder controle van factoren zoals inkomen van de ouders is dit weinig zeggend.
11 comments
Credits aan /u/moneytit !
Wat is R? De correlatiecoefficiënt? Die ziet er niet al te hoog uit.
Correlation vs Causation?
“Er zit een kat in de deuk van een dak, hierdoor heeft de kat voor de deuk in het dak gezorgd”
Kan je de dataset zelf ook delen, en enige duiding geven? Stelt zo’n punt een school voor, of een gemeente, of wat? Hoeveel datapunten zijn er in totaal? Merendeel van de punten liggen duidelijk linksboven, maar het maakt wel een verschil of die cluster 80% of 90% of 99% of 99.9% van de data representeert. Ben ook wel benieuwd naar die scholen waar minder dan 70% (of zelfs maar iets meer dan de helft) van de leerlingen slaagt, da’s echt wel heel slecht.
Hoe moet ik dat percentage op de x-as interpreteren? Bij 0% spreek je dan 100% van de tijd Nederlands of ben je dan voor 100% de taal machtig?
Statistiek heeft mij nooit een A-attest bezorgd maar dit lijkt me nogal vreemd.
What does the % Non-Dutch home language actually mean?
I can only imagine it is like 0, 50 or 100%?
100% No dutch spoken at home
50% Dutch spoken with one parent
0% Dutch spoken with both parents
Zoals zo vaak in sociale wetenschappen en in feite alle wetenschap zegt deze ene grafiek in feite weinig want is maar een heel nauwe kijk op een complex gegeven.
Mogow zeg. Da had ik nu echt nie gedacht.
/s
Dit is dikke quatsch. Tenzij dit gecorrigeerd is voor een hoop covariaten (socio-economische context, scholingsgraad van de ouders, enkel/twee-ouder gezinnen, etc.) is dit nietszeggend. Er is niet eens een 95%-confidence interval voor die trend (die ook niet-lineair is en gefit is met een lineair model).
Zonder controle van factoren zoals inkomen van de ouders is dit weinig zeggend.
Comments are closed.