![Data teams only trust AI answers about 5.5/10, according to our survey. [OC]](https://www.europesays.com/wp-content/uploads/2025/09/alo9mcidcdnf1-1920x1024.png)
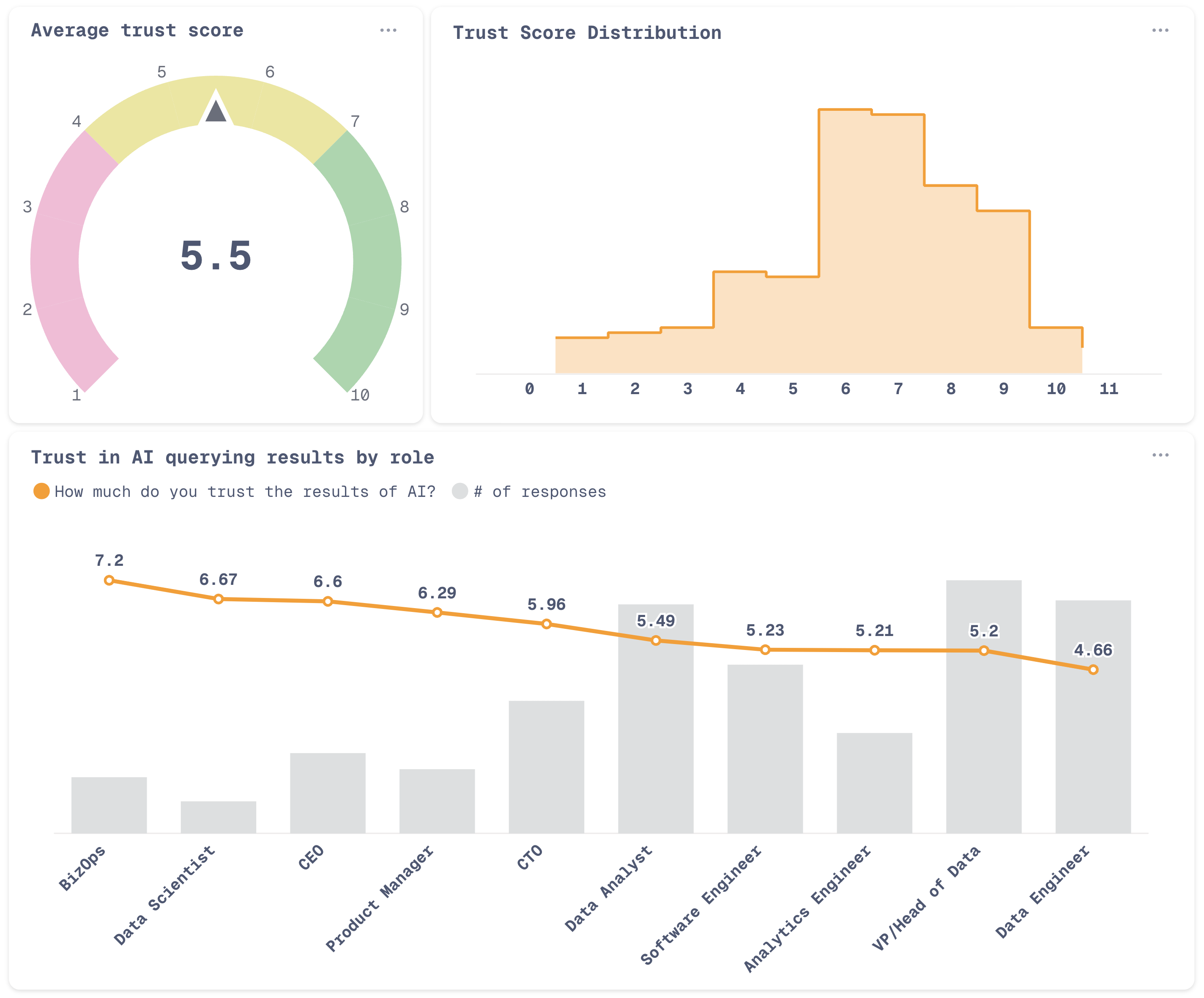
Despite high adoption of AI-powered query generation, trust in the results is generally low. People in engineering roles (especially data engineers), trust AI results much less, but that doesn't translate into lower adoption of AI querying.
Posted by Miserable_Fold4086
8 comments
As an electrical engineer, any single thing plugged into AI has to be manually verified no matter what anyway. It’s simply good for suggestions. In my anecdotal experience, 40-60% chance of being correct sounds about right when asked a high level technical question.
Data scientists so high because they put up the ai product xD
Ai is one of the biggest and sneakiest double edged swords humankind has invented in the last century.
It could create a time of unprecedented prosperity, or it could usher the end of our modern era entirely. It seems just as likely to help us as it is to hurt us.
At the moment, it both is and isn’t helping… it’s taking up more and more resources, creating glaring mistakes and disrupting various institutions with no real way to understand the long term effects of it’s adoption. There are very troubling signs, and I still have yet to see anyone show me concrete results of it’s implementation that are ultimately a *good* thing. Sure… it could spot and treat diseases like cancer, it could predict weather patterns, it could increase ‘corporate’ efficiency (is that good? Jury still out). But at what cost to humanity? At what cost to freedoms and privacy and basic rights?
Many of our wannabe technocratic overlords have *dubious* and duplicitous motives and questionable to horrific ethics… and they seem to be the biggest proponents of this technology. But every serious scientist and voice I’ve heard discuss AI seems to be either entirely against it, or suspicious of it’s ultimate results, and warning us about what it might do. When you get past the billions being poured into the advertising to make it seem banal or good for humanity, what’s really going on?
[https://www.youtube.com/watch?v=79-bApI3GIU](https://www.youtube.com/watch?v=79-bApI3GIU)
[https://www.youtube.com/watch?v=giT0ytynSqg&t=260s](https://www.youtube.com/watch?v=giT0ytynSqg&t=260s)
[https://www.youtube.com/watch?v=RhOB3g0yZ5k](https://www.youtube.com/watch?v=RhOB3g0yZ5k)
My biggest concern is the secretive and manipulative nature of the people pushing AI into the public sphere with possible ulterior and nefarious motives… including those who truly believe in *Accelerationism*, ie – (in this context) creating *the* singularity at which point technology evolves beyond our ability to control and reeks havoc on our civilization.
I would like the correlation to *how* trustworthy the query results *is* in each role. It’s not like BizOps and Data Engineers run the same queries. I think some roles would come out as trusting bad results more than others, and some results simply being better.
I’m confused. The average score is purportedly 5.5, which coincidentally is the average of the numbers 1 to 11.
Meanwhile the frequency distribution on the top right showed a clear skew to the right making the average much closer to 7.
Is the point that the AI can’t calculate an average.
Or was the chart maker thick
Or am I thick
I think all those roles have a different meaning of “trusting AI”, a data scientist might trust the AI because he can spot when it’s hallucinating and can prompt it better, while a BizOps or CEO just blindly trust it
A few weeks ago I was playing with Gemini’s deep research, and it’s genuinely not trustworthy when it comes to data. The funny thing is, it fails in the oddest ways, that completely renders the output useless in a way that a human won’t fail at.
I asked it the type of simple task you’d expect an intern to do in a day or two:
Here is a list of wine prices: [insert URL]
Please go through the data, sort it by appellation, and then for each Rhone appellation, please sort by price, find the average price, and the price of the 20 and 80th percentile bottle. Then give me the cheapest and most expensive 5 bottles in each appellation. Create a report with this data, and visualize it.
If you give this task to an intern, you might get some terrible writing, bad data viz, or the intern might miss a few data points. But give it to Gemini, and it straight up made up a few non-existent bottles, because I was going through the cheapest and most expensive bottles. No actual human will make this type of mistake.
The funny thing is, if you asked me to teach “Business Intelligence 101” at a local college, and you submitted this, I might actually grade this Gemini generated report a pass – Sure, it messed up 3 data categories, but the writing is solid! C+, don’t make data mistakes next time.
What is the gray bar showing? Number of responses, but unlabeled?
Huge lol at CEOs trusting it so highly, and data analysts not trusting it.
Comments are closed.