In higher education, English teaching is considered a crucial subject, and its teaching quality and assessment effectiveness have always been a focus of attention1,2,3. Traditional methods for evaluating English instruction face numerous challenges, including a narrow assessment approach, unscientific evaluation criteria, and incomplete data, all of which limit the potential to enhance teaching quality. With the advancements in information technology, the integration of big data and artificial intelligence (AI) has introduced new perspectives and methodologies for English teaching evaluation. As a key branch of AI, deep learning (DL) offers powerful data analysis and pattern recognition capabilities, offering robust support for reforming and innovating English teaching assessment4,5,6.
Traditional English teaching assessment relies on teachers’ subjective judgment and standardized tests, which often leads to limited evaluation dimensions and delayed feedback. Manual scoring requires substantial time and fails to capture students’ subtle progress. Standardized testing focuses on outcomes while neglecting the accumulation of process-based data. The introduction of DL and data mining technologies can address these limitations through automated scoring, multidimensional data analysis, and real-time feedback mechanisms. However, current research still lacks in algorithm integration and adaptability of assessment models, which is the primary focus of this study. DL enables personalized learning by recommending resources and activities suited to students’ habits, abilities, and needs. Such personalization is essential for fostering autonomous learning and improving English language competence. Data mining refers to the process of extracting valuable information and knowledge from large datasets, including clustering analysis, association rule mining, classification, and prediction7,8,9. In the context of college English assessment, data mining can be used to analyze student behavior and evaluate teaching quality. This study aims to construct an efficient and equitable assessment framework by integrating DL with data mining technologies to meet the practical needs of large-scale educational settings.
Research gap
Most existing work focuses on the isolated application of data mining techniques, overlooking the collaborative potential of combining architectures like Transformer with Bayesian frameworks to achieve personalized learning. Previous studies usually aggregate student data without analyzing gender differences in learning preferences and skill priorities. As a result, the lack of transparent model architectures prevents educators from auditing the contribution of different functions. This study addresses the gap through interpretable decision rules and aims to fill these deficiencies by using a transformer–Bayesian integrated framework and combining behavioral sequences with multi-source assessment data.
Research objectives
This work aims to advance the reform and innovation of English teaching assessment and achieve personalized English instruction through the application of DL and AI-driven data mining techniques. By analyzing and summarizing the current state of relevant research, this work explores the role of DL in English teaching models and proposes a Bayesian approach to personalized instruction. Simultaneously, utilizing AI data mining techniques, a new English teaching assessment method is introduced to enhance teaching quality and assessment effectiveness.
With the continuous development of data mining and DL technologies, their application prospects in college English teaching evaluation are becoming increasingly broad. This work aims to explore the practical application of these technologies in teaching, and provide new ideas and methods for college English education. The specific research questions include: How can students’ learning behavior data be analyzed to predict their exam scores? Which factors have the most significant impact on the development of students’ English proficiency? Section 1 describes the research background, objectives, and necessity. Section 2 summarizes the current research status of DL and AI data mining in English teaching. Section 3 primarily focuses on exploring English teaching models based on DL, proposing the Bayesian method for personalized English instruction, and introducing an English teaching assessment method based on AI data mining. Section 4 focuses on experimental analysis, including dataset processing and result prediction. Section 5 concludes contributions and limitations, and suggests future research directions. This work successfully applies the Transformer architecture, originally from the field of natural language processing (NLP), to the education sector. This interdisciplinary integration not only expands the application scope of the Transformer architecture but also introduces novel methods for data processing and evaluation in education. By leveraging the powerful feature extraction and sequence modeling capabilities of the Transformer, this approach enables a deeper understanding of students’ learning behaviors, facilitating more accurate personalized teaching assessments.
Literature review
In the field of language education, particularly English teaching, the rapid development of DL and AI technologies has brought the quality of instruction and assessment to the forefront of attention in both academic and practical domains. This section focuses on the application and impact of DL/AI in language education. Vaswani et al. (2017)10 proposed a novel and simple network architecture that was entirely based on the attention mechanism, completely eliminating the need for recursion and convolution. Numerous studies have highlighted the significance of English teaching in higher education. Eke et al. (2021)11 pointed out that English teaching not only enhanced students’ cross-cultural communication skills but also played a crucial role in fostering a global perspective and competitiveness. Similarly, Lu & Vivekananda (2023)12 emphasized the importance of English teaching quality in improving students’ overall competencies and employability. These studies provide a solid theoretical foundation for exploring the application of DL in language education. However, traditional teaching methods have limitations when it comes to assessing students’ English proficiency. To address these limitations, Peng et al. (2022)13 began exploring the application of DL/AI in language education. Their research revealed that by leveraging big data and machine learning algorithms, student proficiency in English could be assessed more accurately, enabling the provision of more personalized teaching strategies. This discovery offers new insights and methods for innovation in language education.
In discussing how DL technology enhances English teaching and supports personalized learning, the focus should be its applications in NLP, learning resource recommendation, and sentiment analysis. DL technology can comprehend and process language information more deeply by mimicking the human brain’s information processing. This capability is crucial for enhancing the quality and efficiency of English teaching. Next, the applications and effectiveness of DL technology in these areas are specifically analyzed. Zhu et al. (2021)14 utilized DL’s NLP techniques to design a system that thoroughly understands and processes students’ language inputs. This system enables more accurate semantic analysis and grammar correction, thereby improving students’ language application skills. Additionally, the system can assess students’ writing in real time and provide targeted suggestions for grammar and vocabulary improvements, fundamentally enhancing students’ writing proficiency. Concurrently, Agüero-Torales et al. (2021)15 proposed using DL recommendation algorithms to analyze students’ learning journeys, preferences, and performance. This method accurately recommends the most suitable learning resources and activities, further achieving the goal of personalized learning. Zhong et al. (2020)16 applied DL to sentiment analysis, and designed a system capable of interpreting students’ emotional feedback on learning materials. This sentiment analysis system enables teachers to adapt their strategies to meet students’ individual needs and quickly identifies learning challenges or areas of interest, facilitating targeted intervention and support. The application of DL technology in English teaching is multifaceted. This not only enhances students’ language proficiency but also provides tailored recommendations for learning resources based on their progress and preferences. Additionally, the sentiment analysis provides teachers with deeper insights into students’ needs, allowing for more customized instruction. These advancements not only elevate the quality of personalized teaching but also equip educators with diverse strategies and methods, enhancing teaching efficiency and precision. As DL technology continues to evolve, it is reasonable to expect an even more significant impact on English education, enriching students’ learning experiences and providing higher-quality educational outcomes.
In modern society, the rapid advancement of big data and AI technology is transforming the educational landscape, especially in the assessment of English teaching in higher education. These innovations have redefined traditional teaching models, introducing new perspectives and methodologies for evaluation. To enhance the quality of education and the effectiveness of assessments, researchers are increasingly integrating these technologies into English teaching evaluation, striving for improved educational outcomes. Dang et al. (2020)17 proposed a DL-based automatic scoring model for English composition, effectively enhancing scoring efficiency and accuracy. Kumar (2020)18 utilized association rule mining techniques to analyze students’ English scores, discovering potential teaching issues and trends. In terms of research methods, researchers have utilized various approaches and technological tools to validate the effectiveness of their research hypotheses and models. For instance, Mostafa and Benabbou (2020)19 conducted experiments comparing traditional grading methods with DL-based grading methods, gaining valuable insights into students’ and teachers’ perceptions and experiences with AI-based teaching assessment. The findings indicated a greater acceptance of advanced teaching assessment methods among both educators and learners.
With the advancement of computer technology and AI, intelligent assessment has made significant progress in evaluating students’ abilities and knowledge levels. Kartika et al. (2023)20 argued that intelligent assessment could diagnose and analyze students’ specific subject knowledge and competencies based on extensive longitudinal learning data, enabling modeling and dynamic analysis of the learning process. Tang et al. (2022)21 mentioned methods such as simulation-based and game-based assessments, which provided students with complete, authentic, and open problem contexts, allowing them to explore and express themselves freely within task scenarios. Maghsudi et al. (2021)22 employed DL technology to develop student models and learning resource recommendation systems, offering personalized learning paths and resources tailored to students’ learning conditions and interests.
These studies demonstrate the tremendous potential and actual effectiveness of big data and AI technologies in English teaching assessment. These technologies not only enhance the efficiency and accuracy of scoring but also facilitate the identification of teaching issues and trends, thereby providing evidence for teaching improvements. Furthermore, comparative experiments with traditional assessment methods enable researchers and educators to intuitively grasp the benefits of AI-driven assessment approaches, fostering innovation and development in educational technology.
Research model
The framework proposed combines the sequence modeling capabilities of the Transformer architecture with Bayesian inference for personalized learning. The Transformer architecture uses a self-attention mechanism to capture temporal dependencies in learning behaviors, modeling the “learning input-performance output” relationship through an encoder-decoder structure. A Monte Carlo dropout approximation is introduced to model uncertainty, and Bayesian posterior distributions are used to integrate multimodal assessment data, enhancing the robustness of predictions.
Personalized english teaching in college based on DL
The central concept of personalized learning is to address the individual differences that arise during the learning process. Each learner possesses distinct characteristics, such as unique learning preferences and specific areas of weakness. Consequently, personalized learning adopts a customized approach, providing tailored learning advice and methods based on each user’s learning context. This individualized method aims not only to help students bridge knowledge gaps but also to cultivate curiosity and confidence in unfamiliar subjects.
In implementing personalized learning, various tools and methods can be employed, such as interactive ability tests, to comprehensively assess learners’ learning processes and gain a clearer understanding of their strengths and weaknesses23,24. Internet-based education platforms provide a convenient space for personalized learning, enabling students to select appropriate resources based on their needs and learning pace. Meanwhile, effective learning strategies are essential in this process. Comprehensive assessments, pre-class quizzes, and post-class quizzes can enhance students’ deep understanding and mastery of knowledge, making personalized learning an efficient and effective educational model.
In applying Bayesian statistics based on DL in education, the fundamental concept is to treat a student’s learning efficiency as a probability distribution that evolves over time25,26,27. By meticulously observing and recording each instance of a student’s learning activity, the system can continuously update the assessment of the student’s learning efficiency, ensuring it aligns more closely with their actual circumstances. This personalized approach to evaluating learning efficiency effectively addresses individual differences among students, enabling more targeted recommendations for learning strategies and resources. According to Bayesian theorem, the posterior distribution of a student’s learning efficiency can be represented as:
$$P\left( {\theta \left| D \right.} \right)=\frac{{P\left( {D\left| \theta \right.} \right) \cdot P\left( \theta \right)}}{{P\left( D \right)}}$$
(1)
\(\theta\) represents the student’s learning efficiency, and D is all observed learning data. \(P\left( {\theta \left| D \right.} \right)\) is the posterior probability of \(\theta\) given data D; \(P\left( {D\left| \theta \right.} \right)\) is the probability (likelihood) of observing data D given learning efficiency \(\theta\); \(P\left( \theta \right)\) is the prior distribution of student learning efficiency, that is, the efficiency before observing any data; \(P\left( D \right)\) is the marginal probability of data D.
In mathematical statistics, the likelihood function is a function of the parameters of a statistical model that expresses the likelihood of those parameters. The likelihood function is crucial for statistical inference, including applications such as maximum likelihood estimation and Fisher information. While the terms “likelihood,” “plausibility,” and “probability” are closely related and all refer to the chance of an event occurring, they have distinct meanings in a statistical context.
Probability is employed to predict the outcomes of future observations given certain parameters are known, while likelihood is utilized to estimate the parameters of interest given certain observed outcomes. Specifically, given the output x, the likelihood function \(L\left( {\theta \left| x \right.} \right)\) about parameter \(\theta\) (numerically) equals the probability of variable \(X=x\) given parameter \(\theta\):
$$L\left( {\theta \left| x \right.} \right)=P\left( {X=x\left| \theta \right.} \right)$$
(2)
To evaluate the likelihood function for parameter \(\theta\), it is numerically equivalent to the conditional probability of observing result X given parameter \(\theta\), which is also known as the posterior probability of X. Generally, a higher value of the likelihood function indicates that parameter \(\theta\) is more plausible given the outcome \(X=x\). Therefore, formally, the likelihood function is a type of conditional probability function, but with a shift in focus: this work is interested in the likelihood value for A taking the parameter \(\theta\).
$$\theta \left\langle { – – } \right\rangle P\left( {B\left| {A=\theta } \right.} \right)$$
(3)
Through interactive guidance, students can personally experience their progress in each English learning session and receive the system’s positive feedback on different learning states. This personalized feedback mechanism enhances students’ understanding of their performance in the course, fostering enthusiasm and confidence in their learning journey.
This work primarily investigates the design of effective guidance strategies to help diverse students complete their coursework more efficiently and address their personalized learning needs. Figure 1 illustrates the comprehensive recommendation strategy for English teaching. The system leverages integrated recommendations and indices to offer content suggestions that align more closely with users’ learning requirements, thereby accelerating the learning process28,29,30. Additionally, it emphasizes comfort zone guidance as a recommendation approach, enabling users to gradually expand their learning comfort zones, which facilitates a smoother growth trajectory. Ultimately, by fostering situational learning interests, the system can gain a holistic understanding of users’ learning needs and provide a more engaging and personalized educational experience. The integrated application of interactive guidance and guidance strategies seeks to stimulate students’ positive attitudes towards learning, enhance their enthusiasm for learning, and ultimately achieve more effective learning outcomes31,32. In the Bayesian framework, determining and updating the prior distribution are key steps. This work employs a statistical analysis method based on historical data to determine the prior distribution and updates it in real-time to accommodate students’ learning progress. This dynamic update mechanism ensures that the model accurately reflects the students’ true learning situation. Whenever new learning data is generated, the posterior distribution is recalculated based on Bayes’ theorem and used as the prior distribution for the next prediction.
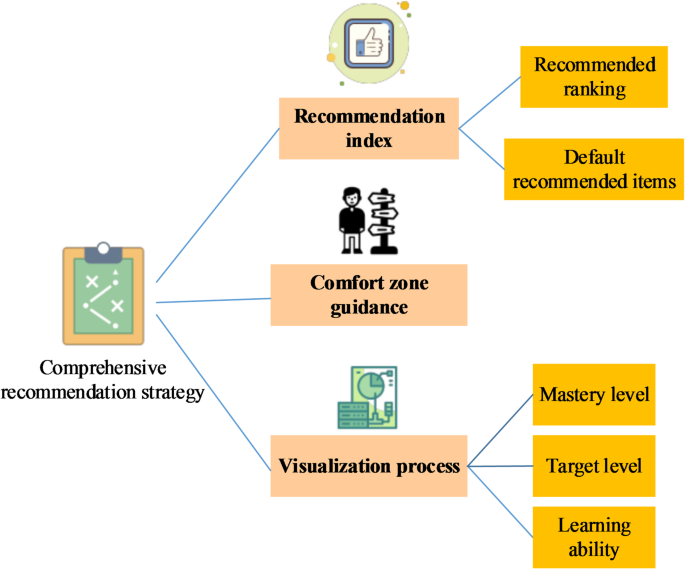
Comprehensive recommendation strategy in English teaching.
Process of AI data mining
Data mining is the process of uncovering hidden information within large datasets using algorithms. This process, often associated with computer science, employs various methods such as statistics, online analytical processing, information retrieval, machine learning, expert systems, and pattern recognition33,34,35. The data mining process includes steps like data preparation, integration, selection, and preprocessing. Its primary goal is to discover knowledge that is relevant, understandable, applicable, and supportive of specific application discovery challenges.
In data mining, the decision tree algorithm is a supervised learning algorithm utilized for classification and regression problems36,37,38. It constructs a decision tree by recursively dividing the dataset into smaller subsets. In this construction, each node represents a test condition for a feature attribute, and each branch corresponds to the outcome of that feature attribute in a specific value range. Each leaf node stores a category or a specific numerical value. This work adopts a feature selection method based on information gain. Specifically, the information gain of each feature relative to the target variable is calculated, and the top N features with the highest information gain are selected as model inputs. During the construction of the decision tree, the Gini index is used as the splitting criterion. A smaller Gini index indicates higher node purity. The decision tree is built by recursively selecting the optimal splitting feature and splitting point. Table 1 shows the advantages of the decision tree method compared to neural networks and support vector machines.
Microsoft’s decision tree algorithm constructs efficient data mining models by carefully designing a series of splits in the tree structure. Figure 2 is the structure of the decision tree model. Whenever the algorithm identifies a significant correlation between a column in the input data and the predictable column, it introduces a new node into the model. The construction process of the Microsoft decision tree begins by treating the entire dataset as a single node. The goal is to partition the sample set based on a particular attribute to purify the class distribution in the subnodes as much as possible. This process relies on selecting the optimal split point to either maximize information gain or minimize Gini impurity, thus achieving effective classification of the samples. T The partitioning stops when all samples belong to the same class or when the preset maximum depth is reached; otherwise, the best split point is chosen for further partitioning. Ultimately, the class of each leaf node is determined based on the principle of “the majority rules.” This process not only helps to understand students’ learning behavior patterns but also provides strong support for personalized teaching. In terms of feature selection, the Microsoft decision tree mainly considers the frequency of feature occurrences and their proximity to the root node. Features that frequently appear and are closer to the root are generally considered to have a greater impact on classification results. Here, different question type scores and exam performance are identified as key factors influencing students’ success in exams, and the position of these features in the decision tree reflects their importance. Moreover, information gain, as one of the feature selection criteria, measures the extent to which a particular attribute enhances classification purity, while Gini impurity is adopted to quantify the probability of elements within a set being misclassified. These two methods work together to ensure that the model effectively captures the key information in the data.
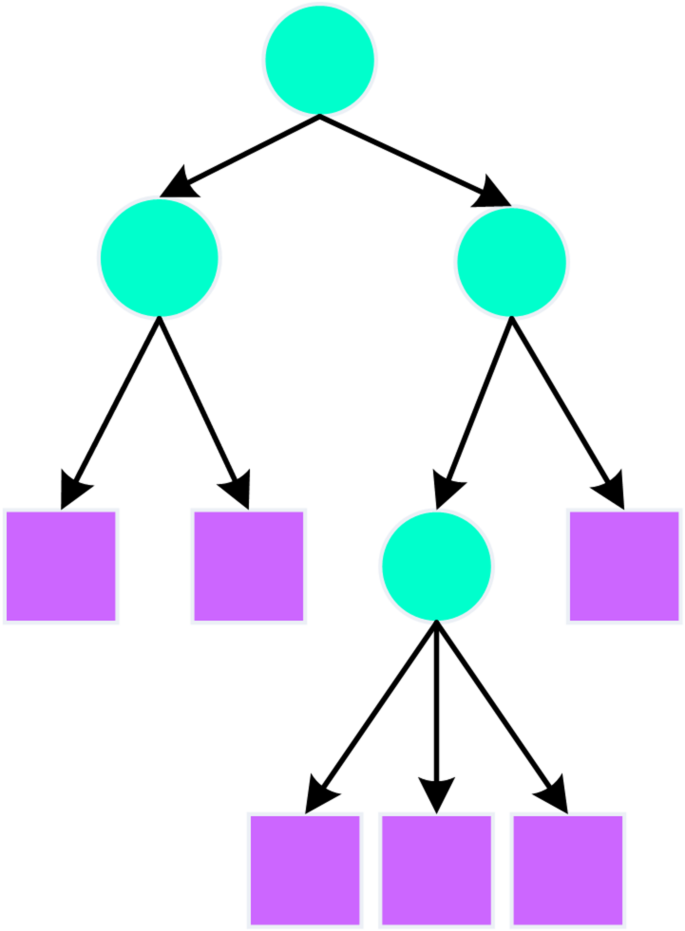
The structure of the decision tree model.
The Microsoft decision tree algorithm uses “feature selection” to determine the most valuable attributes. These techniques help prevent irrelevant attributes from consuming processor time, thus improving performance, and enhancing the quality of analysis. Figure 3 illustrates the decision tree building process. This algorithm is primarily utilized in data mining and machine learning, assisting users in extracting useful information and knowledge from large datasets. By building decision tree models, users can uncover associations and patterns within the data, applying these insights to practical challenges such as fraud detection and credit scoring39,40.
The dataset used in this study contains textual features, numerical features, and categorical labels, displaying characteristics of high-dimensional mixed data. The decision tree algorithm is selected as the preferred method because it requires no complex preprocessing and can directly handle both categorical and continuous variables. The dataset includes 1,500 samples with a moderate number of features, allowing the decision tree to strike a good balance between computational efficiency and model interpretability. In contrast, neural networks, although capable of capturing complex patterns, are not the optimal choice in this context due to their black-box nature and high computational cost.
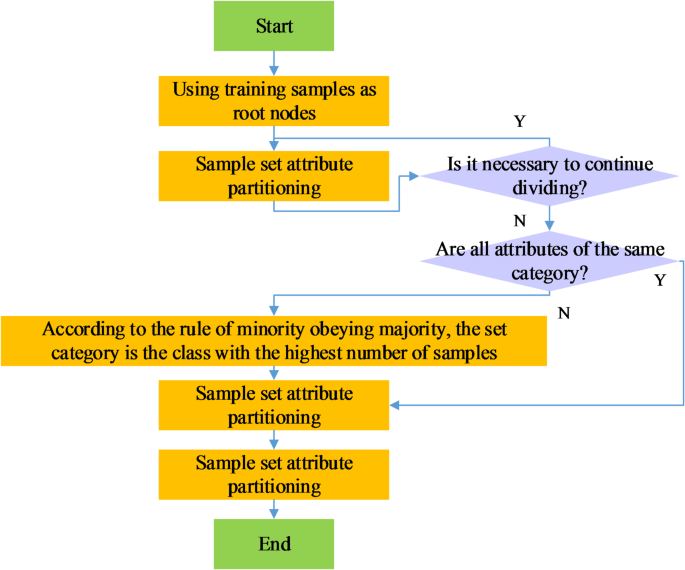
The decision tree building process in Microsoft decision tree algorithm.
In the initial stages of data mining, data preprocessing is a crucial step that encompasses data cleaning, transformation, feature extraction, and more. For textual data such as student assignments and classroom discussions in English teaching evaluations, the Transformer architecture can handle such unstructured data. Through preprocessing techniques like tokenization, stop-word removal, and word embedding, textual data are converted into numerical data that models can process. The Transformer architecture, a significant advancement in recent years in NLP, excels in capturing long-range dependencies within sequences and handling complex textual data, offering fresh insights into English teaching evaluations. This work builds on the foundations of data mining and utilizes the Transformer architecture in English teaching evaluations. It leverages the model’s powerful feature extraction and sequence modeling capabilities to achieve a comprehensive understanding and accurate assessment of students’ English learning experiences. The Transformer architecture employs a multi-head attention mechanism, specifically with 8 attention heads, each having a dimension of 64. This configuration helps the model capture richer information while maintaining computational efficiency. The model is trained using the Adam optimizer, with a learning rate set at 0.001. To prevent overfitting, dropout technology is adopted, with a rate of 0.2. During training, the loss function and accuracy on the validation set are monitored, allowing for adjustments to the learning rate and early stopping strategy as needed.
A multi-layer encoder-decoder model is constructed based on the Transformer architecture. The encoder transforms input textual data into a series of feature vectors, while the decoder generates evaluations of student learning based on these feature vectors. During model construction, parameters and structures are adjusted to meet specific requirements, optimizing performance. The self-attention mechanism, which is central to the Transformer model, captures dependencies between any two positions within the sequence. Attention weight calculation reads:
$$Attention(Q,K,V)=softmax(\frac{{Q{K^T}}}{{\sqrt {{d_k}} }})V$$
(4)
In this context, Q represents the query matrix, K is the key matrix, and V is the value matrix. \({d_k}\) refers to the dimensionality of the key vectors, used to scale the dot product to mitigate the issues of gradient vanishing or exploding.
Based on the evaluation results from the Transformer model, personalized learning recommendations and teaching strategies can be tailored for each student. For instance, students who struggle with grammar could be provided with additional exercises and explanations, while those with weak oral expression skills might receive resources for oral practice and pronunciation correction. By employing personalized assessment strategies, educators can more effectively address students’ learning needs and improve overall teaching effectiveness. In the specific implementation of the Transformer architecture, particular attention is given to the configuration of the attention heads and the optimization of the training process. By carefully configuring the attention heads and adopting effective training strategies, the model is able to efficiently process complex text data and extract valuable information for college English teaching evaluation.
DL path in english teaching
Combining Eric Jensen and LeAnn Nickelsen’s DL path (Fig. 4), teachers should first clarify teaching goals and expectations. They should ensure that students not only master fundamental knowledge and skills in English but also develop cross-cultural awareness and self-directed learning abilities.
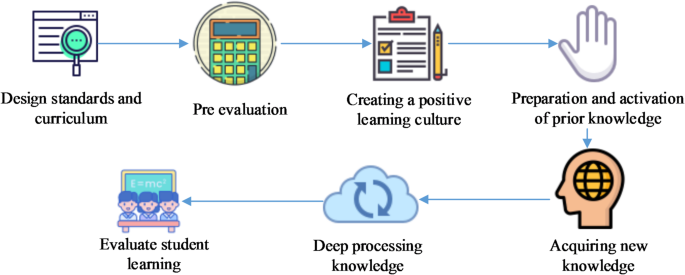
The roadmap for students’ DL in English teaching.
This work develops a DL model tailored to the characteristics of college English teaching, combining the strengths of Bayesian methods and the Transformer architecture to achieve personalized teaching assessments. The model’s input includes multidimensional data such as students’ learning records, assignment completion rates, classroom interaction data, and online learning behaviors. After preprocessing, these data are transformed into feature vectors for model input. In the initial phase, a Bayesian network layer is employed to handle uncertainty. This network infers students’ future learning potential and possible obstacles based on existing learning data and historical performance. Its purpose is to provide a probability-based preliminary assessment for the subsequent Transformer architecture, aiding the model in understanding individual differences among students. Following this, the Transformer architecture processes students’ time series data. Comprising an encoder and a decoder, the encoder extracts features from the input data, while the decoder generates outputs based on these features. In this model, the encoder handles students’ learning records and related data, utilizing a self-attention mechanism to capture complex relationships within the data. The decoder then produces personalized teaching assessment results and predictions based on the encoder’s output. In the pre-assessment stage, teachers must evaluate students’ English proficiency and abilities to establish their starting points and identify areas needing attention. This assessment enables teachers to pinpoint students’ confusions and challenges in English learning, thereby facilitating the development of targeted teaching strategies.
In order to create an environment conducive to DL, teachers should offer a diverse array of learning materials and resources, including textbooks, online resources, and multimedia materials41,42,43. These resources not only broaden students’ knowledge but also enhance their interest and motivation to learn. Additionally, teachers need to create authentic contexts through situational simulations, role-playing, and similar methods, enabling students to connect English with real-life situations and develop cross-cultural communication skills.
In activating students’ prior knowledge, teachers can employ techniques such as questioning, discussion, or providing relevant cases to help students recall and associate previously learned content. This process facilitates the integration of new knowledge with existing understanding, leading to deeper comprehension and meaning44,45,46.
Acquiring new knowledge is a crucial step in DL. Teachers must explain, demonstrate, and guide students in mastering new vocabulary, grammar, and expressions. In the deep processing stage, they should guide students in summarizing and organizing what they have learned to build a cohesive knowledge system. Additionally, teachers should design projects or tasks that allow students to apply English in real-life situations, fostering their innovative thinking and problem-solving skills47. These activities not only aid in the internalization of knowledge but also enhance students’ language proficiency and cross-cultural communication skills. In this study, students are divided into an interactive group (n = 145) and a non-interactive group (n = 145). The former uses an AI-driven real-time feedback system, while the latter relys on traditional instruction. Classroom activities in the interactive group include NLP-based instant essay correction and personalized learning path recommendations. In contrast, the non-interactive group only receives uniform explanations from the teacher.