-
Apple probiert bei Video-KI einen anderen Weg
Während das Management von Apples KI-Abteilung gerade umgebaut wird, haben Forscher aus dem Team ein neues Video-KI-Modell veröffentlicht, das zumindest in der Fachwelt Aufsehen erregt. STARFlow-V verlässt nämlich den ausgetretenen Pfad der Diffusionsmodelle, die sehr weit verbreitet sind. Stattdessen nutzen die Forscher sogenannte Normalizing Flows – eine Technologie, die bei der Videogenerierung bislang kaum eine Rolle spielte.
Weiterlesen nach der Anzeige
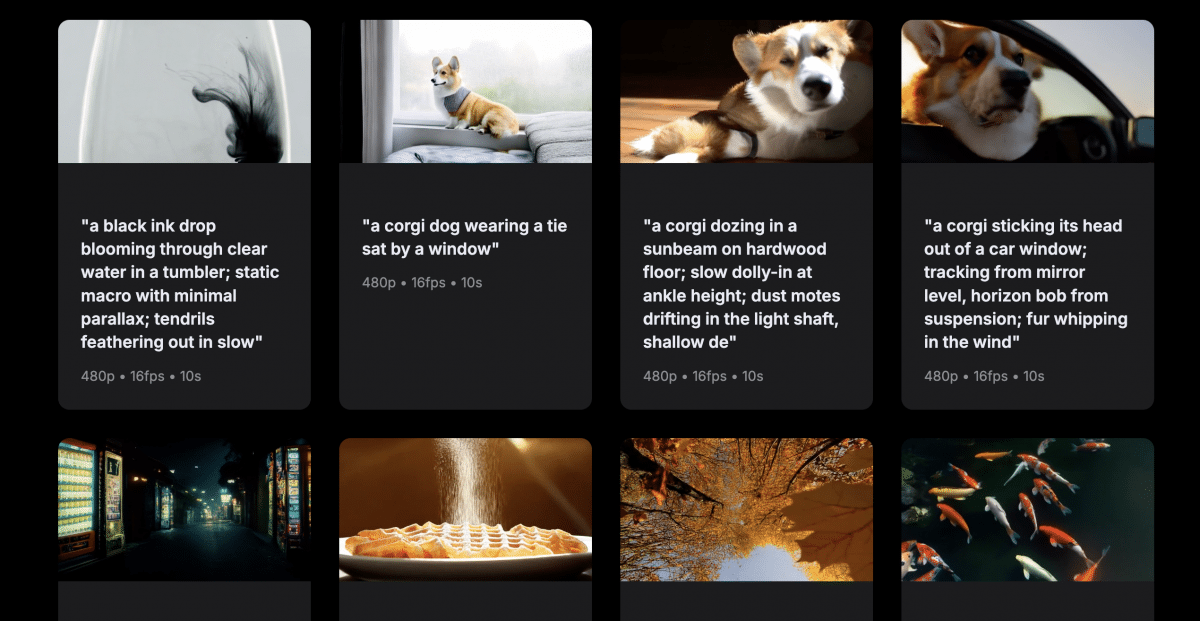
Wer sich die erzeugten Beispiele auf der Projektseite bei Github anschaut, erkennt recht schnell, was STARFlow-V von vergleichbaren KI-Modellen unterscheidet: Das Modell erzeugt die kurzen Videos deutlich realitätsgetreuer und näher an den Anforderungen, die im Prompt gestellt wurden. Während es bei den anderen unerklärlich blinkt, auffallend unrealistisch aussieht oder typische KI-Effekte wie Verzerrungen zu sehen sind, liefert das Apple-Modell solide Qualität. Zwar haben die Videos nur eine Auflösung von 480p, aber Apple geht es anscheinend hier vor allem darum, die Machbarkeit unter Beweis zu stellen, weniger ein alltagstaugliches Modell abzuliefern.
Was das Modell kann
Das 7 Milliarden Parameter große Modell kann Videos aus Textbeschreibungen generieren, Standbilder zu Videos erweitern und vorhandene Videos bearbeiten. Die Forscher haben STARFlow-V auf 70 Millionen Text-Video-Paaren und zusätzlich 400 Millionen Text-Bild-Paaren trainiert. Das Modell erzeugt Videos mit 480p-Auflösung bei 16 Bildern pro Sekunde und einer Länge von bis zu 5 Sekunden pro Segment.
Längere Videos entstehen durch schrittweise Verlängerung: Das Ende eines 5-Sekunden-Segments dient als Ausgangspunkt für das nächste. Auf der Projektseite zeigt Apple Beispiele von bis zu 30 Sekunden Länge. Genau hier zeigt sich die Stärke der ungewohnten Architektur. Denn im Vergleich zu Diffusionsmodellen sind Videos, die mit Normalizing Flows erstellt werden, mathematisch umkehrbar. Das Modell kann so die Wahrscheinlichkeit eines generierten Videos exakt berechnen, benötigt keinen separaten Encoder für Eingabebilder und trainiert direkt von Ende zu Ende.
In zeitlicher Reihenfolge berechnet
Weiterlesen nach der Anzeige
Ein weiterer Unterschied: STARFlow-V generiert Videos streng autoregressiv – also Bild für Bild in zeitlicher Reihenfolge, sodass spätere Frames frühere nicht beeinflussen können. Standard-Diffusionsmodelle entrauschen dagegen oft alle Frames parallel.
Die Forscher haben dem Modell zudem eine „Global-Local-Architektur“ verpasst: Grobe zeitliche Zusammenhänge über mehrere Sekunden werden in einem kompakten globalen Raum verarbeitet, während feine Details innerhalb einzelner Frames lokal behandelt werden. Das soll verhindern, dass sich kleine Fehler über längere Sequenzen aufschaukeln und ein Eigenleben entwickeln.
Für die Beschleunigung setzt STARFlow-V auf eine „video-aware Jacobi-Iteration“: Statt jeden Wert einzeln nacheinander zu berechnen, werden mehrere Blöcke parallel verarbeitet. Das erste Frame eines neuen Segments wird dabei aus dem letzten Frame des vorherigen heraus entwickelt. Laut Apple erreicht das System so eine deutliche Beschleunigung gegenüber Standard-Autoregression.
Oktopus entwischt aus dem Glas
In Benchmarks auf VBench erreicht STARFlow-V Werte, die mit aktuellen Diffusionsmodellen mithalten können – allerdings noch deutlich hinter kommerziellen Systemen wie Veo 3 von Google oder Gen-3 von Runway zurückliegen.
Aber auch bei Apples Modell geht mal etwas schief: Der Oktopus im Glas läuft einfach durch die Wand und ein Hamster läuft im durchsichtigen Hamsterrad, als wenn er nicht von dieser Welt kommt. Die Inferenzgeschwindigkeit liegt trotz Optimierungen noch weit von Echtzeit entfernt.
Was sind Apples Pläne?
Im Ungefähren bleibt auch, was Apple selbst mit dem Modell vielleicht anstellen möchte: Denkbar wäre etwa, dass es aufgrund der geringen Größe lokal auf Geräten eingesetzt wird. Auch die Verwendung als Weltmodell für Virtual- oder Augmented-Reality wäre vorstellbar. Und schließlich könnte es auch für Apples angebliche Ambitionen in der Robotik von Nutzen sein.
Interessierte können den Code auf GitHub einsehen. Dort ist auch ein Paper zum Modell verfügbar.
(mki)
Dieser Link ist leider nicht mehr gültig.
Links zu verschenkten Artikeln werden ungültig,
wenn diese älter als 7 Tage sind oder zu oft aufgerufen wurden.
Sie benötigen ein heise+ Paket, um diesen Artikel zu lesen. Jetzt eine Woche unverbindlich testen – ohne Verpflichtung!