
TL;DR
Blind Doctor Test: Doctors preferred Google DeepMind’s AI co-clinician to GPT-5.4-thinking-with-search by 63 to 30 across 98 primary-care queries. Physician Gap: Experienced physicians still outperformed all three systems on red-flag recognition and physical-exam guidance during the simulation. Support-Tool Framing: DeepMind positions the AI co-clinician as a physician support tool inside a triadic-care model rather than a doctor replacement.
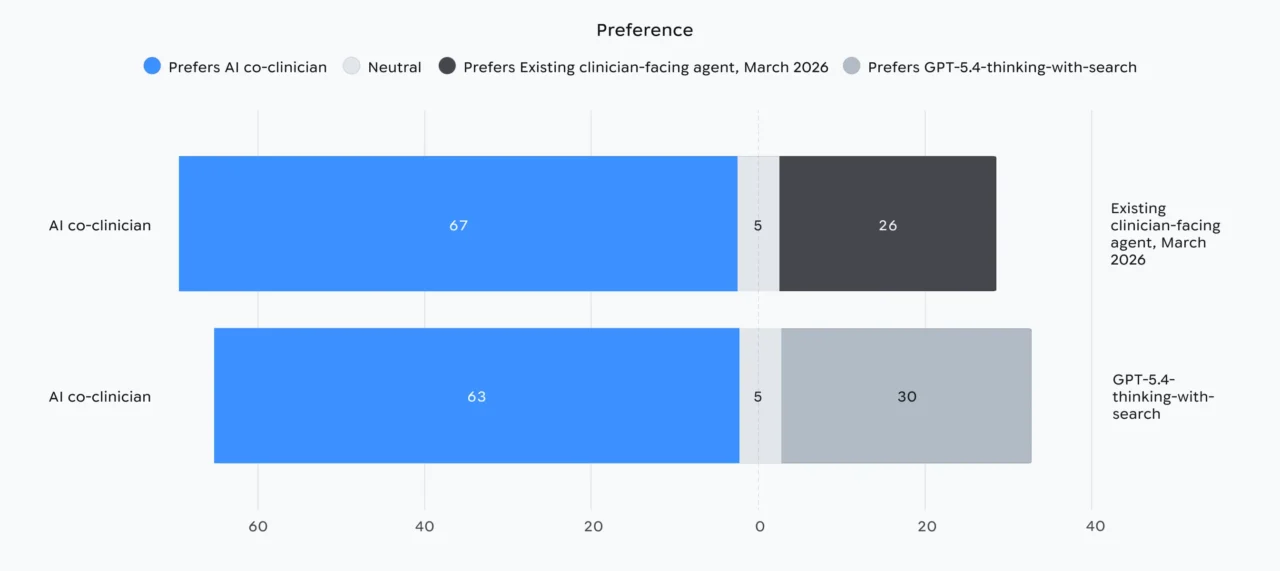
In blind primary-care evaluations of DeepMind’s AI co-clinician published this week, doctors said they preferred Google DeepMind’s experimental AI co-clinician to OpenAI’s GPT-5.4-thinking-with-search by 63 to 30 across 98 realistic queries, and to an existing clinical AI tool by 67 to 26. Across the same 98-query set, experienced human physicians still outperformed all three systems on the two consultation areas DeepMind flags as the largest physician-AI gap: catching red-flag warning signs and steering patients through hands-on physical examinations. DeepMind concludes the AI co-clinician works strongest as a physician support tool rather than a stand-in for a clinician, with red-flag recognition and physical-exam guidance still trailing experienced doctors on the harder triage moments of a primary-care visit. DeepMind’s research note details academic clinical-grade evaluations and safeguards.
Researcher Alan Karthikesalingam framed the blind doctor-test results cautiously, saying “While it’s early days, the promise is clear.” The system runs on what DeepMind calls a triadic-care model, in which AI agents support patients through treatment while a physician retains clinical authority and oversight. Measured wins on routine guidance and structured information-gathering line up alongside a measured deficit on warning-sign recognition, with that warning-sign deficit driving DeepMind’s support-tool framing rather than a doctor-replacement claim and shaping where the system can plausibly run today without a clinician in the loop.
Benchmarks And Blind Evaluation
In the blind primary-care comparison, expert physicians rated answers from three systems without knowing which produced what. Beyond the 67-to-26 and 63-to-30 preference splits, an objective second pass over the same 98 queries logged one serious safety error from the new system. DeepMind logged the single safety-error count alongside the preference splits on the same 98-query set rather than reporting it in isolation, anchoring the safety review in a measurable number that sits next to the doctor-rated wins.
DeepMind’s medication-reasoning gap shifted from a 0.6-point edge on RxQA multiple-choice to a 4.1-point lead on open-ended answers. On the RxQA benchmark, primary-care physicians scored 61.3 percent correct with reference books on hand and 48.3 percent without. The AI co-clinician reached 73.3 percent on RxQA’s multiple-choice questions, edging GPT-5.4-thinking-with-search at 72.7 percent, and pulled further ahead on open-ended medication answers, where dosing context, drug interactions, and patient-specific cautions matter heavily: 95.0 percent for answer quality against 90.9 percent for the OpenAI model.

The RxQA evaluation paper describes academic clinical-grade research. RxQA itself is built from 600 questions on active ingredients, drug interactions, and dosages, drawn from national drug directories in two countries and vetted by licensed pharmacists, which is what gives the comparison weight beyond a synthetic test pool.
Open-ended medication answers showed the largest gap between the two AI systems, because pharmacist-style nuance is harder to fake than multiple-choice pattern matching when dosing, interactions, and patient-specific cautions all have to land in a single free-form reply. Primary-care doctors trailing both AI systems on the multiple-choice slice, even with reference books in front of them, says less about physician competence than about how brittle medication-fact recall has typically been compared with hands-on prescribing in context, where pharmacists and physicians work from chart history, allergy lists, and live patient cues that a benchmark question cannot reproduce.
Telemedicine Simulation And The Physician Gap
A randomized telemedicine simulation run with physicians at Harvard and Stanford put the AI through 20 synthetic clinical scenarios across 120 hypothetical visits, with 10 doctors playing patient actors. Evaluators scored more than 140 aspects of consultation quality across seven areas: triage, history taking, clinical reasoning, communication and counseling, treatment guidance, warning-sign recognition, and physical examinations. That structure mirrors how real telemedicine encounters move from intake through reasoning to follow-up, and it lets reviewers see whether a system is uniformly competent or only good in one slice of the visit.
 Results from a randomized, interface-blinded, crossover simulation study involving 120 hypothetical telemedical encounters performed by real primary care physicians, the AI co-clinician or GPT-realtime. (Source: Google)
Results from a randomized, interface-blinded, crossover simulation study involving 120 hypothetical telemedical encounters performed by real primary care physicians, the AI co-clinician or GPT-realtime. (Source: Google)
Across the scoring grid, the AI co-clinician matched or beat primary-care physicians in 68 of 140 evaluated areas, while OpenAI’s GPT-realtime trailed both the AI co-clinician and human doctors in all seven domains. Experienced physicians, however, still came out ahead overall, with the largest gaps appearing in catching red-flag warning signs and in steering patients through guided physical examinations, parts of a consultation where pattern recognition under uncertainty earns its keep and where missing a single cue can flip a routine encounter into a missed emergency.
Specific scenarios showed where the AI helped in practice. It corrected a patient’s inhaler technique and walked a patient through a shoulder examination that surfaced a probable rotator cuff injury. Routine guidance, structured intake, and step-by-step coaching fall well within reach, but judgment calls that decide whether a complaint is urgent, dangerous, or benign continue to favor a clinician with years of bedside reasoning. Warning-sign performance is the cleanest measure of that distance in the current results, and it is the area DeepMind will need to close before the support-tool framing can credibly stretch into more independent triage roles.
Safety Architecture And Clinical Audits
For patient-facing conversations, the system uses a dual-agent Planner/Talker setup, with a Planner module supervising a Talker agent so responses stay inside safe clinical limits. Splitting the roles keeps the model that speaks to patients narrowly scoped while a separate planner enforces guardrails on what gets said, when to ask a follow-up question, and when escalation to a human clinician is the right move rather than a comforting answer.
Evaluation runs on top of the NOHARM framework, which DeepMind adapted with academic physicians to audit large language models in clinical settings. It builds on DeepMind’s academic clinical-grade research. NOHARM separates errors of commission, the unsafe actions an AI takes during a consultation, from errors of omission, the safety-relevant steps it fails to take. Both categories matter for a triage system, because a model that says nothing actively harmful but skips a warning sign can still send a patient down the wrong path before a doctor sees them, and the omission half of that ledger is exactly where the current physician gap shows up in the simulation results.
Prior Coverage And Peer Sector
DeepMind has put medical AI through physician comparisons before. In 2024, its earlier AMIE chatbot was tested against primary-care physicians in simulated diagnoses, an early line of work that the AI co-clinician now extends with broader specialty coverage, longer multi-turn conversations, and a tighter triadic-care framing built explicitly around physician oversight rather than a head-to-head doctor replacement test.
Other vendors have followed similar paths. Microsoft’s MAI-DxO orchestrator was measured against physicians on diagnostic accuracy in 2025, and a broader peer research line on conversational disease management is built around physician oversight rather than autonomous patient decisions, combining multiple-choice benchmarks with free-form clinical dialogue scoring across triage, reasoning, treatment guidance, and warning-sign recognition. Peer clinical-AI systems lean toward physician-supervised deployment rather than autonomous diagnosis, even where individual products claim accuracy gains over doctors on narrow benchmarks, and the AI co-clinician sits inside that pattern rather than breaking from it.
Outlook
The next concrete benchmark to watch is whether the warning-sign gap narrows on harder, multi-symptom triage cases, with NOHARM omission-error counts on those cases as the supporting indicator that will decide whether the support-tool framing earns a wider clinical brief beyond the current research footprint. Pricing, deployment partners, and the named health systems that would integrate a triadic-care assistant into actual telemedicine workflows all remain unaddressed in DeepMind’s published results, and those decisions, more than the next round of multiple-choice benchmark percentages, will gate whether the AI co-clinician reaches patients beyond a study cohort.
DeepMind’s next milestone, after this release of the AI co-clinician, will be expanding the Harvard- and Stanford-physician simulation beyond its 120 hypothetical visits and 20 synthetic scenarios into harder multi-symptom triage cases where omission errors on red-flag presentations are likely to surface. Until that follow-up data lands, the 68-of-140 evaluated-area parity result from the study stands as the AI co-clinician’s high-water mark against primary-care physicians, and the warning-sign and physical-exam gaps DeepMind flagged in its results remain the open evidence that gates any move beyond support-tool deployment.