
The OpenDeID v2 corpus
To evaluate the performance of various machine learning methods and hybrid approaches that combine machine learning and rule- or pattern-based methods developed by participants in the SREDH/AI CUP 2023 deidentification competition, the OpenDeID v1 corpus32,33, which was originally sourced from the Health Science Alliance (HSA) biobank of the Lowy Cancer Research Center of the University of New South Wales, Australia34, was extended with an additional 1144 pathology reports curated from the HSA biobank, resulting in 3244 reports (referred to as the OpenDeID v2 corpus). The dataset was divided into three sets: training (1734 reports), validation (560 reports), and testing (950 reports) for the competition, respectively.
The dataset includes six main SHI categories: NAME, LOCATION, AGE, DATE, CONTACT, and ID. Except for AGE, each category has subcategories, as shown in Fig. 2 and Supplementary Table 1. All date annotations in the OpenDeId v2 corpus were subdivided into the following subcategories: DATE, TIME, DURATION, and SET. Each annotation was assigned a normalized value according to the ISO 8601 standard to ensure temporal integrity. The updated guidelines and detailed annotation procedures are available elsewhere25,35. A more detailed statistical summary of the compiled corpus is provided in Supplementary Table 2.
Fig. 2: Overview of the OpenDeId v1 and v2 corpora.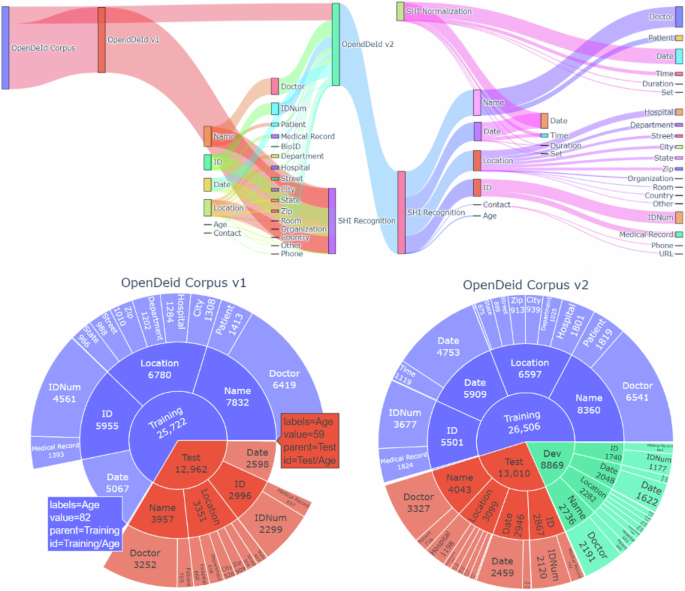
The figure provides an overview of the OpenDeId v1 and the v2 corpora. The numerical values displayed in the sunburst graph indicate the number of annotations in each category.
In the following subsections, we present the ability of the original Pythia model suite26 to address two subtasks, wherein the context is augmented with a few examples. We then demonstrated the results of fine-tuning the same models without applying sophisticated postprocessing rules proposed by the participants to establish baselines and better understand the effectiveness of the participants’ approaches.
In-context learning performance
The first analysis assessed the few-shot learning capabilities of Pythia models across different scales. Unlike our previous study36, which relied on the zero-shot ICL of ChatGPT, we used the k-nearest neighbor (kNN)-augmented in-context example selection approach37 to select the five closest training instances as in-context examples for few-shot ICLs in the Pythia scaling suite.
Figure 3 presents the results, covering models of varying sizes: 70 M (million), 160 M, 410 M, 1 B (billion), 1.4 B, 2.8 B, 6.9 B, and 12 B parameters. The results indicate that pretrained Pythia models with more than 1 B parameters performed comparably to the average performance of all submissions for Subtask 1 in the SREDH/AI CUP 2023 Deidentification competition. However, these models underperformed relative to the average F1 scores in subtask 2. Notably, the model with only 160 M parameters can achieve a performance close to the average macro-F score for Subtask 1. In contrast, for Subtask 2, models with at least 1.4 B parameters were required to reach micro/macro-averaged F1 scores over 0.30/0.15. Furthermore, models with a minimum of 2.8 B parameters were necessary to achieve macro-averaged F1 scores above 0.32, approaching the median value of all submissions in Subtask 2. Overall, the best performing model for subtask 1 is the 12 B model, which demonstrated superior effectiveness in SHI recognition. For Subtask 2, the top-ranked model operated at a scale of 6.9 B. This result provides insight into the scalability of few-shot learning capabilities within LLM models, such as the Pythia model suite, demonstrating that larger models are particularly beneficial for more complex tasks, such as temporal information normalization.
Fig. 3: ICL performance (few-shot learning with five examples) comparison for Subtasks 1 and 2.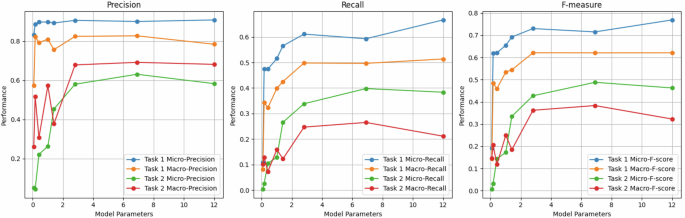
The figure shows the micro- and macro-F1 scores for Subtask 1 and 2 using ICL with five-shot prompts. Results are reported on the test sets for Pythia models of various sizes: 70 M, 160 M, 410 M, 1 B, 1.4 B, 2.8 B, 6.9 B, and 12 B parameters.
In Fig. 4, we further investigate the impact of the number of in-context examples on the performance of both subtasks. The 2.8 B model was chosen as the representative model in the experiment because of its superior performance over small models and comparable performance to larger models. Specifically, in the training set, we chose the number of in-context examples to be 1, 3, 5, and 7, selecting the closest training instances and arranging them in the prompt as demonstrations by their distances, in ascending order. Similar to the previous observations38, we noticed that the recall rates for the two subtasks improve as the number of examples increases. However, the improvement diminishes when the number of samples exceeds five.
Fig. 4: Effect of varying in-context examples on Pythia-2.8B performance across training tasks.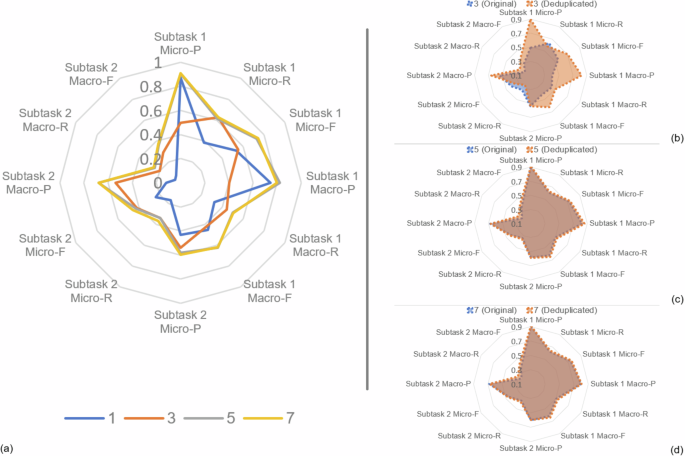
a Performance impact of using 1, 3, 5, and 7 in-context examples for Subtasks 1 and 2 with the original training set. b–d Comparative analysis of Pythia-2.8 B performance on Subtasks 1 and 2 using 3, 5, 7 in-context examples, evaluated on both the original and deduplicated training sets.
Fine-tuning performance
In this experiment, we applied fine-tuning to the Pythia models via two widely used approaches: full-parameter and LoRA-based parameter-efficient fine-tuning39. We observed that, except for the 70 M model trained with LoRA, the fine-tuned models demonstrated a notable improvement in recall rates for both tasks after fine-tuning, resulting in improved F1 scores over those achieved through ICLs (Fig. 5). The detailed results are summarized in Supplementary Table 3.
Fig. 5: Performance comparison between the ICL and fine-tuned models based on full and LoRA fine-tuning.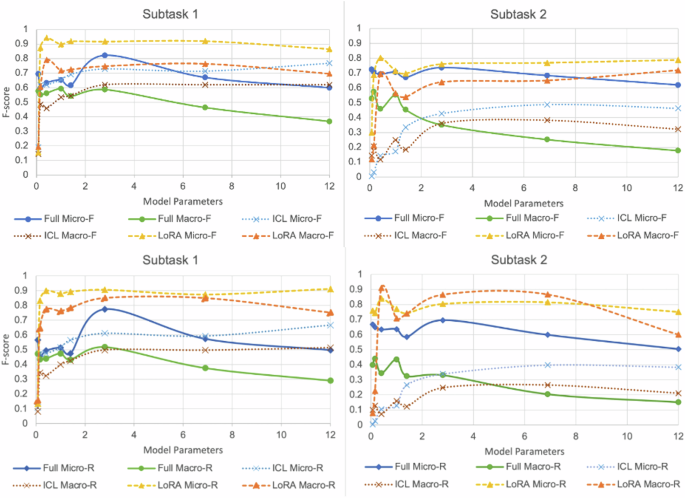
The figure illustrates that model performance generally improves with increasing parameters; however, gains from fine-tuning diminish beyond a certain point, with a crossover observed between the 70 M and 160 M models. Optimal performance is reached at 2.8 B parameters for both subtasks. Beyond this, the performance plateaus or declines, particularly for LoRA and fine-tuning approaches.
Compared with the ICL methods, the fine-tuned models with fewer than 2.8 B parameters showed a notable performance improvement. However, for Subtask 1, the advantage of conventional full fine-tuning over ICL was not significant in models with >6B parameters. Similarly, for subtask 2, the macro-averaged F1 scores were lower than those achieved via ICL in the models with more than 6B parameters. In contrast, our results demonstrate that LoRA is a particularly promising tuning method, outperforming the traditional full-parameter tuning approach because of its superior performance and high efficiency in the training phase, especially in models with more than 1B parameters. Given the moderate dataset size used in this study, our findings align with those of Dutt et al.40, who demonstrated that parameter-efficient fine-tuning methods, such as LoRA, consistently outperform full fine-tuning when working with smaller datasets. Interestingly, the 70 M model trained with LoRA underperformed compared to its counterparts, including both the ICL and full-fine tuning approaches. We attribute this underperformance to the smaller base model, which results in a limited number of learnable parameters after applying LoRA. In such cases, the effectiveness of the adaptations may be restricted because there may not be sufficient interaction among the parameters to capture the complex relationships needed.
Increasing the model parameters generally improves the performance, but the performance gains from fine-tuning begin to decrease after a certain point, with a crossover occurring between the 70 and 160 M parameters (Fig. 5). Additionally, optimal performance is achieved with models of 2.8 B parameters for both subtasks. Beyond this point, the performance improvements plateau and even deteriorate for the LoRA and fine-tuning approaches, respectively. We believe that this is due to the size of the dataset. By limiting the number of trainable parameters, LoRA helps mitigate overfitting in larger models when working with smaller datasets41.
SREDH/AI CUP 2023 competition
The competition was hosted on CodaLab42, a platform that enables participants to download the training set for model development and upload predictions for the validation set to receive immediate performance feedback compared to other teams via a leaderboard. During the final testing phase, participants submitted their predictions for the test set in CodaLab, which were evaluated and ranked using the macro-averaged F1 measure as the primary evaluation metric. The final rankings were determined by averaging the individual ranks of both tasks for each team and sorting them based on the average values. The competition attracted 721 participants, who formed 291 teams. In the final testing phase, each team was allowed up to six submissions over the course of one day, resulting in 218 total submissions. In total, 103 teams submitted their prediction results during the final testing phase.
Table 1 presents the detailed performance of the top ten teams, comparing both micro- and macro-averaged F1 scores for the two subtasks, alongside team numbers. In subtask 1, the top-ranked system developed by Huang et al.43 utilized an LLM-based method based on Qwen44, thereby achieving micro- and macro-averaged F1 scores of 0.945 and 0.881, respectively. For subtask 2, the highest-ranking system was developed by Zhao et al.45, which relies on pattern-based approaches and achieves micro- and macro-averaged F1 scores of 0.844 and 0.869, respectively. The overall performance showed average micro/macro-F scores for subtasks 1 and 2 of 0.666/0.496 and 0.6/0.394, respectively, with median micro/macro-F scores of 0.810/0.710 and 0.679/0.360, respectively. These results highlight significant disparities in performance, indicating that subtask 2 (normalization of temporal information) presents greater challenges than SHI recognition.
Table 1 Top ten teams’ performances for subtasks 1 and 2 on the official test set in terms of micro- and macro-recall (R), precision (P), and F scores (F)
A notable trend in the competition was the widespread use of LLMs (Fig. 6). Specifically, 77.2% of the 57 teams integrated LLMs into their systems, and 63.9% of the top 30 teams used them. Decoder-only transformer architectures were the most prevalent, comprising 66.1 and 83.3% of the submissions for Subtasks 1 and 2, respectively. Encoder-only architectures were the next most common in subtask 1, accounting for 21.0%, whereas encoder-only and encoder-decoder architectures were equally utilized in subtask 2, each accounting for 8.3%. This distribution underscores the current trends in Clinical NLP.
Fig. 6: Overview of methods applied by the top 30 teams.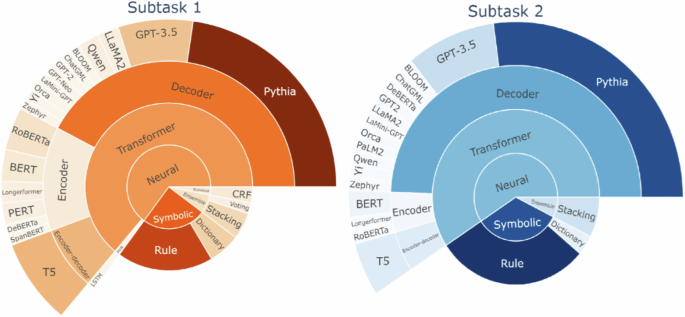
The figure presents a detailed overview of the methods applied by the top 30 teams in the SREDH/AI CUP 2023 competition. The results highlight the widespread adoption of LLMs. 77.2% of the 57 teams and 63.9% of the top 30 teams incorporated LLMs. Decoder-only transformer architectures were most common, comprising 66.1% and 83.3% of Subtask 1 and Subtask 2 submissions, respectively. Encoder-only architectures were the next most common in subtask 1, accounting for 21.0%, whereas encoder-only and encoder-decoder architectures were equally utilized in subtask 2.
Table 2 summarizes the techniques used by the top ten teams for Subtask 1. Pretrained transformer-based LLMs have been widely used, with nearly all top-performing teams incorporating them into their solutions. Most teams approached Subtask 1 as a standalone sequential labeling task, separate from Subtask 2. However, Teams 2, 3, 4, and 9 adopted an end-to-end text generation approach to simultaneously recognize SHIs and normalize temporal expressions. Ensembles of multiple models are typically employed. Almost all the top-performing teams incorporated rule-based methods to some degree. Only one team applied pure pattern and dictionary-based approaches. In addition, two teams explored methods to increase the size of the training sets, particularly for SHI types with limited training instances, and to enhance the context diversity by manipulating tokens within the context.
Table 2 Brief summary of the techniques used by the top ten teams for subtask 1
Table 3 summarizes the techniques used by the top-performing teams for Subtask 2. While ensemble and pretrained transformer-based LLMs are still widely used, seven out of ten teams have incorporated pattern-based approaches. Although several top-performing teams used commercial LLMs, such as OpenAI’s ChatGPT-3.527 and Google’s PaLM246 during experimentation, only Team 5 utilized PaLM2 for their final submission, achieving micro/macro-F1 scores of 0.747/0.777 (Supplementary Table 8). Although the ICL method applied by the team was simpler than the baseline models, when a fixed set of few-shot examples was used, the commercial PaLM2 model outperformed our ICL with the Pythia-6.9 B model.
Table 3 Summary of techniques used by top-performing teams for the temporal information normalization subtask
Compared with the performance achieved by the top ten teams, as shown in Supplementary Fig. 1, the models fine-tuned with LoRA achieved comparable micro-F1 scores for both subtasks. However, most top-ranked teams presented better macro-F1 scores, particularly for Subtask 2. This suggests that, while LoRA fine-tuning is effective, the enhanced methods proposed by the top ten teams could improve the ability of the pretrained models to handle variability across different SHI subcategories. We briefly summarize the enhanced methodologies employed by the top ten teams to provide insights learned from the competition. More details about the methods used by four of these teams can be found in the Supplementary Note 3.
The ensemble approach was found to be more effective. Team 947 compared the performance of BERT-based models48,49 via a sequential labeling formulation with that of generative models based on Finetuned Language Net (FLAN)50. Their experimental results showed the superior performance of the Pythia and FLAN ensembles compared to the BERT-based ensemble. Team 651 employed an ensemble method to merge the prediction results of five Longformer-based52 models trained on distinct data splits. They observed that ensemble learning could significantly reduce the model prediction variability, particularly for categories with limited training instances (Supplementary Table 9).
Given the unbalanced nature of the released training set, the data augmentation method is another critical factor for improving the ability of fine-tuned models to identify all the SHI categories. Some teams53,54 prompted ChatGPT to generate additional training instances to augment SHI types with limited training examples, or those where their fine-tuned model performed poorly. For example, the experimental results of Team 4 showed that LLM-based augmentation significantly improved the macro-averaged F1-score of the 410 M Pythia fine-tuned model by 0.20 (Supplementary Table 7). Team 9 improved the model performance (Supplementary Table 12) for low-resource SHI categories by generating training samples with synthetic surrogates, introducing random noise‒ by inserting irrelevant words, and removing non-SHI words from ∼15% of the sentences‒to enhance the model’s robustness and adaptability47. Finally, Gupta et al.55 was the only team to use other openly available de-identification datasets beyond the released training set to improve the system performance. They augmented the training set with the 2014 i2b2/UTHealth56 and 2016 CEGS N-GRID12 deidentification corpora to train a BERT-based model57 for subtask 1. However, they did not observe any performance improvements with this configuration.
In terms of training methods, most teams apply full-parameter fine-tuning to LLM models with fewer than 1B parameters owing to the limitations of the available computing resources. While full-parameter tuning is computationally intensive, the smaller model sizes make this approach feasible within the constraints of available computing resources. For larger models, teams have predominantly used parameter-efficient tuning techniques, such as LoRA or quantization-LoRA (QLoRA), to mitigate resource limitations. For example, Ru et al.58 fine-tuned Pythia models (70 M, 160 M and 1B) with QLoRA and reported that more parameters in the pretrained model led to generally better prediction results. Chiu et al.59 proposed combining fine-tuning and LoRA, a method similar to that of the Chain-of-LoRA60, to enhance the performance of LLMs in the presented task. Two teams43,51 proposed the application of sliding window methods to enable BERT-based models52 and LLMs44 to aggregate training instances across sequences, thereby enhancing the generalizability and capability of the model to interpret and predict longer sequences. To minimize overfitting, two approaches were highlighted by the participants: Team 2 applied a noisy embedding instruction fine-tuning method61, and Team 9 applied parameter freezing in the intermediate layers and low-rank adaptation (LoRA). The detailed results of Team 2 and Team 9 are in Supplementary Table 5 and Supplementary Table 12, respectively.
Nearly all the top-ranked teams applied pattern-based methods to varying degrees, as shown in Fig. 6 and Tables 2, 3. Teams that focus on LLM-based approaches have highlighted the issue of named entity hallucinations62, which refers to out-of-report (OOR) or out-of-definition (OOD) SHIs. These teams used pattern-based methods to filter out OOR and OOD instances and duplicate instances generated by LLMs. For example, Li et al.63 reported that postprocessing for hallucinations improved their micro- and macro-averaged F-scores by 0.018 and 0.170, respectively. Furthermore, many top-ranked teams43,52,53,58,63,64,65,66 have applied hybrid methods that combine LLMs and pattern-based approaches to increase recall rates, particularly for the recognition of age- and temporal-related SHIs, and for the normalization of temporal SHIs. In contrast, team 145 and Huang, et al.67 presented two pure pattern-based approaches and demonstrated that heuristic patterns can achieve state-of-the-art performance (Supplementary Table 4). In the comparative study of GPT 3.5 fine-tuning and pattern-based approaches presented by Team 1, although pattern-based approaches require more human involvement to improve rule accuracy and coverage iteratively than data-driven LLM methods, they offer significantly better computational efficiency and lower computing power requirements.
Finally, regarding the use of commercial pretrained LLMs, GPT-3.5 was the most popular choice. We found that only one team68 from the top 30 conducted a small-scale study to examine the feasibility of applying ICL with GPT-3.5 to both subtasks. Although they observed promising results in their study, they ultimately decided to shift to local LLM fine-tuning and used ChatGPT solely for data augmentation, owing to the cost associated with API calls for large-scale experiments. Only Team 1 applied fine-tuning based on GPT-3.5, and achieved F-scores of 0.752 and 0.799 for Subtasks 1 and 2, respectively (Supplementary Table 4). This performance is comparable to our results for LoRA fine-tuning of Pythia-2.8 B (0.764/0.650).