
Pendant plusieurs semaines, un vent de panique a soufflé sur la communauté des développeurs utilisant les outils d’Anthropic. Des rapports concordants sur GitHub, X et Reddit décrivaient une dégradation notable des performances, un phénomène baptisé « AI shrinkflation ».
Le modèle semblait moins apte au raisonnement complexe, plus sujet aux répétitions et consommait les crédits d’utilisation à une vitesse anormale. Après une enquête interne, l’entreprise a publié un rapport détaillant les causes, confirmant que le problème ne venait pas du modèle de fond, mais de la « surcouche » logicielle qui l’entoure.
Tous les correctifs ont été déployés et les limites d’utilisation des abonnés ont été réinitialisées.
Quelles sont les trois erreurs techniques qui ont dégradé Claude ?
La dégradation perçue de Claude Code provient de trois incidents techniques distincts qui, combinés, ont créé une impression de régression généralisée.
La réponse directe est donc simple : il s’agissait d’un effet domino malheureux. Le premier problème, initié le 4 mars, fut de réduire l’effort de raisonnement par défaut de « élevé » à « moyen » pour diminuer la latence.
L’intention était bonne, mais le résultat fut un modèle perçu comme nettement moins intelligent.
Le deuxième coupable était un bug critique dans une optimisation du cache, déployée le 26 mars. Au lieu de purger l’historique de raisonnement après une heure d’inactivité, une erreur de code l’effaçait à chaque nouvelle interaction.
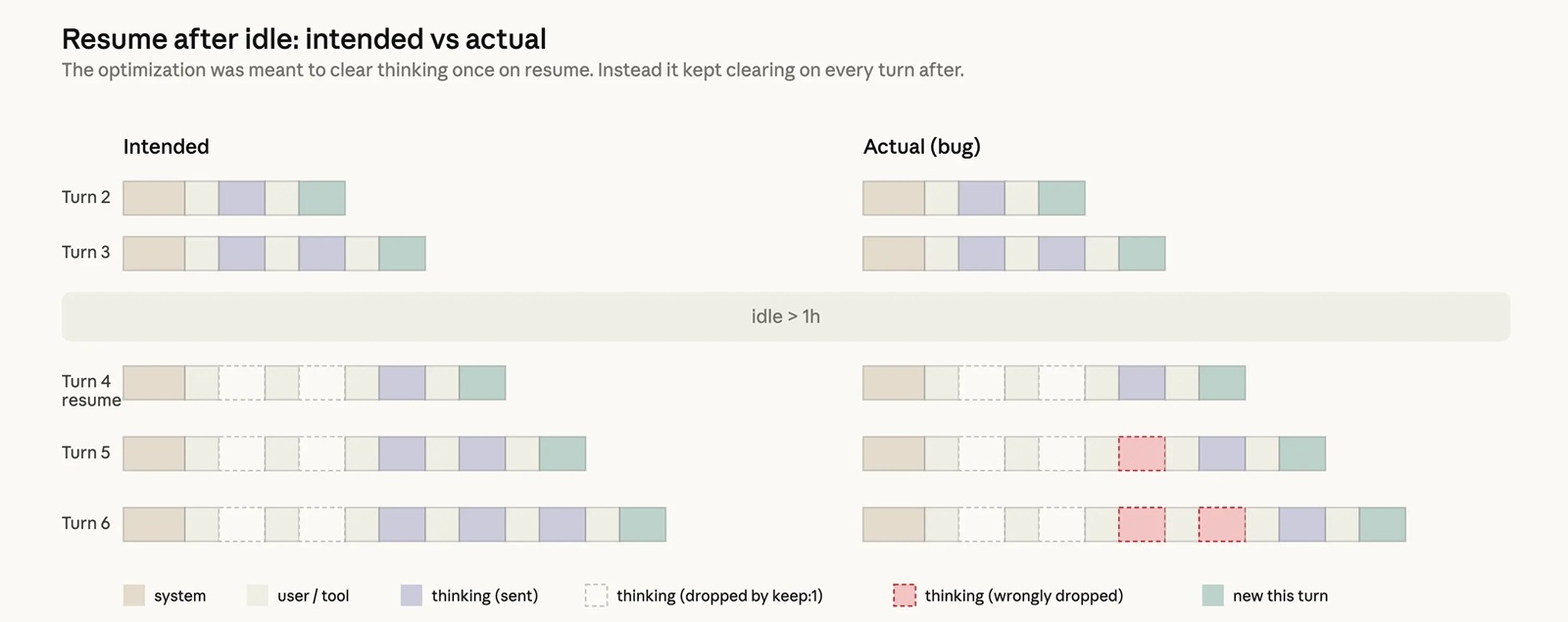
Conséquence : Claude perdait sa mémoire à court terme, devenait répétitif et oubliait le contexte. Enfin, le 16 avril, une nouvelle instruction système visant à réduire la verbosité du modèle a eu un effet pervers, provoquant une chute de 3% de la qualité sur les tâches de codage.
Pourquoi les utilisateurs ont-ils cru à une « AI shrinkflation » ?
Les utilisateurs ont parlé d’« AI shrinkflation » car les symptômes combinés mimaient parfaitement une baisse intentionnelle de qualité pour économiser des ressources.
La réduction de l’effort de raisonnement donnait l’impression que Claude choisissait des solutions plus « paresseuses ». Le bug de cache, lui, se manifestait par une perte de contexte flagrante, forçant les utilisateurs à répéter leurs instructions et gaspillant leurs crédits d’utilisation. Ces problèmes de qualité ont alimenté la méfiance.

Cette cascade de pépins a été validée par des analyses externes, comme celle de Stella Laurenzo (AMD), qui a documenté une chute de la profondeur de raisonnement, et des benchmarks tiers qui ont vu le classement de Claude dégringoler.
L’effet cumulé de ces erreurs, touchant différents groupes d’utilisateurs à des moments différents, a rendu le diagnostic initial difficile, laissant planer le doute sur une possible tentative de réduire les performances du modèle pour gérer une demande explosive.
Comment Anthropic compte-t-il restaurer la confiance ?
Pour regagner la confiance de sa communauté, Anthropic a déployé un plan d’action en plusieurs points. La première mesure, immédiate et symbolique, a été de réinitialiser les limites d’utilisation de tous les abonnés en guise de compensation pour les désagréments et la consommation excessive de tokens.
Mais le plus important se situe dans la refonte des processus de contrôle qualité pour éviter que de tels incidents ne se reproduisent. Concrètement, l’entreprise va renforcer son programme de « dogfooding » (l’utilisation de ses propres produits en interne), obligeant davantage d’employés à utiliser les versions publiques exactes de Claude.
De plus, chaque modification du prompt système devra désormais passer une batterie de tests d’évaluation beaucoup plus large et spécifique à chaque modèle. Enfin, Anthropic s’engage à plus de transparence via un nouveau compte X, @ClaudeDevs, pour communiquer ouvertement sur les décisions produits.
Ce fiasco révèle-t-il une crise plus profonde de l’IA ?
Cet incident met en lumière une réalité souvent masquée par le discours marketing : la performance d’une intelligence artificielle de pointe ne dépend pas seulement de son modèle de base.
Elle repose sur un échafaudage complexe d’outils, de caches et d’instructions système. Quand cet échafaudage se grippe, même le plus brillant des modèles peut paraître défaillant. C’est la face cachée de l’iceberg, révélant une fragilité inhérente aux systèmes d’IA en production.
Plus largement, cette affaire est symptomatique de la pression immense exercée par la pénurie de puissance de calcul (le « compute crunch ») sur toute l’industrie. La tentative d’Anthropic de réduire la latence n’était pas anodine ; elle répond à un besoin vital d’optimiser des ressources GPU extrêmement coûteuses et rares.
Cette course à l’optimisation à tout prix, partagée par OpenAI et d’autres, crée un risque permanent de sacrifier la qualité sur l’autel de l’efficacité et de forcer des arbitrages à manier avec précaution sous peine d’un violent retour de flammes.