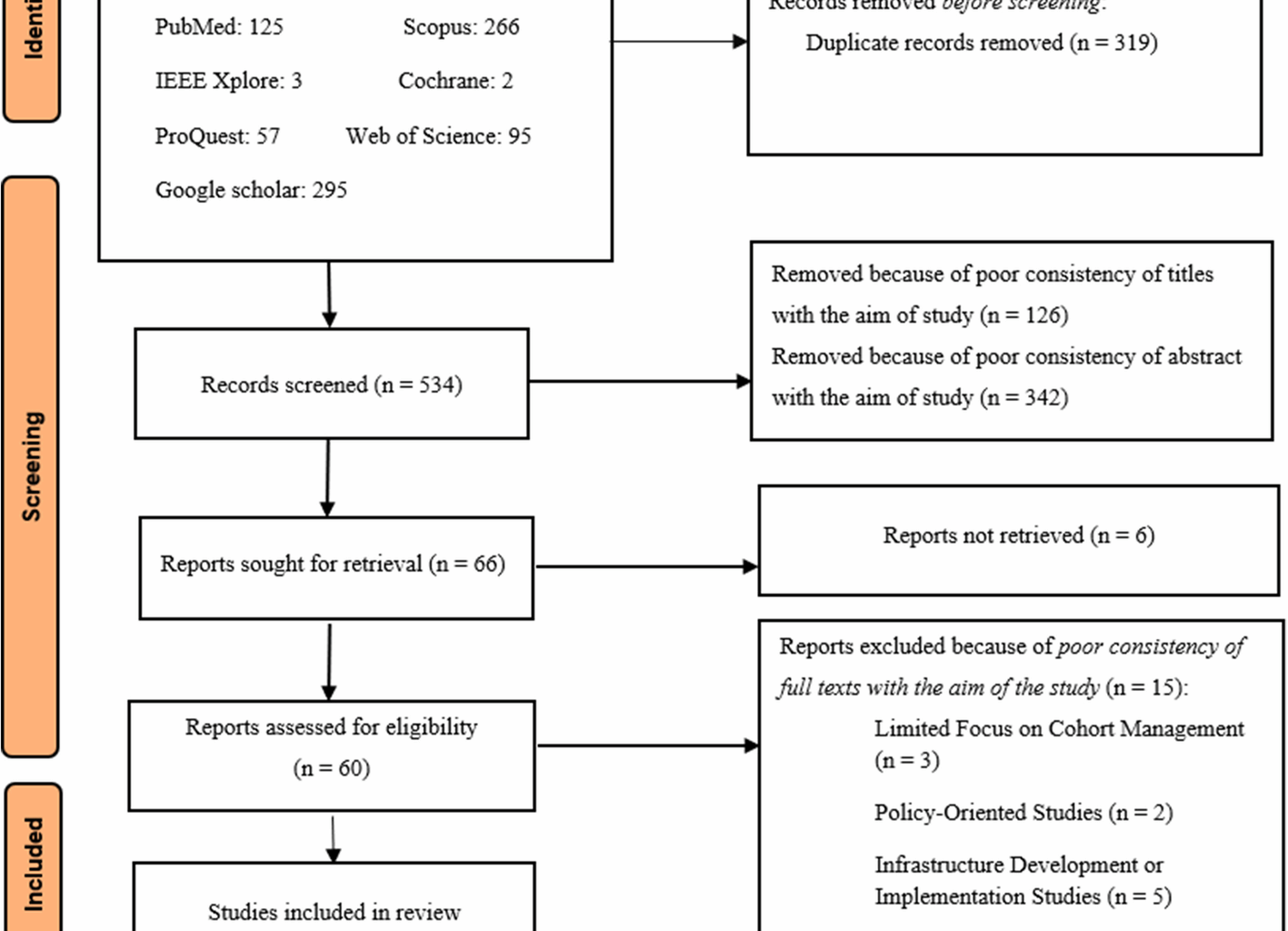
Initially, a total of 843 articles were identified from searching databases and various scientific resources (Fig. 1). Using Endnote software, 319 duplicated articles were removed, leaving 543 articles for further review. In the screening phase, 126 articles were initially excluded due to the mismatch of titles with the research objectives. Then, during the abstract review, 342 articles were excluded from the review process due to the inconsistency of the abstracts with the study objectives. Finally, 66 articles were selected for full-text retrieval and review. After evaluating the articles based on the full text, 60 articles were identified eligible, but 15 articles were excluded from the final study for specific reasons, including limited focus on cohort data management (three articles), studies which focused on policy-making (two articles), focused on infrastructure development or implementation (five articles), limited to specific diseases or registry-based studies (two articles), observational studies without focusing on system functionalities (one article), and insufficient coverage of FRs and NFRs characteristics (two articles). Finally, 45 articles were found eligible for the final review and entered into the study.
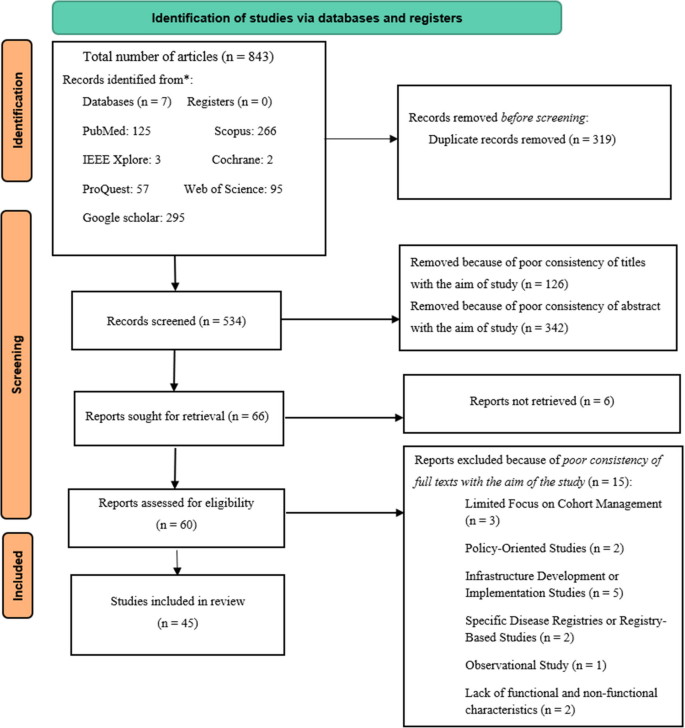
Article selection process based on the PRISMA-ScR guideline
As Fig. 2 shows, the year 2020 had the highest number of related publications (eight studies), highlighting a peak that may be attributed to an increase in research activity during the COVID-19 pandemic.
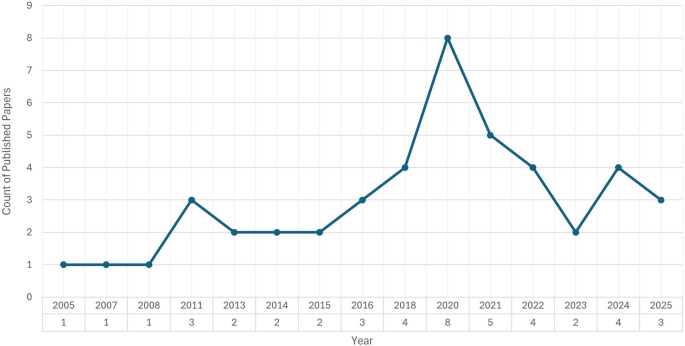
Distribution of the selected studies based on the publication year
In terms of geographical distribution (Fig. 3), the majority of the reviewed studies were from the United States (eleven studies), Germany (six studies), the United Kingdom, Switzerland (each one three studies). Other countries, including China, France, Italy, and South Korea, each contributed to two studies, while Malaysia, Thailand, European Union, Cameroon, Bangladesh, Senegal, Spain, Ireland, Canada, Netherlands, Japan, Poland, Uganda, and Sweden each contributed to one study. A summary of the reviewed articles is presented in Table 1.
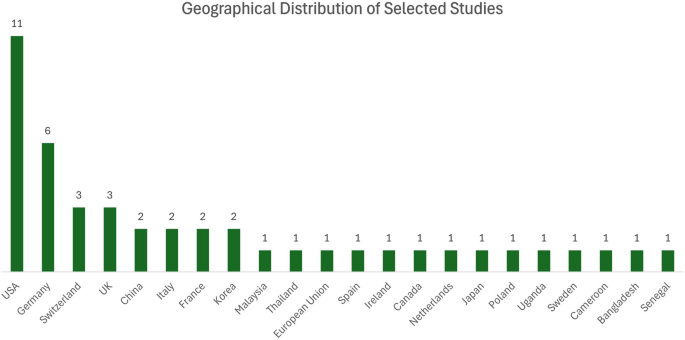
Distribution of the selected studies based on the geographical areas
The reviewed studies span a diverse range of disease contexts, reflecting the multifaceted applications of CDMS across global health research. Figure 4 illustrates major disease categories addressed in the reviewed studies. The distribution highlights an emphasis on infectious diseases, cancers, and cardiovascular conditions, reflecting global health priorities for creating CDMS with precise FRs and NFRs. Several studies also targeted underrepresented areas such as autoimmune, mitochondrial, and pediatric disorders, underscoring the diversity and evolving scope of cohort-based research.
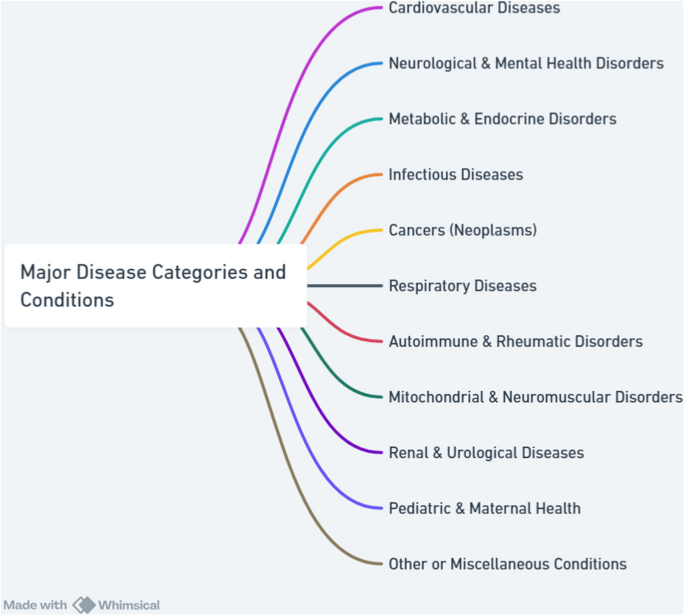
Major disease categories and conditions addressed in the reviewed studies
Figure 5 illustrates the overall distribution of FRs and NFRs across the reviewed studies. It also helps to identify gaps where certain requirements might be underrepresented or less emphasized.
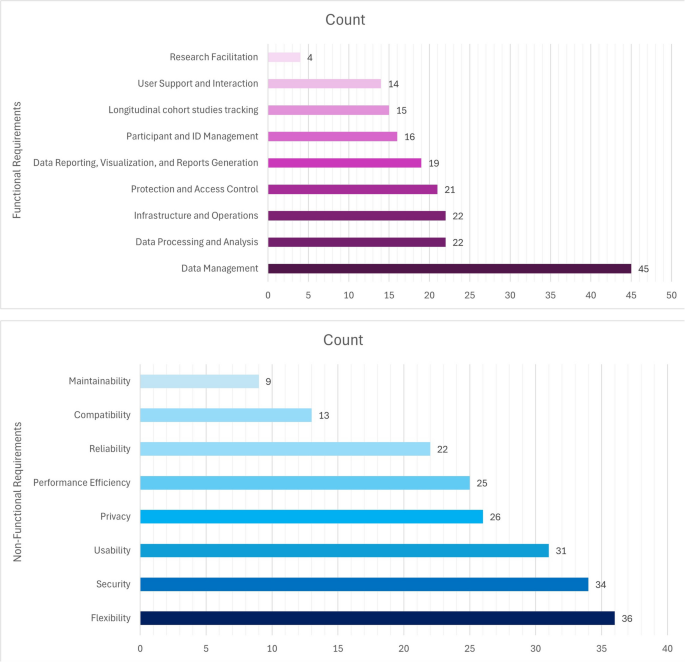
Distribution of functional and non-functional requirements of CDMS in the reviewed studies
Functional Requirements (FRs)
FRs define the specific functions, behaviors, and services that a system or system component must provide to meet users’ and stakeholders’ needs. FRs describe what the system must do, like specific actions, tasks, or interactions, without specifying how these functions are achieved. According to ISO/IEC/IEEE 29148:2018, functional requirements focus solely on the required capabilities of the system, such as processing data, supporting user transactions, or generating reports to fulfill its intended purpose [74].
The findings showed that the main FRs for CDMS were divided into nine categories, including data management, participant and ID management, data processing and analysis, longitudinal cohort studies tracking, protection and access control, data reporting, visualization, and reports generation, infrastructure and operations, User support and interaction, and research facilitation which are explained below in more detail. Figure 6 presents a hierarchical breakdown of FRs and their respective subcategories.
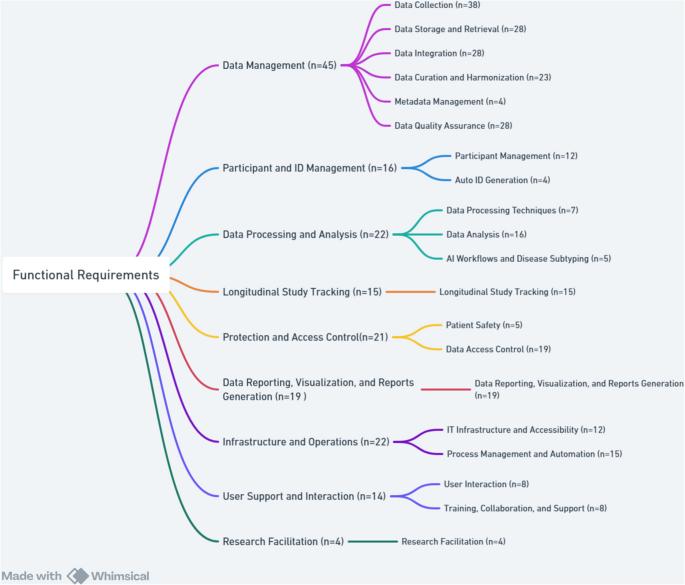
Breakdown of Main Functional Requirements of CDMS by SubcategoriesFootnote
The total count for each requirement refers to the number of specific requirements that were addressed through one or more of its subcategories. A single article might cover multiple subcategories under the same main requirement, or it might address only one subcategory.
Data management
Data management specifies the basic functions a system must provide to handle data effectively. These consist of data collection from various sources, storage and retrieval for efficient access, integration of data from heterogeneous systems, curation and harmonization, metadata management for organizing contextual information, and quality assurance to maintain data accuracy and completeness. Across 38 studies [4,5,6,7,8, 11, 14, 20, 22,23,24,25, 27,28,29,30,31,32, 34, 35, 37, 39, 42,43,44, 47, 60,61,62,63, 65, 66, 68,69,70,71,72,73], diverse strategies for data collection were discussed, ranging from manual entry [7, 72, 73] to advanced electronic systems including Research Electronic Data Capture (REDCap), Study of Health in Pomerania (SHIP), SHIPdesigner, and open data kit planner (ODK_planner) [27, 43, 62, 63]. Electronic health records, automated summarization, and clinical data management systems could improve accuracy, efficiency, and adherence to Findable, Accessible, Interoperable, and Reusable (FAIR) principles [5, 6, 63, 70]. Tools like VESPRE (virtually enabled biorepository and electronic health record (EHR)-embedded) for biobank tracking [20, 42] and self-reported data collection methods [8, 14, 68] enhanced research capabilities. Data sources span EHRs, genomics, wearable devices, biomarkers, cancer genomics platforms, and custom solutions like eCIMS and HeDIMS [22, 23, 28, 30, 35, 60, 61].
Efficient data storage and retrieval were addressed in 28 studies [5,6,7,8, 20, 22, 23, 25,26,27,28,29,30, 35,36,37, 45, 47, 60,61,62,63, 65,66,67, 69, 70, 73]. Solutions such as Next-Generation Sequencing (NGS) databases, MySQL, Rakai Health Sciences Program (RHSP) Data Mart, and Training Support Information Management System (TSIMS) [22, 23, 30, 60, 61], as well as queryable warehouses and cloud-based platforms [28, 35, 36], provided scalability and analytical power. Data integration was emphasized in 28 [7, 11, 20,21,22, 26,27,28,29, 31, 32, 35,36,37, 41, 42, 45, 60,61,62,63,64,65, 67,68,69, 71, 72], where linking various components of the Health Information System (HIS), Electronic Health Records (EHRs), Picture Archiving and Communication System (PACS), survey data, and biobank repositories improved patient profiling, precision medicine, and longitudinal analysis [21, 22, 32, 42, 60, 61, 67, 71] Platforms like Aetiology of Neonatal Infection in South Asia (ANISA) [69] facilitated data integrations.
Curation and harmonization were reported in 23 studies [4,5,6,7,8, 22, 23, 26,27,28, 30, 31, 34, 39, 42, 47, 60, 61, 65, 66, 69,70,71] to emphasize cleaning, validation, standardization, and harmonization across datasets. Automated checks, real-time validation, and harmonization tools maintained harmonization in multi-center studies [7, 22, 26, 28, 42, 60, 65, 69]. Standardization practices including International Classification of Diseases, 10th Revision (ICD-10), Health Level Seven (HL7), and genomic data models, were crucial for interoperability [28, 61], while Classification and Regression Tree (CART) models and alert systems supported EHR preprocessing and validation [34, 70, 71]. Metadata management, as discussed in four studies [22, 29, 45, 64], featured standardized cataloging, versioning, and graph databases to enhance reproducibility and discovery. Data quality assurance was examined in 28 studies [6,7,8, 20,21,22, 24,25,26,27, 30, 31, 35,36,37, 39, 41, 44, 45, 61,62,63, 67,68,69,70,71,72] and relied on automated checks, audit trails, error management protocols, and compliance with frameworks like ISO/IEC 27001 and GDPR to ensure accuracy, reliability, and security [6, 8, 20, 22, 25, 27, 30, 31, 35, 37, 39, 41, 44, 61,62,63, 69,70,71,72].
Participant and ID management
Participant and ID management studies involved organizing and tracking individuals within a study, ensuring accurate linkage between participants and their data. It included participant management and automatic ID generation to uniquely and securely identify each subject while maintaining confidentiality. Twelve studies [6, 8, 14, 23, 25, 26, 42, 60, 63, 67, 70, 73] emphasized the importance of automated registration, real-time monitoring, and efficient consent procedures as key requirements for ensuring data quality and retention. Advanced EHR systems like VESPRE [42] and CART-based automated cohort creation [70] streamlined participant management by reducing manual effort and improving efficiency, especially for enhancing real-time data monitoring and informed decision-making [67]. Engagement tools, including reminders, newsletters, and interactive strategies improved adherence and long-term retention [25, 26, 73]. Practical systems like SHIP and Web-based modular control and documentation system offered modular, flexible solutions for tracking participants, managing workflows, and ensuring anonymization [23, 26, 60]. The importance of automatic ID generation in cohort studies was demonstrated in 4 studies [22, 30, 37, 61]. Studies used Universally Unique Identifier version 4 (UUIDv4) for each NGS record and related files, registration/medical record numbers for patient linkage, and 10-digit SIDs for participants [22, 30, 37, 61].
Data processing and analysis
Data processing and analysis involved transforming raw data into meaningful insights through structured processing techniques and analytical methods. It also included AI workflows and disease subtyping to uncover patterns, support clinical decision-making, and enable precision medicine. Seven studies [6, 22, 35, 41, 64, 65, 72] considered data processing techniques, including analytical processing, data manipulation methods, and data transformation techniques in large-scale research projects. Anonymization, data quality control, configurable open-source architectures, and bioinformatics pipelines and Hypermutation filter, ensured security, reliability, and analytical rigor [6, 22, 35, 41, 64, 65, 72].
Cohort studies relied on data entry validation, consistency checks, and effective provisioning systems to meet CDMS needs [6, 72]. Sixteen studies [5, 14, 22, 23, 28,29,30, 32, 35, 36, 39, 44, 45, 61, 64, 72] identified the importance of data analysis tools, including statistical analyses, search systems, and query analysis frameworks in cohort research. Statistical and computational tools were essential for epidemiological, genomic, and clinical research by enabling harmonization, query analysis, and reproducible results [5, 14, 22, 23, 28,29,30, 32, 35, 36, 39, 44, 45, 61, 64, 72]. Advanced analyses included biomarker identification, integrating multi-omic data and centralized search systems, genome-wide association study, phylogenetics, drug resistance detection, predictive modeling, HIV incidence estimation, cardiovascular risk prediction, and cancer research [22, 23, 28,29,30, 32, 35, 61]. Five studies [4, 28, 30, 42, 68] applied the role of artificial intelligence (AI) workflows and disease subtyping to advanced cohort research and precision medicine. AI workflows used machine learning for disease subtyping and biomarker discovery, with explainable AI models like VESPRE integrated into EHRs to enable personalized treatments [4, 28, 30, 42, 68]. Electronic patient-reported outcomes (ePRO) systems also enhanced patient-doctor relationships by combining self-reported and clinical data in cohort studies [68].
Longitudinal cohort studies tracking
Tracking longitudinal cohort studies enabled continuous monitoring of participants, records changes in health outcomes, and supports robust follow-up strategies. Longitudinal cohort studies tracking was addressed in 15 studies [14, 22, 23, 25, 30, 34, 35, 43, 44, 60, 61, 67, 70, 72, 73]. It is consequential in crises, disasters, chronic diseases, and disease trends, especially among vulnerable populations, where continuous monitoring ensures reliable data collection and aids prevention and treatment decisions [34, 43, 67]. Examples included the Swiss HIV Cohort Study with structured tracking since 1988 and DHRP [22, 60], which repeated PROs assessments at regular intervals [35], a concise, generic measure of self-reported health named EQ-5D pre-/post-op follow-up [61], and long-term surveys [23]. Follow-up statuses were systematically categorized [30], while systems developed for cancer and other diseases improved long-term data quality [44]. Self-reports, ongoing participant interaction, and systematic solutions to manage follow-up loss in conditions like HIV/AIDS, cancer, and cardiovascular diseases strengthen retention and accuracy [14, 25, 70, 73]. Longitudinal tracking also informs global health research, addressing challenges such as child mortality and epidemics [72].
Protection and access control
Protection and access control ensure that the system implements mechanisms to restrict data access to authorized users only, enforce privacy and regulatory compliance, and maintain data integrity. It must also include safeguards to protect patient safety by preventing unauthorized modifications or misuse of clinical data. Patient safety, discussed in five studies [8, 21, 42, 68, 70], was ensured through GDPR-compliant consent management [8], anonymization via trusted systems [21], precise participant selection using CART models [70], and the ethical use of pre-collected samples to reduce risks [42]. Treatment monitoring and response evaluation further improved participant care [68]. Data access control was highlighted in 19 studies [4,5,6, 8, 21,22,23,24, 27, 29, 30, 35, 42, 47, 61, 62, 65, 66, 71], in which encryption, strong authentication, GDPR compliance, and role-based permissions were used to secure sensitive data [4, 6, 8, 27, 30, 61, 62]. Additional measures included pseudonymization and audit trails for transparency [8, 21, 27], secure data sharing across centers [4, 65], and integration of access protocols with EHRs and biobanks for real-time validation, alerts, secure Application Programming Interfaces (APIs), and dual one-time passwords systems [8, 24, 42, 47, 66, 71]. Restricted aggregate models and managed access frameworks provided an added layer of control [23]. These strategies ensure data security, compliance, and ethical management in medical research [4, 8, 24, 29, 42, 47, 65, 66, 71].
Data reporting, visualization, and reports generation
Data reporting, visualization, and report generation are essential for effective communication insights derived from cohort data, providing a clear presentation of complex findings. These requirements facilitate processes including creating visual images, dynamic reports, and data sharing to support decision-making and dissemination of research data. The findings showed that 19 studies [7, 20, 23, 25, 29, 30, 34, 35, 41, 43, 60,61,62, 64,65,66,67,68, 72] addressed reporting, visualization, and data integration tools in cohort studies. Customizable dashboards, automated summarization, and quality control reporting enhance management and monitoring of complex patient data [41, 60, 62, 64, 65]. Centralized systems with user-friendly interfaces supported multi-center and international collaborations, and improved data exchange and health interventions [29, 34, 66]. Real-time monitoring charts aided clinical decisions and patient follow-up [25, 43, 67], and continuous data reporting enabled targeted public health actions [7, 72]. Advanced visualization methods, including CCVPRA (CPPTherapists-DBS system, a tool providing advanced visualization and data modeling capabilities for a system that integrates cardiac surgery and cardiopulmonary rehabilitation data management), business intelligence cubes, and interactive dashboards like MMFP-Tableau, further enhanced data interpretation and cohort analysis [23, 30, 35, 61].
Infrastructure and operations
Infrastructure and operations ensure that the system is supported by reliable and accessible IT infrastructure, enabling seamless user access and system performance. It also includes process management and automation to streamline workflows, reduce manual tasks, and enhance operational efficiency. Twelve studies used centralized, scalable, and modular solutions for imaging [6, 14, 21,22,23, 28, 36, 43, 44, 60, 63, 69], genomic data [36, 63], and multi-site integrity [69]. Overall, cloud-based architectures, APIs, and visualization tools enhanced interoperability, accessibility, and sharing [22, 23, 28, 60]. Web-based and modular systems were noted for integrating biomarkers and supporting diagnosis and treatment [6, 14, 21, 44], with lightweight local systems offering options in resource-limited settings [43]. Process management and automation, discussed in 15 studies [5, 20,21,22, 24, 26, 35, 37, 41, 43, 47, 60, 61, 67, 69], optimized efficiency through structured workflows, real-time monitoring, and automation, ensuring accuracy, compliance, and synchronization with study goals [20, 21, 24, 26, 37, 43, 47, 67, 69]. Tools like XNAT in neuroimaging [41, 64] and Jenkins-based automation, extracted, transformed, and loaded (ETL) scheduling, and real-time analytics enhanced data validation, coordination, and timely clinical decision-making [5, 22, 35, 60, 61].
User support and interaction
User support and interaction focus on enabling intuitive and efficient user interaction with the system, ensuring ease of use and engagement. It also includes provisions for training, collaboration, and ongoing support to assist users and promote effective system adoption and use. Eight studies [21, 22, 35, 37, 43, 60, 65, 68] emphasized tools including automatic reminders, multilingual support, multi-user management, and personalized dashboards, which enhanced adherence to study protocols, facilitated system access, and streamlined communication in large-scale, multi-location cohort studies. User-friendly web interfaces and APIs further supported efficient data entry, retrieval, and interaction between researchers and participants [22, 37, 65, 68]. Training, collaboration, and support were discussed in eight studies [4, 5, 14, 26, 29, 45, 60, 65], focusing on the role of educational programs, collaborative analysis tools, and platforms such as HarmonicSS and the Clinical Development Center (CDC) in facilitating data sharing, integration, and analysis, particularly in public health and cancer research [4, 26, 29, 45, 60, 65]. Collaboration between domestic and international researchers, alongside analyst training and participant sensitization, was identified critical for improving adoption, strengthening engagement, and advancing medical research [5, 14].
Research facilitation
Research facilitation in cohort studies included research proposals and patient-centered approaches, and enhanced data efficiency and quality, as highlighted in four studies [11, 22,23,24]. Transparent and ethical data access through proposal submissions improved data utilization [24]. Incorporating patients’ experiences fostered better communication between researchers and participants and boosted research quality and applicability [38]. Additionally, platforms designed for broad HIV research supported hypothesis generation and collaboration [22, 23].
Non-Functional Requirements (NFRs)
NFRs define criteria for assessing the performance of a system and focus on attributes such as performance and security. Unlike FRs, which define specific behaviors, NFRs impact the overall architecture of the system. The main non-functional requirements for CDMS were categorized into eight groups based on ISO/IEC 25010. These were performance efficiency, compatibility, usability, flexibility, reliability, security, maintainability, and privacy. These requirements are explained below in more detail. Figure 7 illustrates the hierarchical breakdown of NFRs into their respective subcategories.
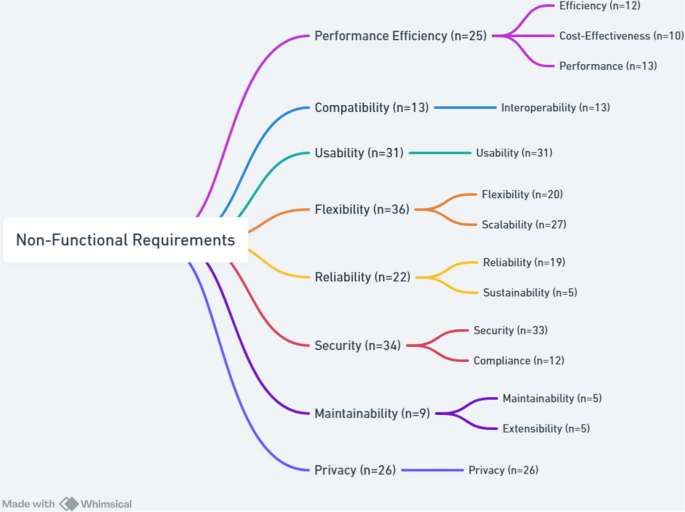
Breakdown of Main Non-Functional Requirements of CDMS by SubcategoriesFootnote
The total count for each main requirement refers to the number of specific requirements that are addressed through one or more of its subcategories. A single article may cover multiple subcategories under the same main requirement, or it may address only one subcategory.
Performance efficiency
Performance Efficiency refers to the extent to which a system effectively executes its intended functions within defined time constraints and throughput levels, while optimizing resource utilization under specified conditions. This characteristic encompasses aspects such as efficiency, cost-effectiveness, and performance. Efficiency, emphasized in 12 studies [7, 22, 26, 28, 31, 36, 41, 42, 47, 69,70,71], could be achieved through electronic systems enabling rapid data collection [47, 69], automated pipelines and distributed frameworks for faster processing [7, 22, 28, 36, 41, 42], optimized data cleaning to enhance quality and cohort identification [26, 31, 70, 71]. Cost-effectiveness, addressed in 10 studies [11, 34,35,36, 39, 42, 60, 62, 70, 72], emphasized using digital platforms like REDCap, VESPRE, and Gulf of Mexico Community Health Observing System (GoM CHOS) for reducing costs while improving efficiency [34, 36, 42, 62, 70]. Systems such as COllaborative open platform E-cohorts (COOP’e-cohort) [11]and low-cost customization approaches [35, 60] further improved value in clinical research, including in resource-limited environments [39, 72]. Performance, reported in 13 studies [4, 22, 24, 26, 28, 32, 36, 42, 43, 60, 61, 65, 71], was strengthened by high-performance computing, containerized pipelines, distributed Elasticsearch, and efficient querying systems [22, 28, 60, 61]. Examples include HarmonicSS executing analyses in less than 30 s, GenomicsDB supporting distributed genetic research [4, 36], and lightweight tools like odk_planner for constrained settings [43]. Optimized workflows for multi-omics [32], HIV/AIDS and acute care [24, 42] further illustrated improvements, though challenges like limited population diversity [26] remain.
Compatibility
Compatibility studies refer to the extent to which a system or component can operate effectively within a shared environment, exchanging and utilizing information with other systems. It primarily includes interoperability, which is the ability to exchange and meaningful use of shared information. Interoperability enables seamless data exchange and integration across systems, enhancing standardization, compatibility, accuracy, and reproducibility. Thirteen studies [6, 14, 22, 28, 34, 35, 60,61,62,63,64,65,66] have examined its role in improving data coordination and management through system integration tools including REDCap, SHIP, Electronic Medical Record (EMR), and MMFP-Tableau [62,63,64]. Studies emphasized supporting FAIR principles via JavaScript object notation (JSON) metadata, Docker containers, and integration with EHRs, wearables, and apps through HL7, Fast healthcare interoperability resources (FHIR), clinical data interchange standards consortium (CDISC), ICD-10, and device APIs [22, 28, 35, 60, 61]. Open-source platforms like Modular Approach to Data Management in Epidemiological Studies (MOSAIC) fostered data harmonization by improving software module compatibility [6, 14, 65]. Standard protocols and scalable methods enhanced data quality, integrity, and long-term interoperability [34, 64,65,66].
Usability
Usability is defined as a system’s ability to facilitate easy and effective interaction. It has been identified as a key NFR in 31 studies within CDMS [5,6,7, 20, 22,23,24,25, 27, 28, 30, 32, 35, 36, 41, 43,44,45, 47, 60,61,62,63,64,65,66, 68, 69, 71,72,73]. Enhancements included user-friendly, web-based, and mobile-accessible interfaces, dashboards, and real-time visualizations to support users with low digital literacy and diverse cultural contexts [22, 23, 27, 28, 30, 35, 36, 60,61,62]. Usability contributes to sustainability and efficient data management by simplifying collection, monitoring, and retrieval [25, 45, 47, 63, 69, 71]. It also facilitates collaboration, data sharing, and harmonization in scalable systems, particularly for neuroimaging and cohort studies [41, 64, 65]. Standard data formats, accessibility guidelines, and reduced researcher workload have improved usability in HIV/AIDS and Alzheimer’s research [5, 24, 66]. For researchers with limited IT expertise, tools emphasize simplicity in cohort studies [6, 20, 32, 68]. Systems like korean renal cell carcinoma (KORCC) and odk_planner demonstrated usability benefits by reducing complexity and ensuring efficient management in clinical, population, and public health research [7, 43, 44, 72, 73].
Flexibility
Flexibility is the extent to which a system can adapt to changing requirements, usage contexts, or environments. It includes scalability, which refers to the system’s ability to adjust its capacity in response to varying workloads. Twenty studies [5, 6, 11, 21, 27, 29,30,31, 34, 35, 37, 39, 41, 42, 47, 60, 62, 63, 65, 68] emphasized the role of flexibility for accommodating diverse research needs and adapting seamlessly to the study requirements and contexts. Systems such as REDCap, ePRO, SHIP, VESPRE, and GoM demonstrated flexibility in harmonizing data, supporting chronic disease management, and coordinating multi-project studies [11, 27, 39, 41, 47, 62, 63, 65, 68]. Flexible protocol updates including surveys, age-specific adaptations, and integration of new data types were also identified as crucial requirements [30, 35, 60]. Scalability was examined in 27 studies [4, 7, 8, 14, 22, 23, 27,28,29, 32, 35,36,37, 39, 41, 45, 47, 60,61,62,63, 65,66,67, 69, 71, 72] and ensured that large datasets, multi-center cohorts, and a large sample size were managed efficiently while maintaining data quality. Scalable strategies included cloud autoscaling, distributed analytical frameworks, horizontal and vertical expansion, integration of new devices, and handling of multi-omics data [14, 22, 23, 28, 32, 35, 36, 60, 61, 63]. Centralized, automated systems enhanced large-scale data coordination, enabling multi-study collaboration and improving overall research efficiency [7, 29, 41, 66, 67, 69, 72].
Reliability
Reliability refers to the degree to which a system, product, or component consistently performs its intended functions under defined conditions over a specified period of time. This characteristic also encompasses sustainability which emphasizes the system’s long-term dependability and stability. Nineteen studies [4, 7, 8, 22, 24, 25, 27, 28, 34, 36, 44, 45, 47, 65, 67, 69,70,71, 73] addressed system reliability through stable cloud hosting, Multi-AZ deployment for fault tolerance, rigorous quality control, and reproducible data processing to strengthen data integrity and reduce errors [8, 22, 28, 36, 47, 65, 69, 70]. Reliability was also supported by interpretable AI models, systematic data cleaning, governance frameworks, and controlled execution environments, ensuring crisis resistance and long-term credibility [4, 24, 27, 34, 67]. Several studies emphasized the role of uptime, intensive monitoring, and structured audits in maintaining data validity, particularly in low-resource and translational research settings [7, 25, 44, 45, 71, 73]. Sustainability was discussed in five studies [4, 20, 25, 29, 30] focused on the long-term viability of CDMS to support ongoing research. Approaches included Platform-as-a-Service (PaaS) models such as HarmonicSS [4], long-term strategies exemplified by IeDEA [25], and system functioning effectively for nearly two decades [30]. Future-proof infrastructures such as california teachers’ study (CTS) and tools like the Toolbox for Research ensure adaptability and efficient expansion, strengthening sustainability in data-driven studies [20, 46].
Security
Security refers to the extent to which a system protects against threats and unauthorized access, ensuring that data and resources are accessible only to users or systems with appropriate authorization. This characteristic includes compliance with relevant regulations and confidentiality, which safeguards sensitive information from exposure or misuse. A total of 33 studies [4,5,6,7,8, 14, 20, 22,23,24, 28,29,30,31, 34, 35, 37, 44, 45, 60,61,62,63,64,65,66,67,68,69, 71,72,73] discussed the integration and implementation of security measures in various CDMS. Multi-layered security requirements included advanced encryption standard (AES) like AES-256 encryption, transport layer security (TLS) protocols, secure APIs (HTTPS), UUIDs, and role-based access control aligned with HIPAA, national institute of standards and technology (NIST), and federal information security modernization act (FISMA) guidelines [22, 23, 28, 30, 35, 60, 61]. Additional protections included firewalls, endpoint security, identity and access management (IAM) policies, encrypted storage, anonymization, pseudonymization, prevention of unauthorized access, and separation of participant identifiers from research data [6, 8, 20, 24, 27, 29, 31, 34, 37, 44, 64,65,66, 71, 73]. Privacy-preserving techniques, encrypted cloud infrastructures, routine audits, daily backups, and secure troubleshooting protocols collectively enhanced system security and minimized breach risks in federated and resource-limited settings [4, 6,7,8, 27, 31, 44, 45, 62, 64, 69, 72]. Compliance was mentioned in 12 studies [14, 20, 30, 31, 35, 42, 61, 63, 64, 66, 67, 71], reinforced security through adherence to Helsinki Declaration, the royal college of pathologists of Australasia (RCPA) external quality assurance programs, GDPR, HIPAA, ISO/IEC standards, Helsinki Declaration, institutional review board (IRB) approvals, and FAIR principles to promote ethical research and responsible data use [14, 30, 31, 35, 42, 61, 63, 64, 66, 67, 71].
Maintainability
Maintainability represents the degree to which a system or product can be efficiently and effectively modified to correct faults, improve performance, or adapt to changes in the environment or requirements. This characteristic includes extensibility, which refers to the ease with which new capabilities can be added without negatively affecting existing functionality. Five studies accentuated the importance of maintainability in cohort systems [14, 22, 36, 60, 65]. Frameworks like GenomicsDB simplified system updates in Spark clusters through enhanced maintainability [36], and communication-enabled IT networks improved medical research by integrating biomarkers [14]. To ensure long-term upkeep, studies recommended version-controlled tools, modular design, and microservices architecture [22, 60]. Extensibility was emphasized in five studies [21, 41, 61, 63, 65] to ensure the rapid adaptability and reusability of systems for emerging research needs. The SHIP project tools and modular neuroimaging data systems demonstrated effective reusability for new diseases [41, 63]. Iterative updates using spiral models, open-source architectures that facilitated harmonization, and reusable software modules like those of the MOSAIC project further strengthened extensibility and long-term maintainability [21, 41, 61, 63, 65].
Privacy
Privacy in CDMS involves a comprehensive framework of legal, technical, and ethical safeguards to protect sensitive personal and health information. Although privacy is a subset of security, it plays a significantly more prominent and independent role in the context of medical research and health-related data, as reflected in 26 studies [4,5,6, 8, 14, 20, 21, 23, 25, 26, 28,29,30,31, 36, 37, 42, 43, 45, 60, 61, 64, 65, 67, 68, 70]. Regulatory compliance is foundational, requiring systems to adhere to national and international laws such as the HIPAA in the U.S.A [23, 28, 29, 36, 42, 60, 65, 70], GDPR in the EU [4, 5, 8, 20, 21, 31], UK Data Protection Act [5], and regional legislations like Germany’s BDSG (Bundesdatenschutzgesetz) [6, 21], the Swedish legal framework [45], national commission on informatics and liberty (CNIL) [68] and the Human Tissue Act in the UK [67]. Many studies obtained approval from IRBs and ethics committees [25, 26, 31, 61, 62, 70], and several systems followed recognized security standards such as ISO/IEC 27001 [5, 8], FISMA, and NIST guidelines [29, 60, 65]. At the system level, role-based and fine-grained access, AES-128/256, TLS/SSL, and infrastructure like Amazon Web Services (AWS) IAM, virtual private networks (VPNs), and private clouds strengthen protection [4, 5, 8, 28,29,30, 42, 43, 45, 60, 65]. Audit trails maintain accountability [28, 30, 45]. Informed consent and eConsent ensure participant autonomy, with withdrawal and GDPR’s “right to be forgotten” supported by tools like gICS [4, 6, 8, 14, 21, 26, 30, 31, 60,61,62, 64]. Data separation and minimization safeguard personally identifiable information (PII) by storing it apart from medical data [6, 8, 14, 20, 21, 26, 30, 31, 37, 65, 70].