En las películas clásicas de ciencia ficción, la IA a menudo se representaba como imponentes sistemas informáticos o servidores masivos. Hoy en día, es una tecnología cotidiana, accesible al instante en los dispositivos que las personas sostienen en sus manos. Samsung Electronics está expandiendo el uso de IA en el dispositivo (on-device AI) a través de productos como smartphones y electrodomésticos, permitiendo que la IA se ejecute localmente sin servidores externos ni la nube para experiencias más rápidas y seguras.
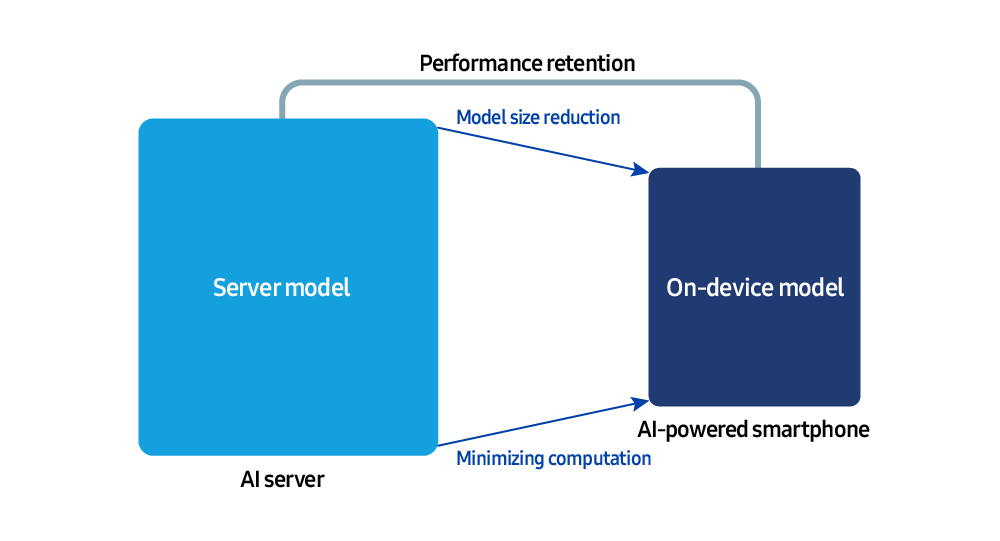
A diferencia de los sistemas basados en servidor, los entornos en el dispositivo operan bajo estrictas restricciones de memoria y computación. Como resultado, reducir el tamaño del modelo de IA y maximizar la eficiencia del tiempo de ejecución son esenciales. Para abordar este desafío, el Centro de IA de Samsung Research está liderando el trabajo en tecnologías centrales, desde la compresión de modelos y la optimización de software en tiempo de ejecución hasta el desarrollo de nuevas arquitecturas.
Samsung Newsroom se sentó con el Dr. MyungJoo Ham, Master en el AI Center, Samsung Research, para discutir el futuro de la IA en el dispositivo y las tecnologías de optimización que la hacen posible.

El Primer Paso Hacia la IA en el Dispositivo
En el corazón de la IA generativa —que interpreta el lenguaje del usuario y produce respuestas naturales— se encuentran los grandes modelos de lenguaje (Large Language Models – LLMs). El primer paso para habilitar la IA en el dispositivo es comprimir y optimizar estos modelos masivos para que se ejecuten sin problemas en dispositivos como smartphones.
“Ejecutar un modelo altamente avanzado que realiza miles de millones de cálculos directamente en un smartphone o laptop agotaría rápidamente la batería, aumentaría el calor y ralentizaría los tiempos de respuesta, degradando notablemente la experiencia del usuario”, dijo el Dr. Ham. “La tecnología de compresión de modelos surgió para abordar estos problemas”.
Los LLMs realizan cálculos utilizando representaciones numéricas extremadamente complejas. La compresión de modelos simplifica estos valores en formatos enteros más eficientes a través de un proceso llamado cuantificación. “Es como comprimir una foto de alta resolución para que el tamaño del archivo se reduzca, pero la calidad visual permanezca casi igual”, explicó. “Por ejemplo, convertir cálculos de punto flotante de 32 bits a enteros de 8 bits o incluso 4 bits reduce significativamente el uso de memoria y la carga computacional, acelerando los tiempos de respuesta”.
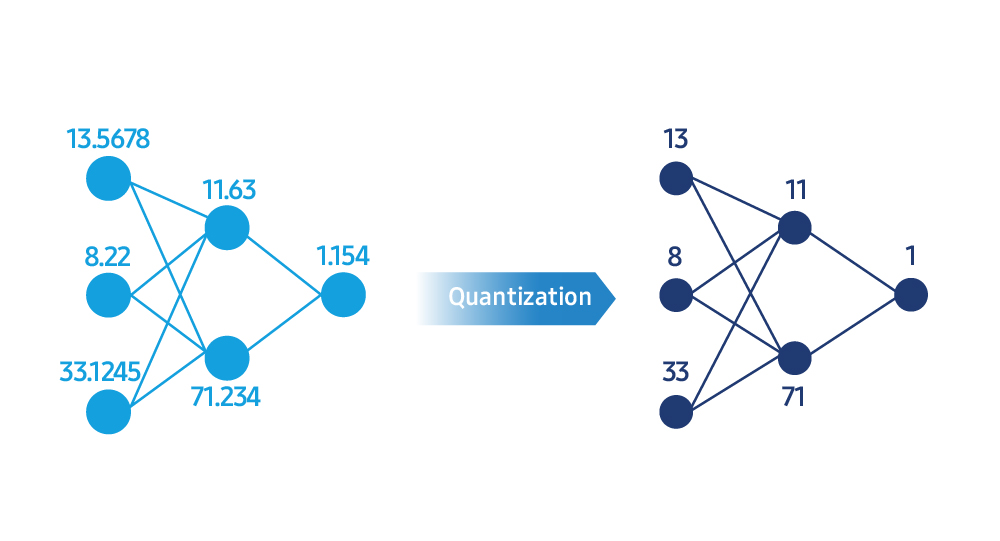
Una caída en la precisión numérica durante la cuantificación puede reducir la precisión general de un modelo. Para equilibrar la velocidad y la calidad del modelo, Samsung Research está desarrollando algoritmos y herramientas que miden y calibran de cerca el rendimiento después de la compresión.
“El objetivo de la compresión de modelos no es solo hacer que el modelo sea más pequeño, sino mantenerlo rápido y preciso”, dijo el Dr. Ham. “Utilizando algoritmos de optimización, analizamos la función de pérdida del modelo durante la compresión y lo reentrenamos hasta que sus salidas se mantengan cerca de las originales, suavizando las áreas con grandes errores. Debido a que cada peso del modelo tiene un nivel diferente de importancia, preservamos los pesos críticos con mayor precisión mientras comprimimos los menos importantes de manera más agresiva. Este enfoque maximiza la eficiencia sin comprometer la precisión”.
Además de desarrollar tecnología de compresión de modelos en la etapa de prototipo, Samsung Research la adapta y comercializa para productos del mundo real como smartphones y electrodomésticos. “Debido a que cada modelo de dispositivo tiene su propia arquitectura de memoria y perfil de computación, un enfoque general no puede ofrecer un rendimiento de IA a nivel de nube”, dijo. “A través de la investigación impulsada por productos, estamos diseñando nuestros propios algoritmos de compresión para mejorar las experiencias de IA que los usuarios pueden sentir directamente en sus manos”.
El Motor Oculto que Impulsa el Rendimiento de la IA
Incluso con un modelo bien comprimido, la experiencia del usuario depende en última instancia de cómo se ejecuta en el dispositivo. Samsung Research está desarrollando un motor de tiempo de ejecución de IA (AI runtime engine) que optimiza cómo se utilizan la memoria y los recursos de computación de un dispositivo durante la ejecución.
“El tiempo de ejecución de IA es esencialmente la unidad de control del motor del modelo”, dijo el Dr. Ham. “Cuando un modelo se ejecuta en múltiples procesadores, como la unidad central de procesamiento (CPU), la unidad de procesamiento de gráficos (GPU) y la unidad de procesamiento neuronal (NPU), el tiempo de ejecución asigna automáticamente cada operación al chip óptimo y minimiza el acceso a la memoria para aumentar el rendimiento general de la IA”.
El tiempo de ejecución de IA también permite que modelos más grandes y sofisticados se ejecuten a la misma velocidad en el mismo dispositivo. Esto no solo reduce la latencia de respuesta, sino que también mejora la calidad general de la IA, ofreciendo resultados más precisos, conversaciones más fluidas y un procesamiento de imágenes más refinado.
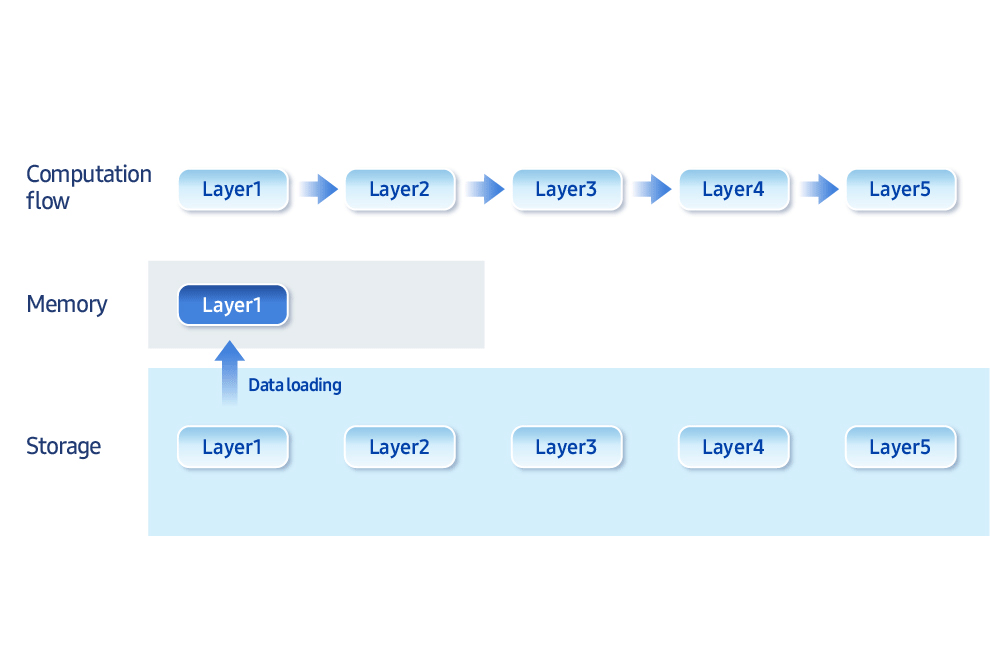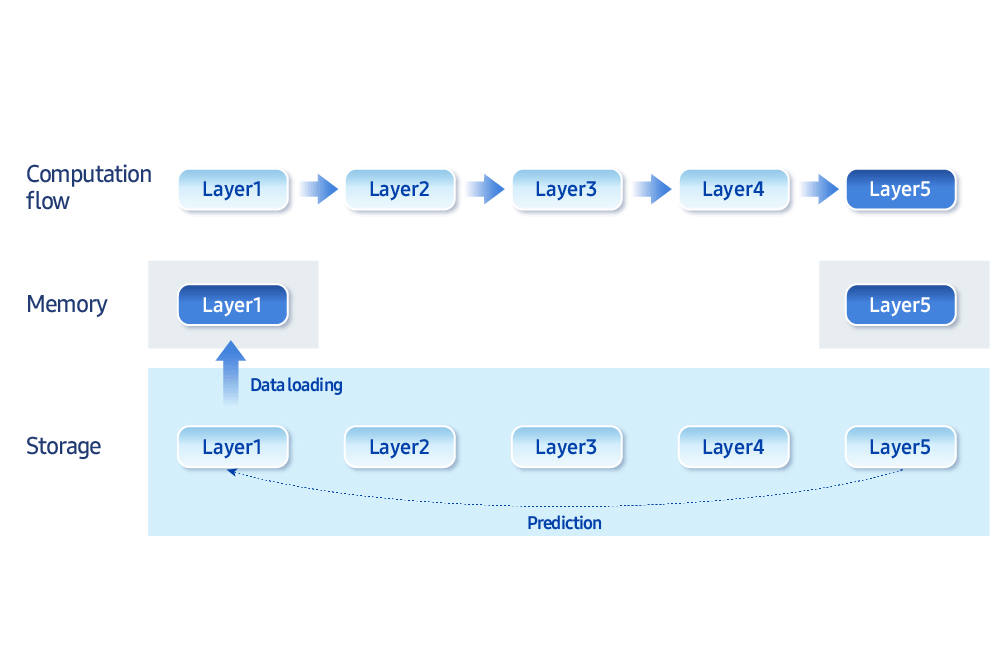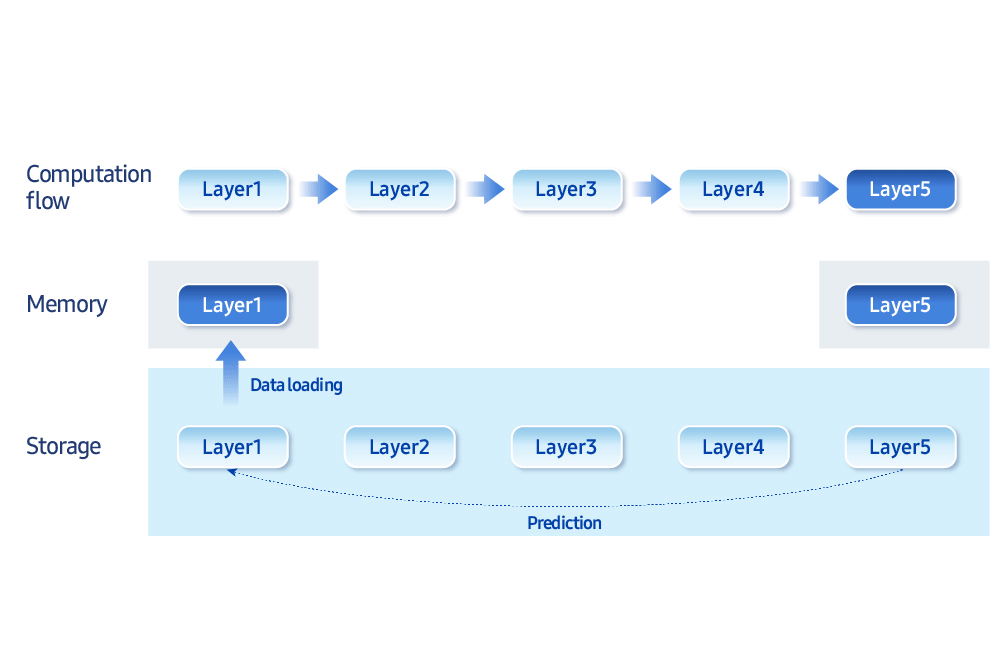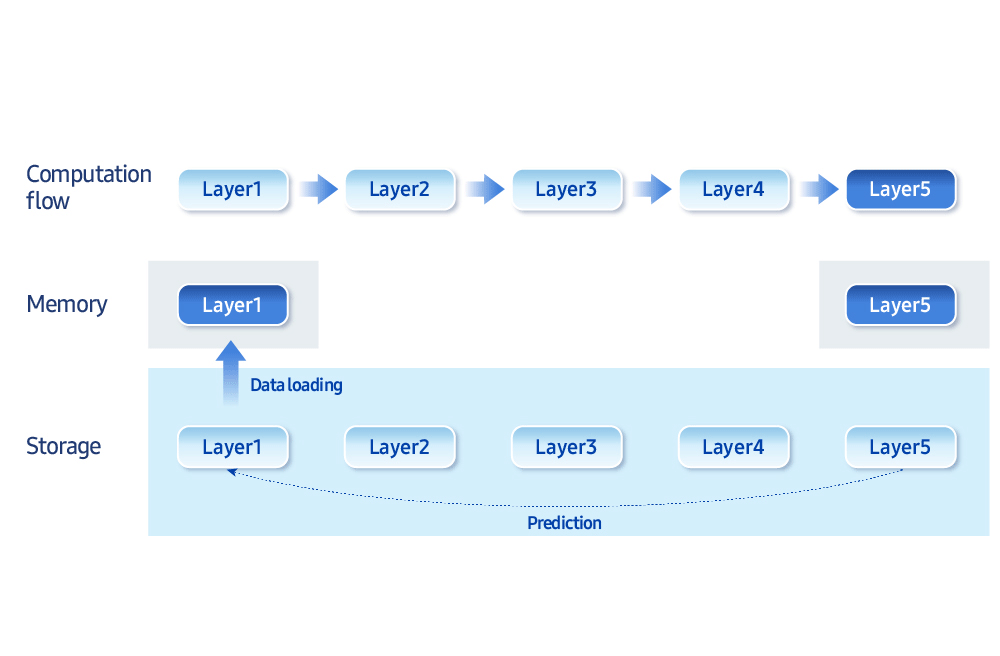
“Los mayores cuellos de botella en la IA en el dispositivo son el ancho de banda de la memoria y la velocidad de acceso al almacenamiento”, dijo. “Estamos desarrollando técnicas de optimización que equilibran inteligentemente la memoria y la computación”. Por ejemplo, cargar solo los datos necesarios en un momento dado, en lugar de mantener todo en la memoria, mejora la eficiencia. “Samsung Research ahora tiene la capacidad de ejecutar un modelo generativo de 30 mil millones de parámetros —típicamente de más de 16 GB de tamaño— en menos de 3 GB de memoria”, agregó.
La Próxima Generación de Arquitecturas de Modelos de IA
La investigación sobre arquitecturas de modelos de IA, los planos fundamentales de los sistemas de IA, también está muy avanzada.
“Debido a que los entornos en el dispositivo tienen memoria y recursos de computación limitados, necesitamos rediseñar las estructuras de los modelos para que se ejecuten de manera eficiente en el hardware”, dijo el Dr. Ham. “Nuestra investigación de arquitectura se centra en la creación de modelos que maximicen la eficiencia del hardware”. En resumen, el objetivo es construir arquitecturas amigables con el dispositivo desde cero para garantizar que el modelo y el hardware del dispositivo trabajen en armonía desde el principio.
Entrenar LLMs requiere mucho tiempo y costo, y una estructura de modelo mal diseñada puede elevar esos costos aún más. Para minimizar las ineficiencias, Samsung Research evalúa el rendimiento del hardware con anticipación y diseña arquitecturas optimizadas antes de que comience el entrenamiento. “En la era de la IA en el dispositivo, la clave de la ventaja competitiva es cuánta eficiencia se puede extraer de los mismos recursos de hardware”, dijo. “Nuestro objetivo es alcanzar el nivel más alto de inteligencia dentro del chip más pequeño posible: esa es la dirección técnica que estamos siguiendo”.
Hoy en día, la mayoría de los LLMs se basan en la arquitectura transformer. Los transformers analizan una oración completa a la vez para determinar las relaciones entre las palabras, un método que sobresale en la comprensión del contexto, pero tiene una limitación clave: las demandas computacionales aumentan drásticamente a medida que las oraciones se vuelven más largas. “Estamos explorando una amplia gama de enfoques para superar estas restricciones, evaluando cada uno en función de cuán eficientemente puede operar en entornos de dispositivos reales”, explicó el Dr. Ham. “Estamos enfocados no solo en mejorar los métodos existentes, sino en desarrollar la próxima generación de arquitecturas construidas sobre metodologías completamente nuevas”.
El Camino a Seguir para la IA en el Dispositivo
¿Cuál es el desafío más crítico para el futuro de la IA en el dispositivo? “Lograr un rendimiento a nivel de nube directamente en el dispositivo”, dijo el Dr. Ham. Para hacer esto posible, la optimización del modelo y la eficiencia del hardware trabajan en estrecha colaboración para ofrecer IA rápida y precisa, incluso sin una conexión de red. “Mejorar la velocidad, la precisión y la eficiencia energética al mismo tiempo será aún más importante”, agregó.

Los avances en la IA en el dispositivo están permitiendo a los usuarios disfrutar de experiencias de IA rápidas, seguras y altamente personalizadas, en cualquier momento y lugar. “La IA mejorará en el aprendizaje en tiempo real en el dispositivo y en la adaptación al entorno de cada usuario”, dijo el Dr. Ham. “El futuro radica en ofrecer servicios naturales e individualizados al mismo tiempo que se salvaguarda la privacidad de los datos”.
Samsung está ampliando los límites para ofrecer experiencias más avanzadas impulsadas por la IA en el dispositivo optimizada. A través de estos esfuerzos, la compañía tiene como objetivo proporcionar experiencias de usuario aún más notables y fluidas.