Il solito eccellente MacBook Pro, con un processore che va più veloce. Molto più veloce, soprattutto se si guarda a grafica e AI, tanto che in alcune situazioni arriva a superare come performance grafiche M3 Pro; non stiamo parlando del confronto con un processore di cinque anni fa, ma con il processore inserito in workstation “pro” che oggi decine di migliaia di professionisti usano con soddisfazione. Battuto, dopo pochi anni, da un modello “base” di chip che Apple ha inserito anche su un iPad.
L’azienda, in fase di presentazione, ha deciso di confrontare le prestazioni del suo MacBook Pro M5 con quelle del MacBook Pro M1, lasciando intendere che il target ideale per questo nuovo portatile, che non ha certo un prezzo popolare – 1849 euro – siano quelle persone che cinque anni fa hanno preso uno dei primi Apple Silicon e oggi lo iniziano a sentire un po’ stretto. Soprattutto per quegli 8 GB di RAM che erano la dotazione base dei Mac di un tempo, oggi per fortuna si parte da 16 GB.
In realtà, lo vedremo a breve, questo MacBook Pro grazie solo ed esclusivamente ad M5 potrebbe interessare anche a chi ha un MacBook Pro relativamente recente, perché il miglioramento lato GPU e di conseguenza AI è talmente ampio che in alcuni casi specifici potrebbe anche essere sensato rivendere un M3, o un M4, per passare al nuovo modello.

Il MacBook Pro è quello che conosciamo, il disco no
Tutti quelli che hanno provato un MacBook Pro in questi anni concordano su una cosa: per rapporto qualità prezzo siamo davanti ad una macchina eccezionale. Non si tratta solo di prestazioni: la qualità della tastiera, il trackpad, i microfoni, l’audio integrato e lo schermo mini‑LED da 14,2” che nella versione da noi provata è addirittura quello con finitura nanotexture, quindi opaco, sono ai vertici della categoria.
Nella foto sotto si può vedere come il faretto dello studio sia praticamente invisibile riflesso dallo schermo nanotexture: se lavorate in ambienti difficili investite per il pannello “matte”, ne vale la pena.

A questo si aggiunge anche un livello costruttivo eccellente, con la scocca in alluminio (riciclato) che dopo tre anni di vita sembra ancora nuova, e tiene quindi alto il valore nel caso di rivendita come usato.
In questi anni abbiamo pubblicato decine di prove di MacBook con Apple Silicon e questo 14” adotta la stessa identica scocca usata da tutti i modelli Pro da 14” recenti, non cambia niente. Vi se volete qualche dettaglio in più vi rimandiamo alle prove precedenti.

Se guardiamo alla dotazione di base non c’è bisogno probabilmente di cambiare nulla, fatta eccezione forse per lo schermo che ad oggi, per questioni puramente tecniche, è ancora un LCD retroilluminato a Mini-LED quando su iPad è già un OLED con tecnologia tandem.
Rispetto però all’iPad, dove oggi Apple grazie al pannello sovrapposto riesce a garantire una luminosità di 1000 nits dissipando il calore con l’intera struttura, nel caso del MacBook non c’è lo spessore necessario nella zona del display-cover per garantire l’adeguata dissipazione ad un pannello che deve toccare i 1600 nit di picco con contenuti HDR.
Nessun laptop Windows con pannello OLED negli ultimi anni si è avvicinato minimamente alla dinamica che garantisce il mini-LED Apple e solo di recente, su prodotti come l’ottimo Lenovo Yoga Pro 9i 16 G10, si è visto un tandem OLED con resa HDR superiore ai 1000 nits. Facile pensare quindi che sulle prossime generazioni di MacBook possa arrivare un pannello OLED, anche se Apple è sempre più cauta e lascia andare spesso avanti gli altri.
Detto questo non vogliamo soffermarci troppo sul laptop, perché l’unica differenza esistente tra questo modello con M5 e quello con M4, processore a parte, è lo storage: il mercato oggi offre memorie più veloci e Apple prende quello che offre il mercato: il disco del MacBook M5 ha quindi prestazioni superiori a quelle del disco di MacBook degli ultimi anni per una sorta di upgrade forzato.
Come sappiamo la velocità dipende molto anche dalle diverse configurazioni dei banchi utilizzati: la versione che abbiamo in prova è quella da 4 TB e ha fatto registrare i valori qui sotto, che confrontiamo il valore del modello precedente che però aveva 1 TB di storage.
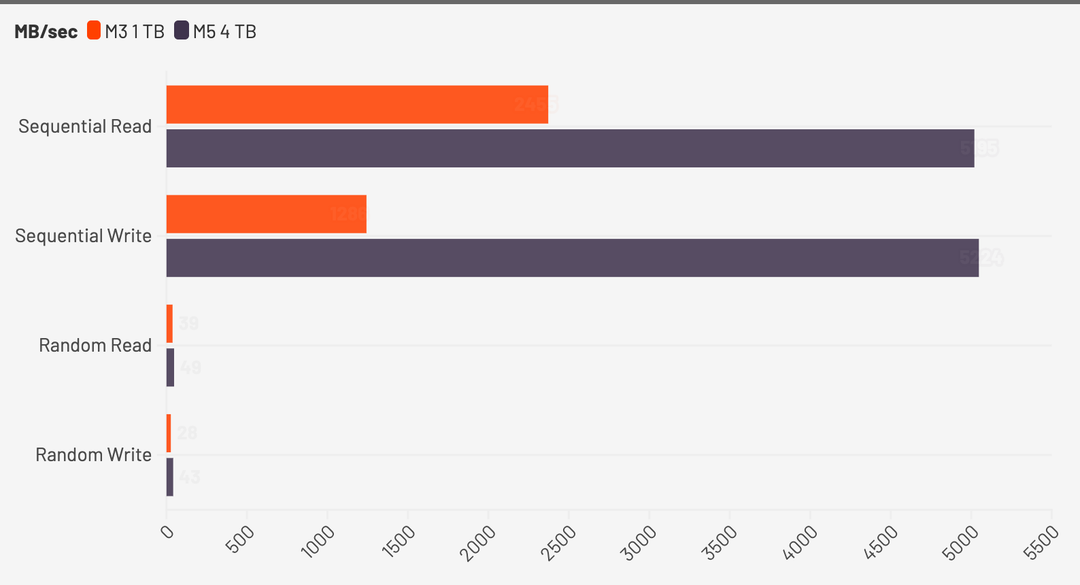
Effettivamente è del doppio più veloce come dice Apple, e questo aumento di velocità si riflette in diverse situazioni: se sul caricamento delle app si nota davvero poco, quando si utilizza l’IA con Ollama (ne parliamo sotto) la situazione cambia.
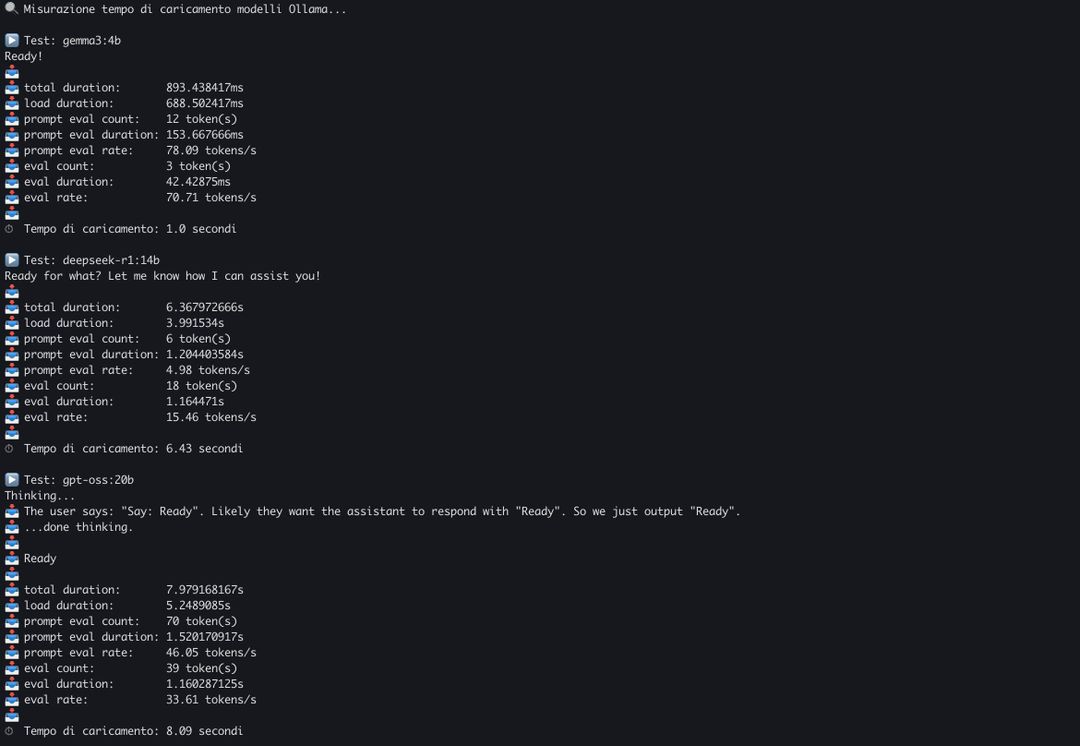
Ollama a seconda delle richieste deve trasferire il modello AI dall’hard disk alla memoria di sistema, e quando un’app chiede un modello diverso deve liberare la memoria e caricare il nuovo. La velocità del disco incide sul tempo di caricamento.
Abbiamo scritto un breve benchmark che misura il tempo di caricamento dei modelli: Gemma3 da 4 miliardi di parametri viene caricato in memoria in un secondo, per il modello open-weight di OpenAI, GPT-OSS da 20b servono 8 secondi. Da questo dipende anche la velocità di risposta del modello, il primo “token”.
Aumenta anche i trasferimento sui file grandi, come è giusto che sia.
CPU, tutto come previsto: classico salto generazionale
Il processore M5 sarà probabilmente l’ultimo Apple Silicon prodotto a 3 nanometri. Come A19 Pro, che condivide con il chip per laptop e workstation parte dei blocchi funzionali, anche M5 è costruito utilizzando il processo produttivo di TSMC a 3 nanometri di terza generazione, quello più evoluto che il chipmaker chiama N3P. Il prossimo passo saranno i 2 nanometri, che debutteranno, curioso caso, con A20 sul prossimo iPhone (20 Å – ångström – equivale a 2 nm).
N3P, rispetto a N3E, garantisce circa il 5% in più di prestazioni, e se guardiamo alla sola CPU del processore M5, i classici due cluster formati da 4 core ad alte prestazioni e da 6 core ad alta efficienza, quello che vediamo è il classico incremento dovuto in parte al processo produttivo e in parte all’aumento di clock. A questo si aggiunge però un netto boost su alcune operazioni in virgola mobile, lo abbiamo visto nelle prove dell’iPad Pro che usa lo stesso processore.
Tutto questo si riassume in un incremento reale del 15% circa sia nelle prestazioni single core che nelle prestazioni multicore. Apple non ha spinto di più perché non era necessario, doveva usare i transistor per altro: con il punteggio di 4321 in Geekbench 6 single core ci troviamo davanti al core più veloce esistente oggi sul mercato consumer, più veloce anche dell’imminente Snapdragon X2 Elite con core Oryon 3.
Il tutto con un impatto sul consumo che c’è, ma è minimo.
Nei grafici sotto si vede in che modo, nel corso degli anni, Apple sia riuscita ad incrementare in modo costante la velocità della sua CPU con livelli di incremento che altre architetture non sono riuscite a reggere.


C’è ovviamente una differenza netta quando si tratta di più core che lavorano in parallelo, situazione questa che riflette meglio la resa con molte applicazioni “pro”. Con 18102 punti, nonostante abbia solo 10 core, la versione base di M5 va più veloce di M3 Pro e di M2 Max.
Come si traduce questo all’atto pratico?
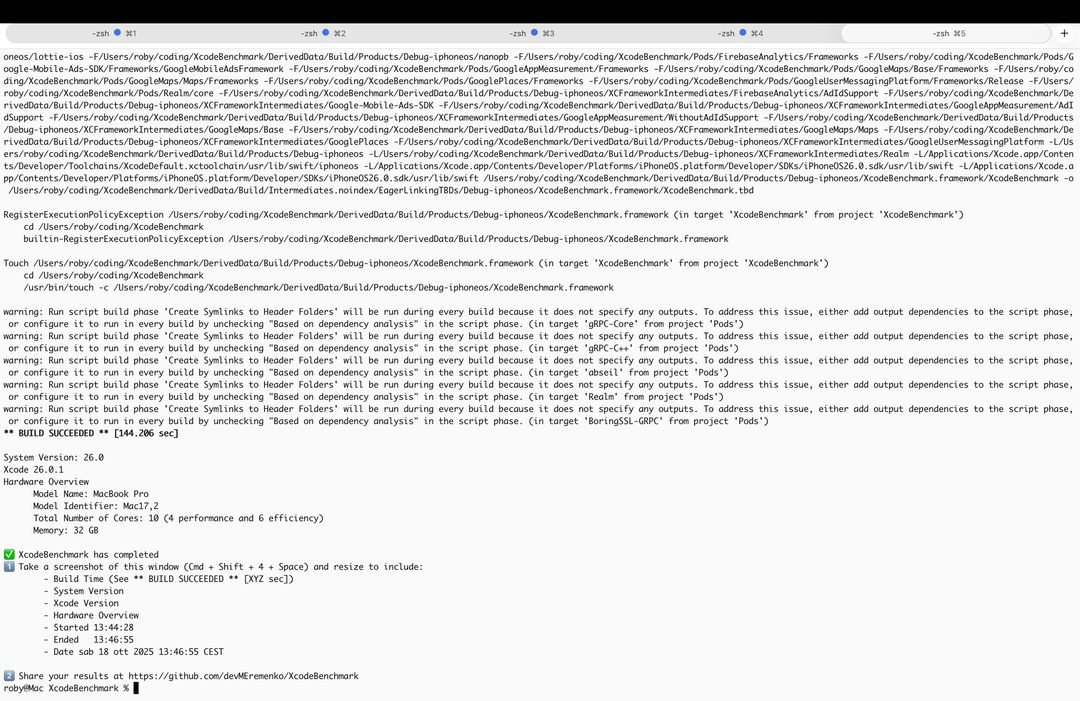
Il caso più comune di utilizzo della CPU con tutti i core al lavoro è la compilazione di un progetto: abbiamo usato il noto benchmark per XCode, che scarica e compila un progetto Xcode pesante e complesso e misura quanto tempo impiega il Mac a completare la compilazione.
M5 come risultato spunta 144 secondi, e non sappiamo come si pone questo valore con gli altri risultati presenti a database perché il benchmark è stato appena aggiornato per supportare la versione più recente di XCode, bisogna aspettare che altre persone lo eseguano su macchine meno recenti.
Abbiamo fatto girare il benchmark su un MacBook Pro M3, quindi una macchina più vecchia di due generazioni, e nelle stesse identiche condizioni abbiamo ottenuto 210 secondi, quindi un risparmio del 25% di tempo. Ricordiamo che M3 ha due core ad alta efficienza in meno, per 8 core totali.
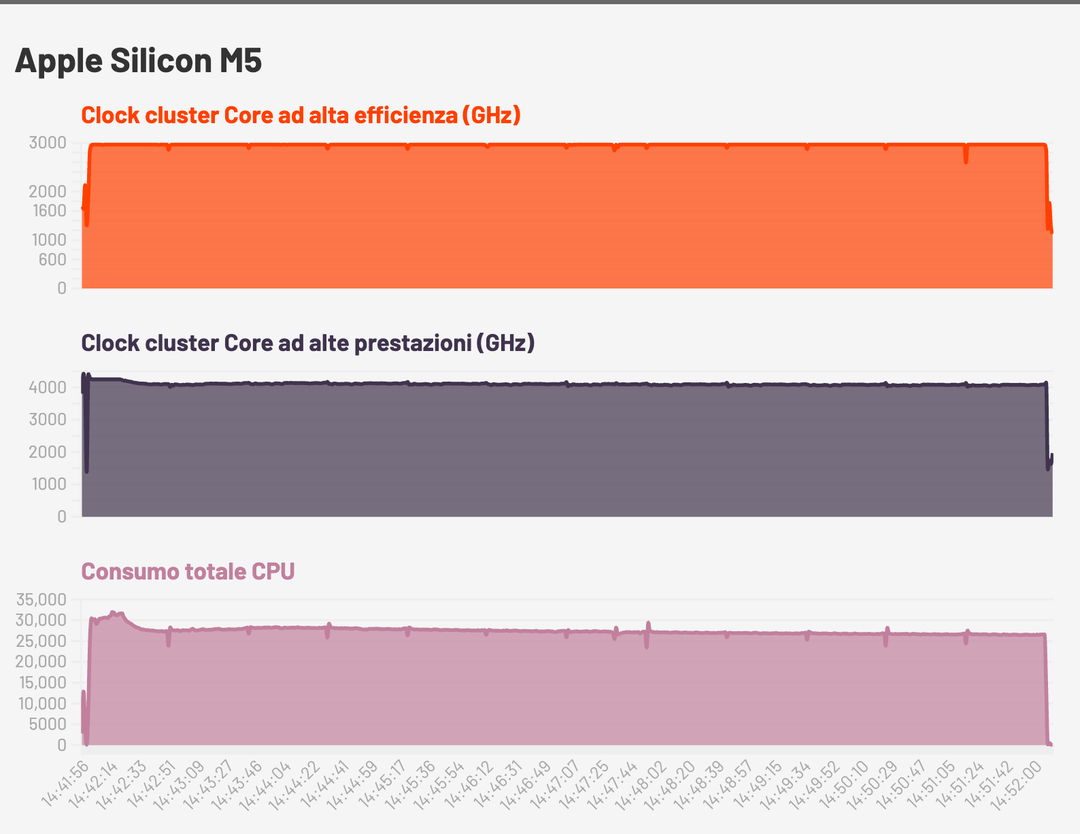
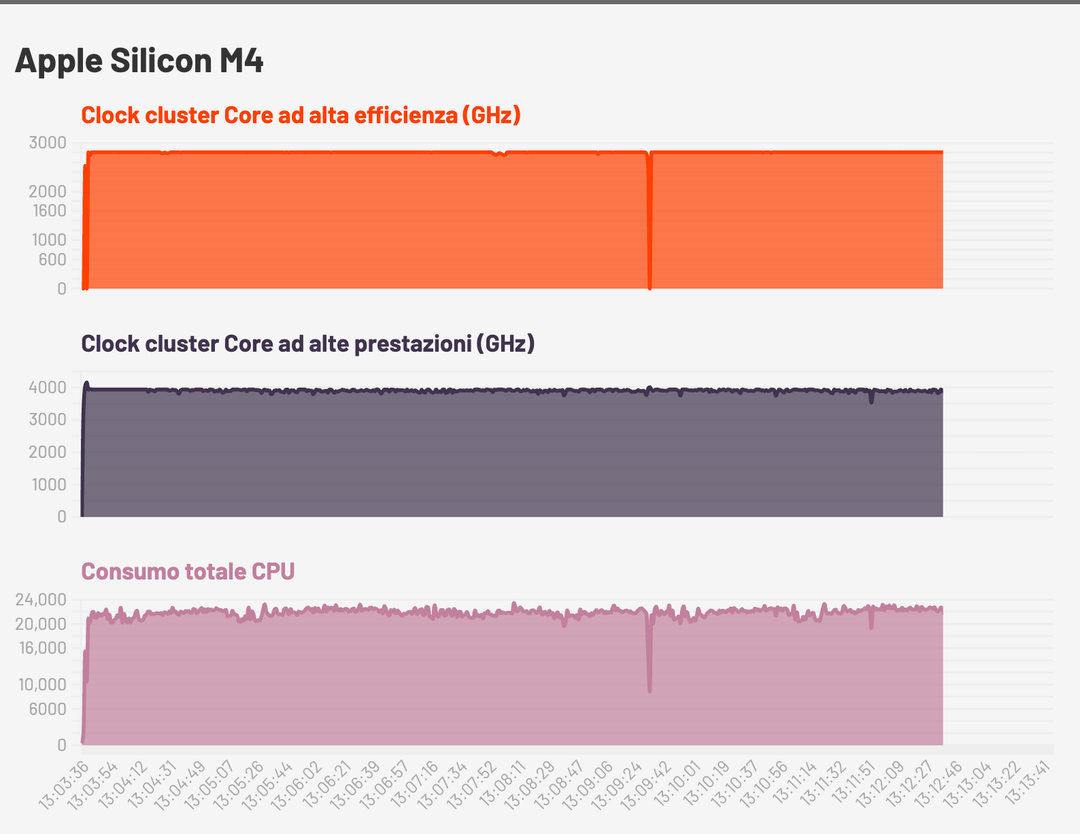
Per quanto riguarda i consumi ecco la stima data da Powermetric su un ciclo di CPU al 100% per entrambi i core e con il laptop a batteria. Ricordiamo che si tratta di una stima, non è un valore precisissimo anche se abbiamo verificato su presa ed è molto simile.
Come si può vedere M5 ha una frequenza di clock più alta, e ha anche una sorta di “turbo” iniziale con il clock che sale a 4.4 GHz per poi scendere. Il consumo iniziale, durante il boost, tocca i 30 Watt ma dopo pochi secondi scende e si assesta sui 27 Watt, questo per una riduzione della frequenza di clock che si stabilizza sui 4.1 GHz.
M4, dai grafici, aveva un consumo leggermente più basso ma si tratta come sempre di un consumo a pieno carico, quindi una situazione particolare: nell’uso normale non c’è alcuna percezione di diminuzione di autonomia.
GPU, l’incremento di prestazioni impressiona. Va quanto M2 Ultra
M5 sarà ricordato per essere il processore Apple Silicon con il più grande salto generazionale di sempre per quanto riguarda la GPU, ben più alto di quello che c’è stato da M2 a M3 quando Apple ha introdotto il mesh shading e il ray tracing.
I core GPU di M5 sono gli stessi usati anche su A19 Pro, e avevamo già visto cosa erano capaci di fare: Apple ha ridisegnato interamente il core grafico e non ha solo rivisto tutte le pipeline di rasterizzazione, ma ha anche aggiornato i core raytracing.
Non solo: dentro ognuno dei 10 core grafici è presente un acceleratore neurale per calcoli matriciali che gestisce alcune operazioni sui dati direttamente nell’unità di calcolo grafico, senza la necessità di spostare questi dati dalla memoria (per passare dal neural engine) e quindi senza latenza.
Serve per l’IA generativa, ma serve anche per Metal 4 che utilizza l’IA per l’upscaling dei fotogrammi, per il denoising del ray tracing e per la generazione dei fotogrammi.
Al momento non ci sono giochi che sfruttano questa possibilità, e il primo dovrebbe essere Cyberpunk 2077 con una patch attesa tra qualche settimane.
 Cyberpunk gira benissimo su MacBook Pro 14 senza raytracing e bene con raytracing
Cyberpunk gira benissimo su MacBook Pro 14 senza raytracing e bene con raytracing
Come vedremo più sotto, quando parleremo di IA, la maggior parte dei modelli LLM già beneficia dei nuovi componenti di calcolo matriciale, e rispetto a M4 le prestazioni sono superiori di un ordine di grandezza che supera anche i 3x.
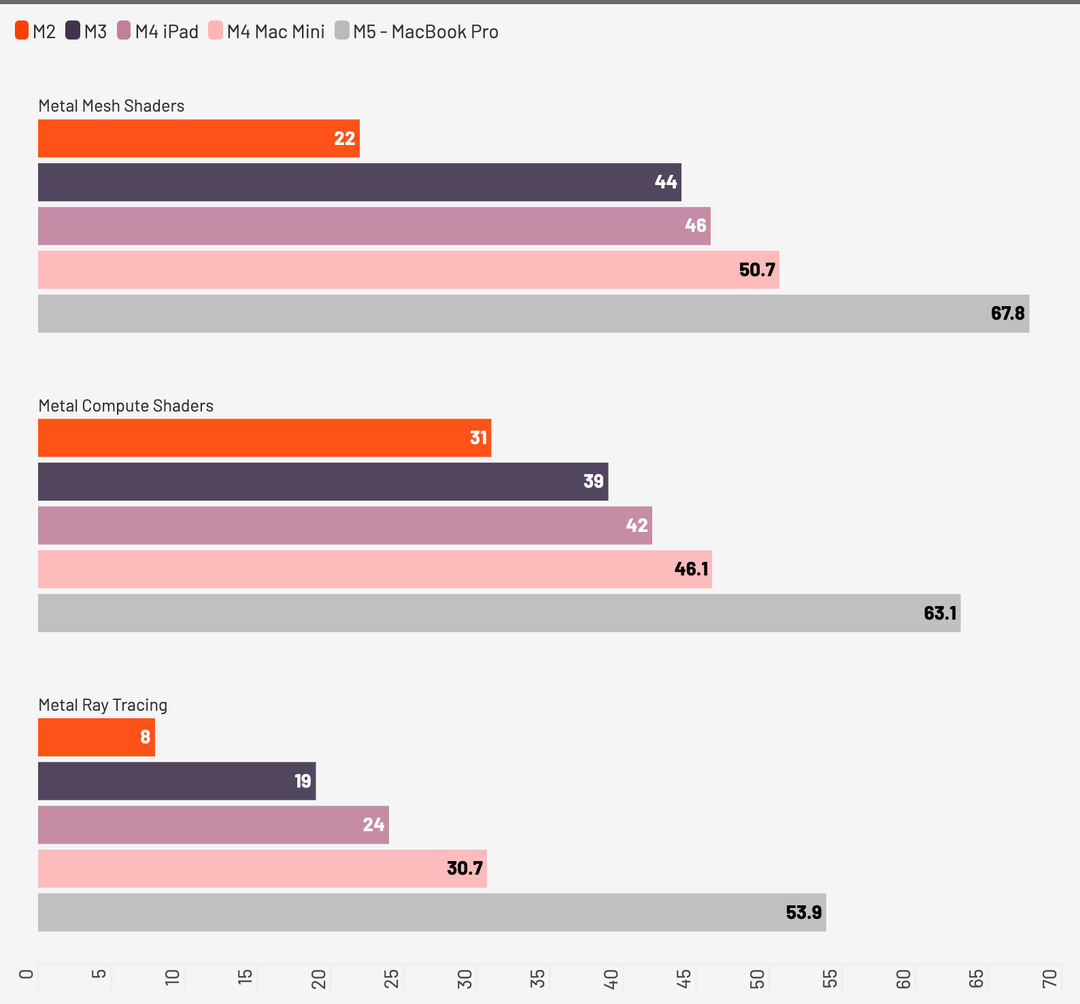
Ci vogliamo però concentrare sulla pura grafica, dove Apple promette un incremento in alcune situazioni superiore al 70% rispetto agli scorsi anni.
Partendo con il classico benchmark sintetico, che usiamo da sempre per valutare la resa delle GPU, possiamo vedere nel grafico quanto M5 spinga molto di più in tutte e tre le situazioni, ma come sia proprio il ray tracing l’ambito dove c’è l’incremento più grande, superiore al 70% dichiarato.
Ci piace però guardare più al lato pratico, e siamo partiti con uno degli strumenti più usati in ambito 3D da studenti e professionisti in quanto open source, ovvero Blender. Trattandosi di una workstation pro “entry” visto che i MacBook con M5 Pro e M5 Max arriveranno più avanti, abbiamo pensato che Blender sia probabilmente il software più adeguato visti anche i costi di licenze delle altre soluzioni.
Il benchmark di Blender prevede il rendering di tre scene molto famose, Classroom, Monster e Junkshop, e abbiamo eseguito per diverse volte il benchmark mediando i diversi risultati, comunque molto simili tra un ciclo e l’altro.
Questa è la media ottenuta in samples al minuto.
- Classroom, con 478 samples/minuto, ottiene un valore molto vicino a quello dell’Apple M3 Pro con GPU a 18 cores che si ferma a 476 samples/minuto.
- Junkshop, con 447 samples/minuto, ottiene un risultato pari a Apple M1 Ultra che tocca i 453, ma ha ben 64 core grafici. Un core grafico di M5 va quanto 6 core grafici di M1.
- Monster, con 835 samples/minuto, è in linea con l’M3 Pro (GPU da 18 core) che fa segnare 830 samples/minuto.
Qui il grafico con i valori globali aggregati, dove M5 si posiziona vicino a M3 Pro.
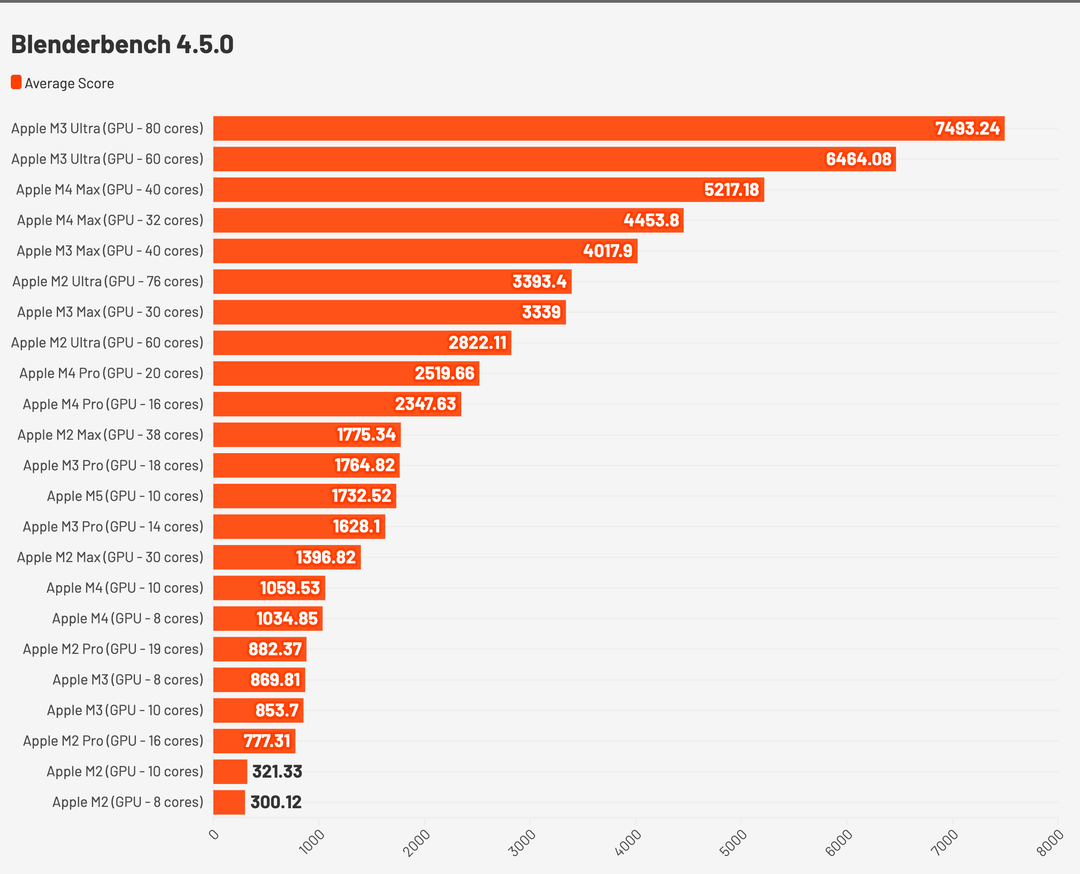
NVIDIA sulla grafica gioca ancora un’altra partita, ma in una sola generazione Apple ha colmato un gap enorme e lo ha fatto con il suo SoC di base con grafica integrata: Blender conferma un incremento della velocità del 70% tra M4 e M5.

Se cambiamo il motore di rendering, passando a Redshift di Maxon, i risultati restano eccellenti. Per renderizzare la classica scena di Vultures in ray tracing ci abbiamo messo 400 secondi. M4 Pro, per la stessa scena, ha richiesto 300 secondi, M3 Pro è allineato con 412 secondi mentre M4 vuole quasi 600 secondi, 10 minuti.
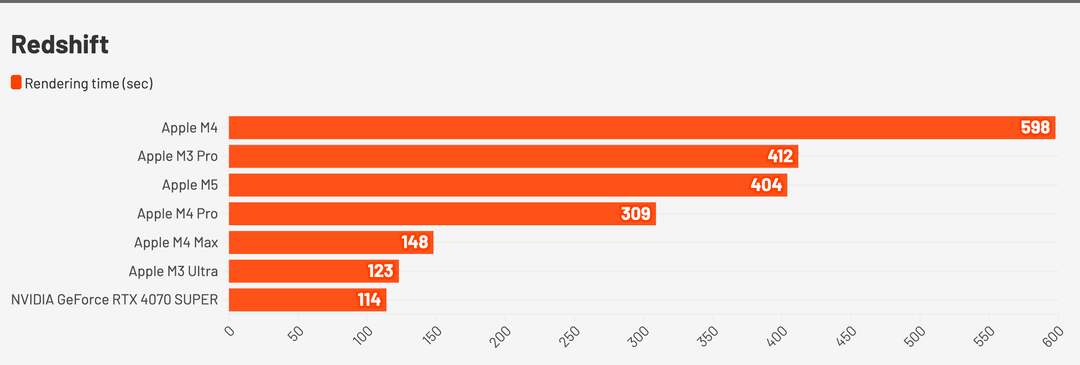
M5 va quasi il doppio più veloce rispetto ad M4 ed è allineato come performance a M3 Pro, che ha 18 core GPU comunque dotati di accelerazione ray tracing. Un core grafico di M5 vale quasi due core grafici di M3.
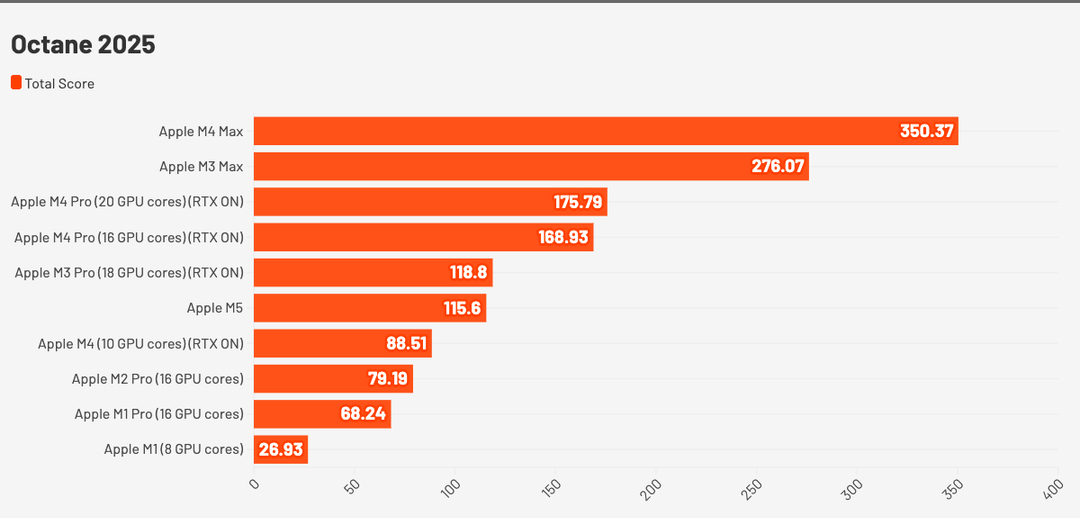
Situazione simile anche su OctaneBench, dove con 116 punti si posiziona vicino a M3 Pro, anche se qui è “solo” del 25% più veloce rispetto a M4.
Ogni motore di rendering sfrutta il processore in modo diverso ed è anche ottimizzato diversamente, e Octane è tra tutti i motori quello che sfrutta meno le primitive di Metal.
Octane
non è scritto in Metal nativamente, ma usa un livello di compatibilità (“RTON”) che converte shader CUDA in Metal al volo, almeno fino alle release software di qualche anno fa. Non sappiamo se ora la cosa sia cambiata, ma è anche l’unico software grafico dove il guadagno è ridotto anche se si tratta comunque di un incremento notevole.
 Cyberpunk 2077, un assaggio di ray tracing in attesa di Metal 4
Cyberpunk 2077, un assaggio di ray tracing in attesa di Metal 4
Per la serie “chi ha il pane non ha i denti e chi ha i denti non ha il pane” abbiamo voluto vedere come si comporta M5 con i giochi, più che altro con Cyberpunk 2077 che è l’unico gioco disponibile in grado di sfruttare e pieno le potenzialità del nuovo processore grafico.
Non esiste ancora un profilo “Per il Mio Mac” destinato a M5, ma soprattutto non ci sono ancora le migliorie che dovrebbero a breve per supportare le nuove funzioni di Metal 4. Nonostante questo grazie ai nuovi core ray tracing e grazie all’incremento di potenza di calcolo dei core riusciamo a far girare Cyberpunk 2077 con il livello di dettaglio indicato nella schermata sotto, e con ray tracing attivo, a circa 30 fps. Questo con una resa decisamente d’impatto se consideriamo sia l’HDR che il ray tracing. Togliendo il ray tracing si superano i 55 fps.
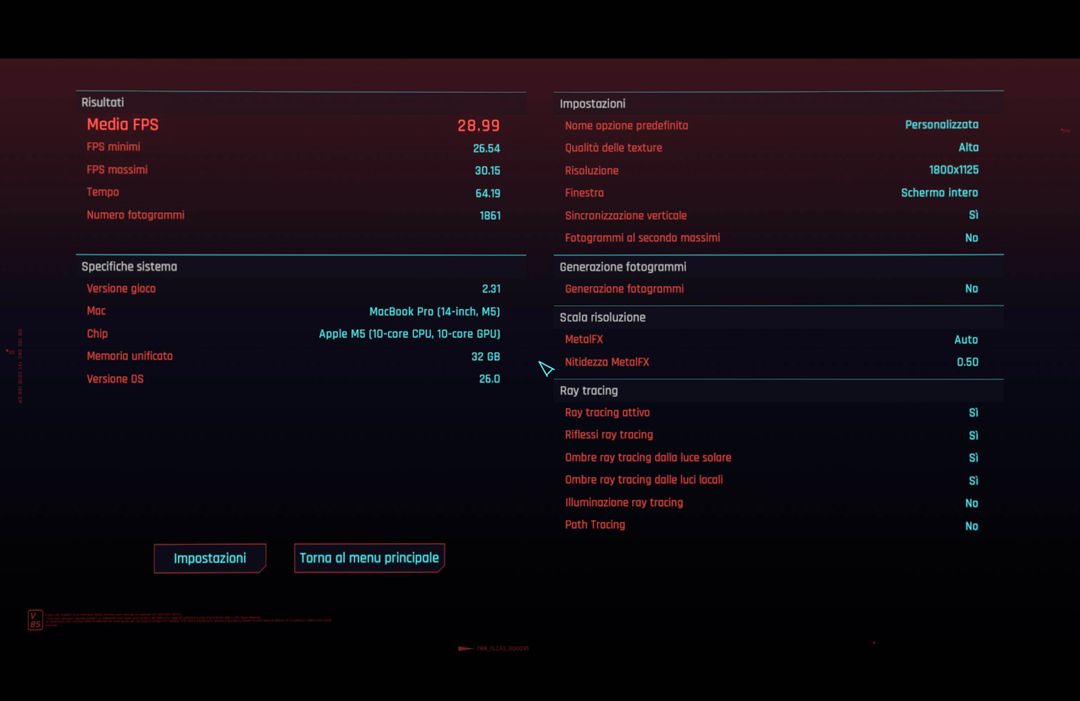
A breve, quando arriverà il frame generation, sarà possibile toccare i 50 fotogrammi al secondo stabili con ray tracing, qualità alta, risoluzione full HD con una GPU integrata.
Apple con M5 è arrivata al livello di una 4070 laptop, con un consumo però molto più basso: non c’è processore con grafica integrata che riesca a dare le stesse prestazioni con supporto ray tracing e path tracing (questo solo con Metal 4).
L’unica speranza, per un po’ di competizione nel mondo Windows sul segmento “integrato”, è la discesa in campo di NVIDIA con il suo processore ARM basato su architettura Blackwell.
I nuovi SoC Qualcomm previsti per inizio 2026 vanno fortissimo lato CPU e NPU, ma la GPU Adreno è ancora troppo indietro e non supporta nemmeno ray tracing hardware.

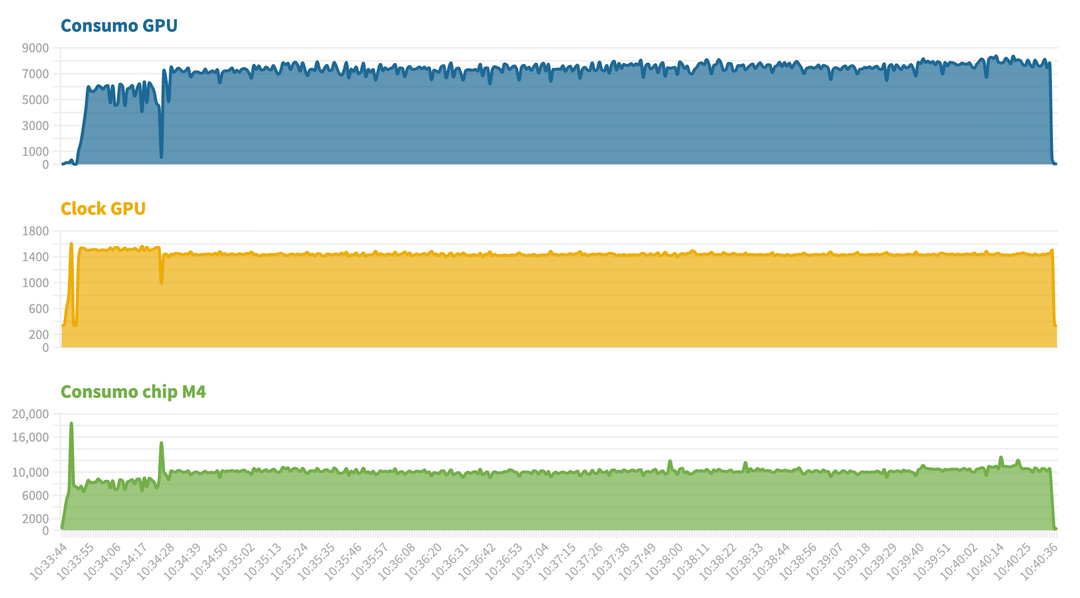
Uno sguardo infine ai consumi della GPU: in questo caso il grafico generato usando i valori di stima del sistema operativo sono errati, sembra che la GPU consumi “solo” 10 Watt. Non è così, perché consuma dai 30 ai 40 Watt quando spinge al 100%. Siamo comunque davanti ad un consumo davvero basso.
Un processore pensato per l’IA generativa
Quando Apple ha introdotto M5 ha parlato esplicitamente di “salto in avanti netto per l’IA”, e i dati che abbiamo raccolto confermano tutto questo. I nuovi moduli per il calcolo matriciale inseriti nella GPU, il nuovo Neural Engine e l’utilizzo di memorie più veloci hanno permesso di ottenere un risultato in termini di prestazioni che non ha eguali nell’ambito dei laptop con GPU integrata.
Per quanto riguarda la memoria il bus resta sempre a 192 bit, ma l’adozione di memorie LPDDR5X più veloci, attorno a 9600 MT/s, ha permesso di portare l’ampiezza della banda per la memoria a 153 GB/s, il 30% circa in più rispetto ai 120 GB/s di M4 che usava moduli LPDDR5X 7500 MT/s.
Il salto in termini di prestazioni lo si vede chiaramente nel confronto con i precedenti Apple Silicon in un benchmark sintetico (Geekbench AI), e nel grafico abbiamo inserito anche alcuni processori di classe diversa per dare un’idea di quanto siano migliorate le prestazioni.
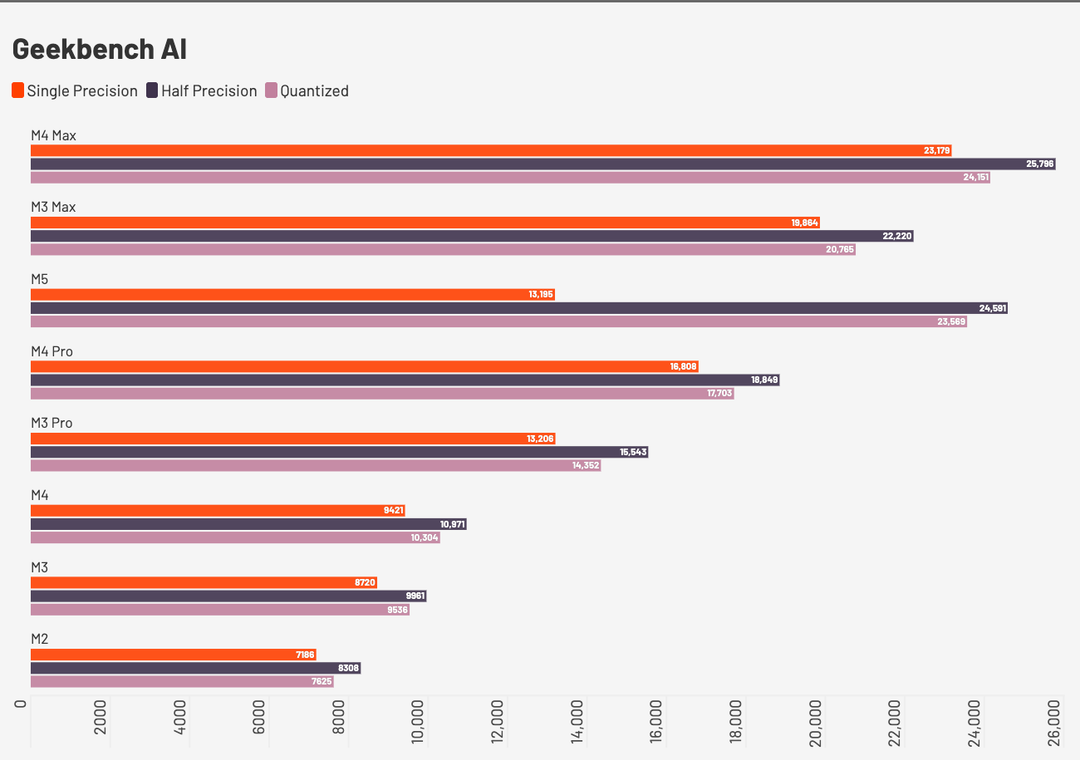
Come si può vedere nell’immagine sopra mentre sulle operazioni FP32 (single precision) usa ancora la pipeline classica di calcolo vettoriale, ma guadagna comunque il 40% rispetto ad M4, in FP16 usa le nuove half-precision pipelines della GPU e ha un throughput effettivo quasi raddoppiato.
Trattandosi di un computer che deve fare soprattutto inference, il valore che più interessa è quello in INT8: quasi tutti i modelli distribuiti (es. mistral:7b, llama3:8b, phi3) sono in versioni quantizzate e qui M5 sfrutta le math units introdotte con la nuova generazione di GPU. La velocità guadagnata è impressionante, più del doppio rispetto ad M4 e vicino a M4 Max. Ricordiamo tuttavia che la memoria, e la banda, sono un collo di bottiglia per i modelli IA pertanto nonostante il benchmark mostri M4 Max e M5 vicini, M4 Max è un processore nettamente più veloce in ambito IA proprio per la banda di memoria, il bus e la quantità di memoria.
A beneficiare dei nuovi acceleratori nella GPU è soprattutto l’AI generativa, e abbiamo provato i due volti dell’IA generativa, da una parte Drawthings utilizzando Flux come modello, quindi non certo un modello leggero, e dall’altra OllamaBench, per valutare i tokens/secondo generati con alcuni modelli decisamente pesanti, tra i quali GPT-OSS da 20 miliardi di parametri e DeepSeek R1 da 14 miliardi di parametri.
Con DrawThings, a parità di “prompt”, rispetto a M3 il nuovo processore ci mette meno della metà del tempo per generare una immagine.
Se guardiamo invece ai benchmark di diversi modelli open con Ollama M5, con 32 GB di RAM e una larghezza di banda di 153 GB/s, si posiziona come velocità di token generati al secondo allo stesso livello di M3 Pro, che ha un processore con 16 core GPU e ben 300 GB/sec di banda per le memorie, il bus è a 256 bit.
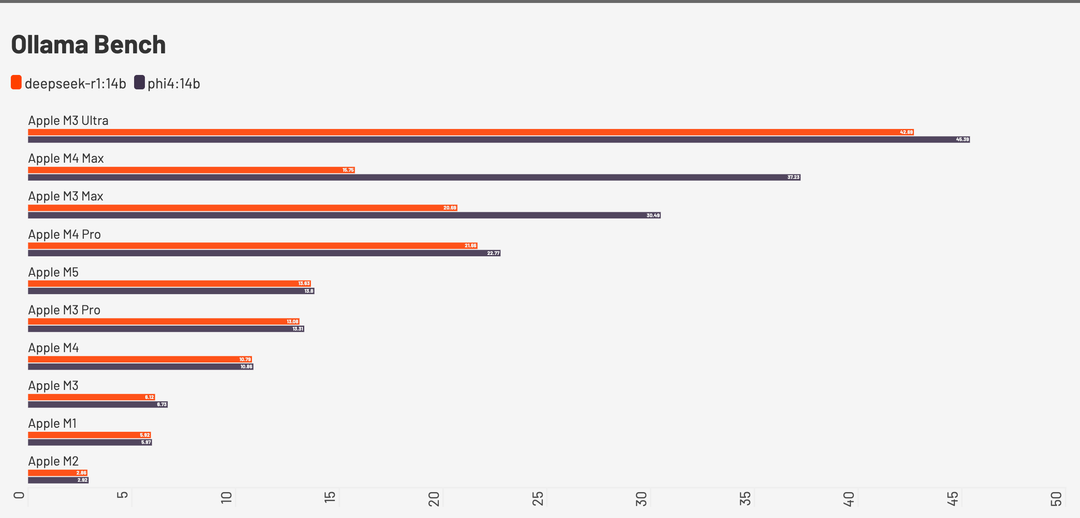
A questo punto vi chiederete cosa sia questo Ollama, e c’è un motivo se lo abbiamo inserito: in attesa di Apple Intelligence, Ollama è l’elemento che rende un MacBook Pro un vero AI computer.
Come l’IA rivoluziona l’esperienza di uso di un MacBook
Come abbiamo visto dai benchmark sopra, il nuovo processore M5 è drasticamente più veloce di ogni altro processore Apple usato nella stessa categoria di prodotto, e questo in un ordine di grandezza che può arrivare anche al 200% o al 300% di incremento di velocità. Questo grazie soprattutto ai nuovi neural core che Apple ha inserito in ogni singolo core GPU: se la NPU si occupa di gestire piccoli modelli legali al riconoscimento vocale e visivo, all’estrazione di testi o alla classificazione di immagini, quando si parla di modelli LLM e di IA generativa la GPU è l’elemento sul quale fare affidamento. NVIDIA ci ha costruito una fortuna attorno alle sue GPU.
Oggi, dopo lo scivolone di Apple Intelligence e di Siri, l’opinione pubblica è convinta che Apple sia indietro sull’IA. Se guardiamo ai modelli probabilmente è così, i modelli di OpenAI, Google e Anthropic sono più avanzati di quelli Foundation di Apple ma in realtà, grazie agli sviluppatori e al lavoro fatto da questi ultimi, Apple oggi può già mettere nelle mani di un utente un computer che si appoggia all’IA locale per migliorare e ottimizzare i flussi di lavoro in modo flessibili. Tanti produttori ci stanno provando in ambito Windows, vedi Lenovo, ma si trovano davanti ad un terreno poco fertile e devono spesso sviluppare soluzioni da soli, poco integrate e spesso limitate.
Con l’uscita di macOS Tahoe Apple ha poi permesso agli sviluppatori di accedere ai suoi modelli Foundation: i modelli allenati dall’azienda per Apple Intelligence possono essere usati anche dalle app per potenziare le loro funzionalità senza usare servizi cloud.
Le scorse settimane sono uscite le prime app che si appoggiano a questi modelli, e per chi volesse approfondire abbiamo parlato della novità in questo articolo, dove mettiamo anche in evidenza le prime app che usano modelli Foundation.
I primi piccoli passi di Apple Intelligence nell’App Store. Ecco le prime app che usano l’IA locale
Sempre con il rilascio di macOS Tahoe Apple ha aggiunto la possibilità, per gli utenti, di utilizzare questi modelli all’interno dei Comandi Rapidi, creando flussi di lavoro che fino ad oggi non era possibile gestire in locale: si può chiedere di elaborare un testo, di riassumerlo o di tradurlo e di usare il risultato della manipolazione come elemento alla base per una azione eseguita da un’altra app.
Ad oggi ci sono ancora tanti limiti in questo approccio, come si può leggere dall’articolo sotto, ma con il tempo la situazione sta migliorando e sempre più app espongono le azioni per facilitare la loro automazione.
Comandi è l’app per iPhone e Mac che tutti dovrebbero imparare ad usare. La guida completa
In attesa di Siri con Apple Intelligence Ollama è la vera IA su Mac
In questa prova vogliamo però parlarvi di altro, introducendo Ollama.
Ollama, che si può scaricare da questo sito, una volta installato si manifesta come un piccolo “Lama” che appare nella barra di sistema. Siamo davanti ad un ambiente di esecuzione per modelli AI in locale capace di sfruttare al massimo l’hardware Apple Silicon attraverso Metal.
Utilizzando Ollama un utente può scaricare ogni tipo di modello “open” supportato dal computer, e tutto dipende ovviamente dalla quantità di memoria disponibile e dal processore, e tutti i modelli scaricati saranno gestibili e utilizzabili dalle varie app che supportano l’IA locale. Un repository di modelli AI locale centralizzato.
Se i modelli Apple Foundation non sono ancora perfetti, grazie ad Ollama sul MacBook Pro M5 si può usare il modello open da 20 miliardi di parametri di OpenAI, si può usare LLama, si possono usare Gemma, Qwen, Phi, Deepseek e decine di altri modelli: sta all’utente scegliere il modello più adeguato a seconda anche delle sue necessità.
Il principio di funzionamento di Ollama è semplice: esattamente come un server locale (è un server locale) accetta da una applicazione un prompt seguito dal nome del modello che deve gestirlo e si occupa di processare la richiesta, offrendo la risposta nel minor tempo possibile.
Ollama c’è anche per Windows e per Linux, ma per poter girare bene oltre a servire una scheda NVIDIA servono anche software che la sfruttino. Al momento la quasi totalità dei software con una interfaccia user friendly usabili anche da chi non ha competenze specifiche ma vuole usare l’IA in locale sono software per Mac.
Abbiamo deciso di prendere uno di questi software come esempio, perché ci aiuta a far capire quello che si può realmente fare oggi su un Mac in ambito AI. Grazie ad Ollama, e senza aspettare Siri con Apple Intelligence, è possibile avere su un MacBook un primo assaggio ( siamo agli inizi) del modo in cui l’IA cambierà il modo di usare i computer.
Raycast, questo il software, è un’app che sostituisce Spotlight: fa esattamente quello che può fare Spotlight, cercare documenti e app, ma oltre a questo fa decine di cose in più, tra le quali integrare una serie di comandi che utilizzano l’IA per lavorare su testo copiato negli appunti, tab del browser aperte, immagini a schermo e anche dati dei programmi tramite estensioni.
Raycast è gratuito, può usare l’IA di ChatGPT, di Claude e di altri provider a pagamento ma permette anche di connettersi ad Ollama in locale. Abbiamo scelto quest’ultima configurazione perché stiamo lavorando con una serie di file e documenti sul nostro computer e non vogliamo che niente esca verso servizi esterni, soprattutto se si tratta di dati sensibili.
Potremmo stare ore a parlare di quello che si può fare con Raycast, ma mettiamo solo alcuni esempi. Nella videorecensione, che pubblicheremo nelle prossime ore, mostriamo questi esempi in funzione.
Se selezionate qualsiasi testo, ad esempio, potete chiedere di elaborare le informazioni, trascriverle, riassumerle, tradurle e manipolarle esattamente come si farebbe con un qualsiasi testo che viene copiato e incollato dentro Gemini o ChatGPT.
Si possono poi creare poi azioni che eseguono prompt specifici, questo per rispondere ad esigenze precise dell’utente: come test abbiamo creato il comando “Pro e contro” per avere in pochi secondi i pro e i contro di qualsiasi recensione aperta in una delle tab del browser.
Non serve copiare il testo, RayCast grazie alle estensioni del browser può accedere alle pagine aperte e leggerne il contenuto.
Volendo si può anche selezionare una parola e chiedere di spiegarla, una immagine chiedendo di cosa si tratta oppure un testo molto lungo e chiedere di generare una mappa mentale per lo studio. Queste, come si vede dalla schermata sotto, vengono generate in pochi secondi in locale e sono scaricabili anche in formato HTML.
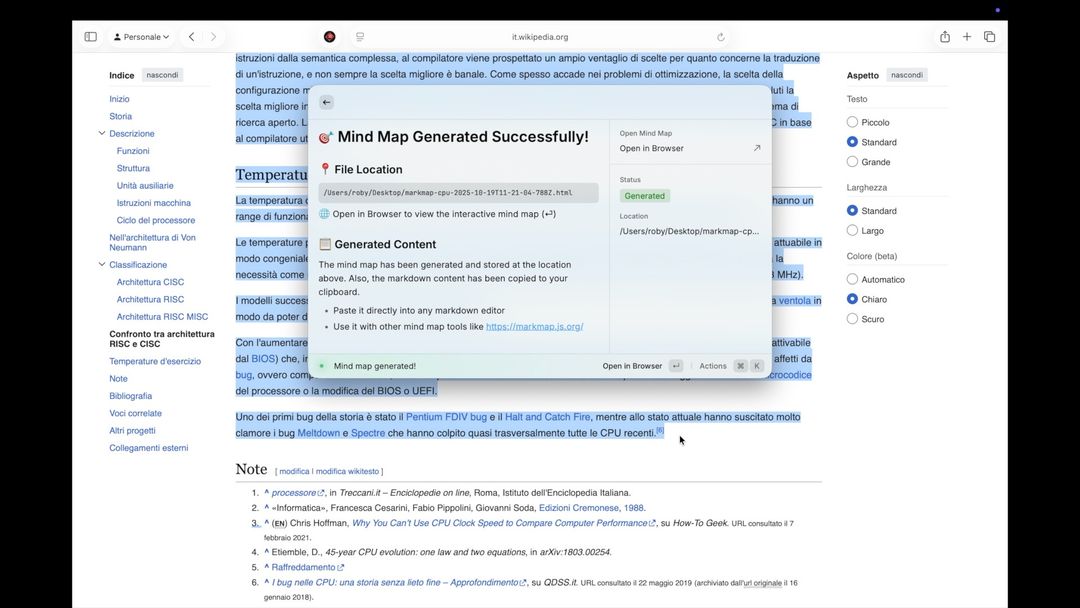
Volendo tramite IA Raycast può anche riassumere e leggere i “video” di Youtube: basta chiederlo mentre si sta guardando un video e sarà lui a capire di che video si tratta, chiederà a Youtube i sottotitoli e in base a questo oltre ad una sintesi potrà anche rispondere a domande specifiche.
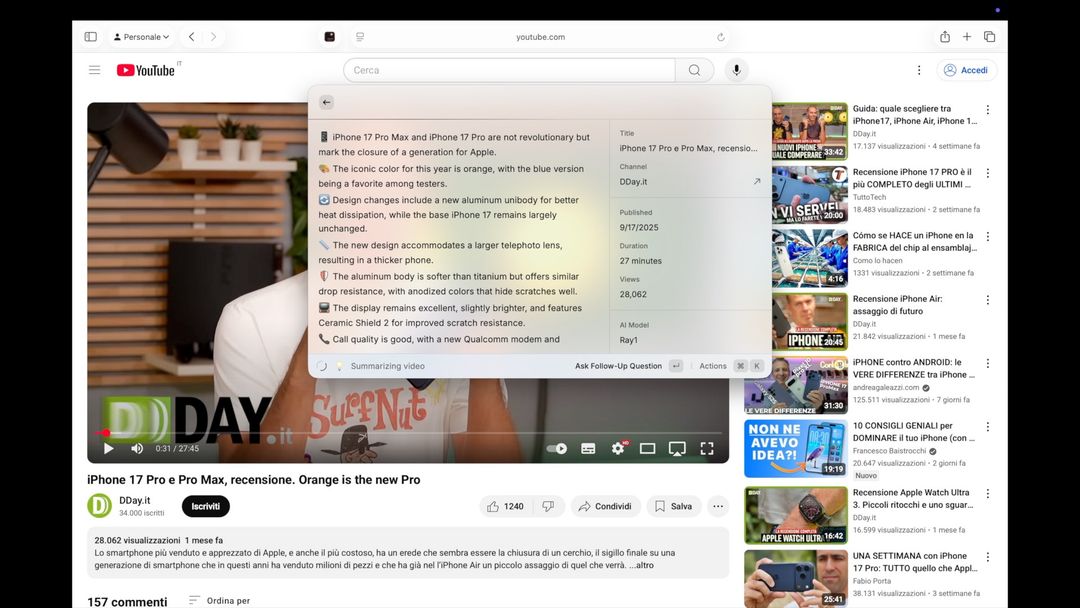
Quello che abbiamo dato è solo un assaggio, perché Raycast integra anche quella che può essere definita una “chat AI” che fa esattamente quello che fa un chatbot come ChatGPU ma con una chicca in più: si possono richiamare gli applicativi sul computer per i quali si è installata una estensione dedicata.
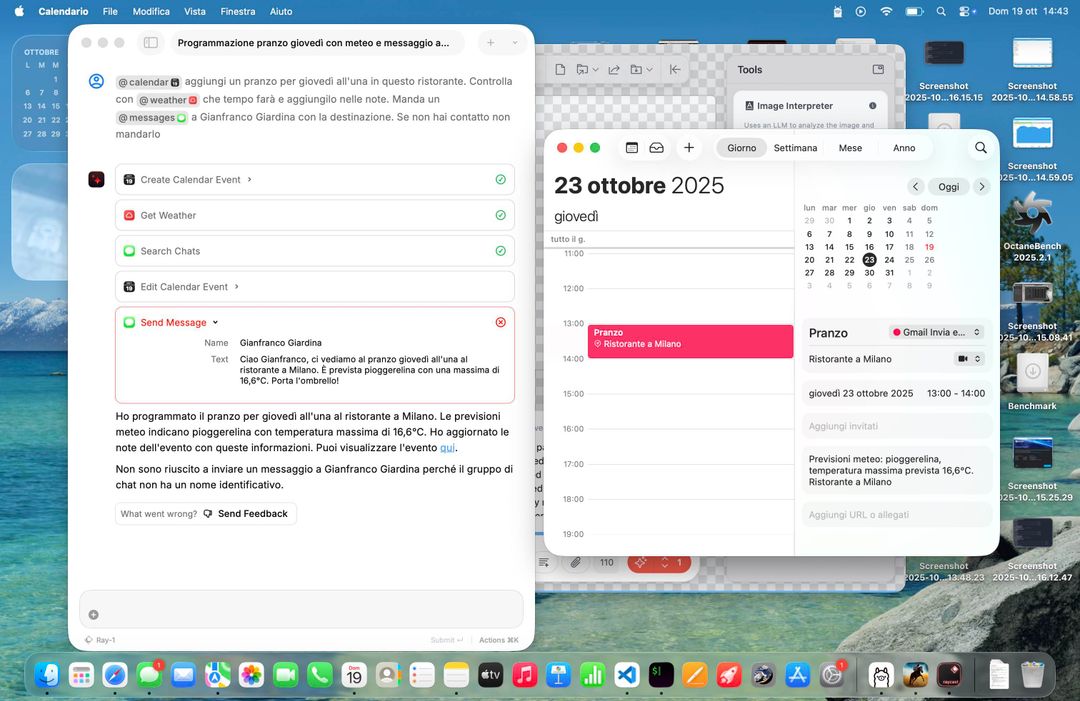
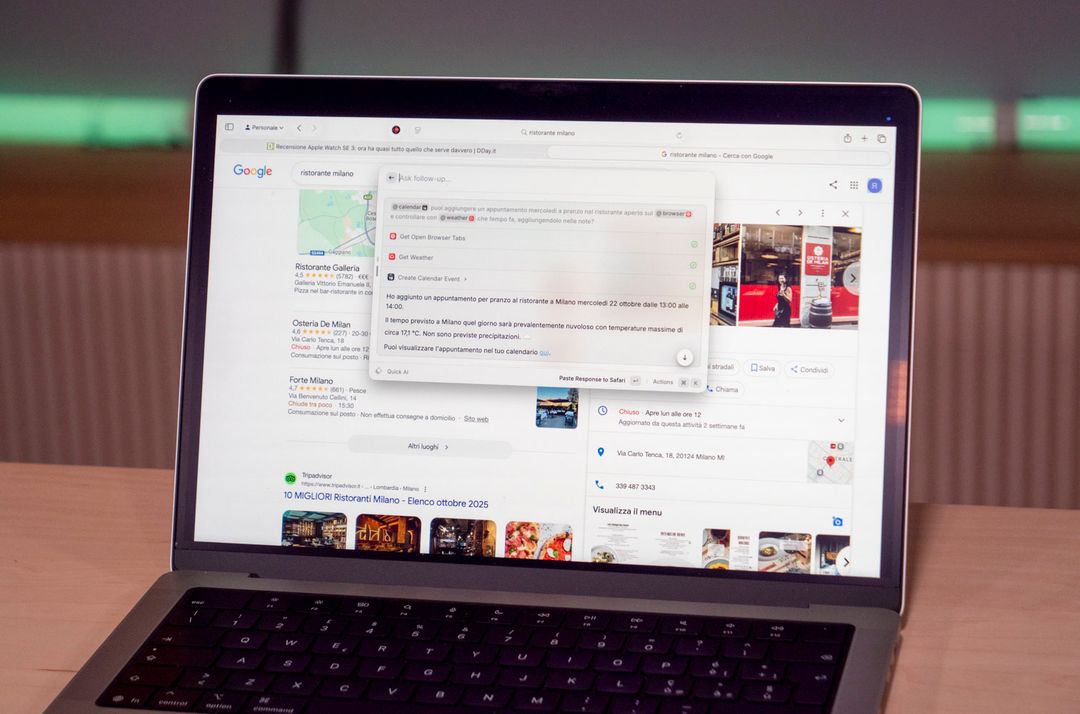
Si richiamano le app usando la @ come si farebbe con un amico in chat: nella foto sotto abbiamo chiesto al calendario di fissare un appuntamento e di controllare tramite l’app Meteo che tempo farà in quella data. Notate la sintassi della chiamata e il risultato: questo è quello che doveva fare a voce la nuova Siri.
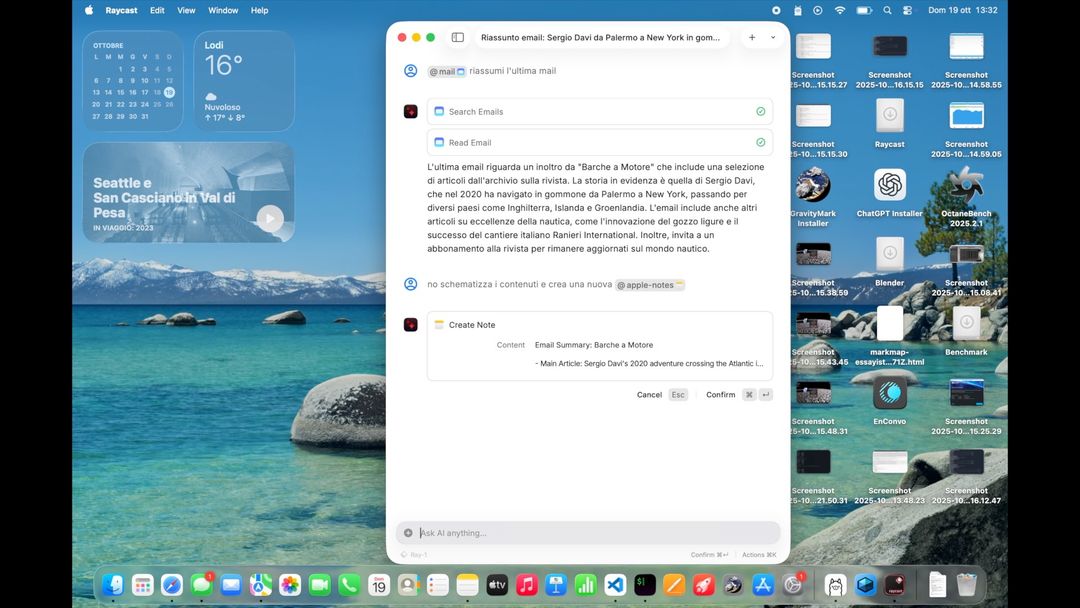
Possiamo anche chiedere di cercare nelle email, e tutto questo con il client di posta chiuso: Raycast ha accesso al database delle email (se gli date accesso) e cerca mail per soggetto, data, mittente elaborando il contenuto del testo e interagendo con la rubrica.
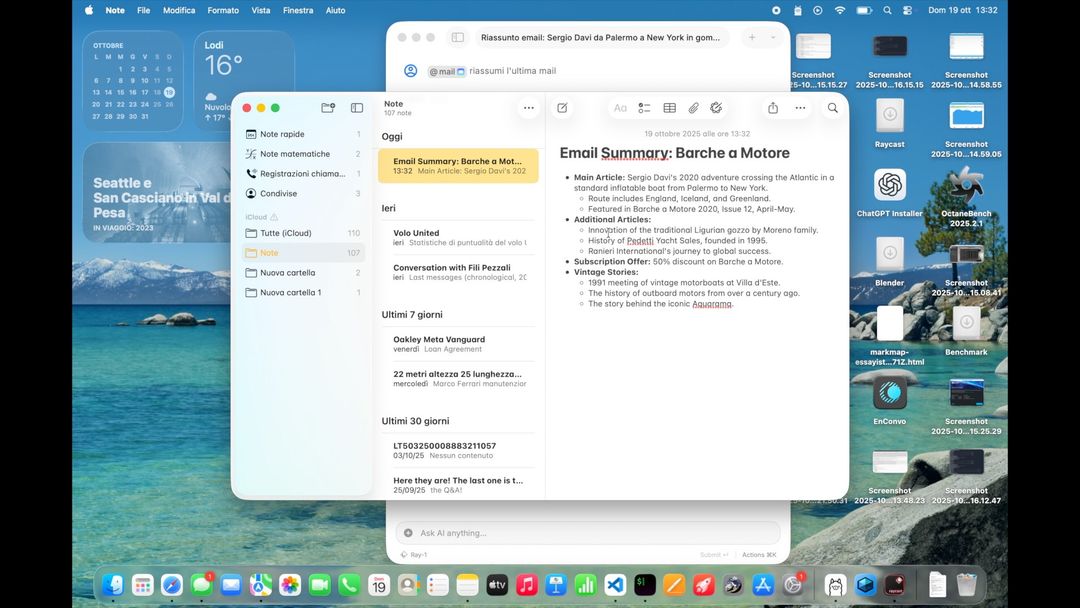
Qui sotto abbiamo chiesto ad esempio di prendere una mail, riassumerla e creare una nota. Lo ha fatto, in pochi secondi.
Raycast ha migliaia di estensioni disponibili, sono tutte open source ed è anche facile creare estensioni: ognuna di queste permette di accedere a dati delle app che il modello locale potrà elaborare per creare un output che potrà essere usato per altre app. Tutto in locale, sicuro e protetto ma anche gratuito.
 Come creare con un chatbot un appuntamento a calendario per un pranzo in un ristorante, tutto automatico
Come creare con un chatbot un appuntamento a calendario per un pranzo in un ristorante, tutto automatico
Per un utente un po’ evoluto, come abbiamo scritto, è facile creare script e azioni che ricalcano i suoi workflow abituali: noi, ad esempio, abbiamo scritto un comando per valutare le modifiche fatte al codice di un sito e creare una descrizione del “changelog” uniforme e coerente con tutte le modifiche dettagliate e spiegate.
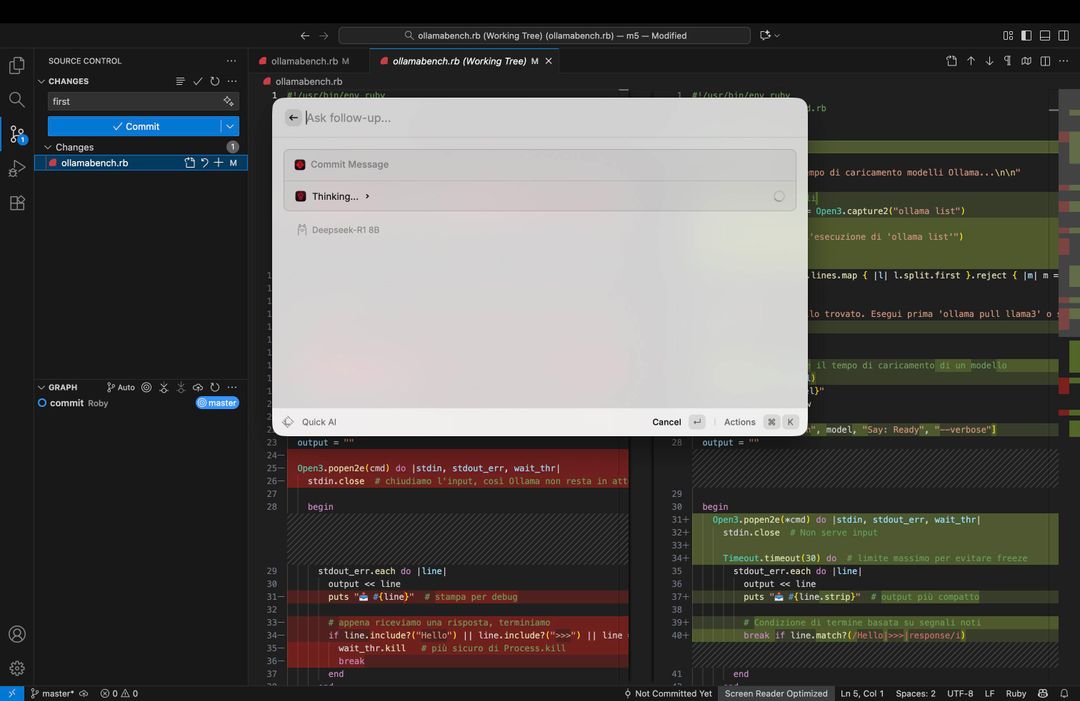
Non è finita qui, perché Raycast supporta anche MCP (Model Context Protocol), il protocollo creato da Anthropic che permette ai modelli IA di accedere a dati che non necessariamente risiedono sul computer, ma possono essere su server in cloud. Tramite MCP Raycast può ad esempio usare Blender, e abbiamo chiesto al chatbot di creare decine di oggetti 3D in una posizione specifica come gli abbiamo anche chiesto di leggere e scrivere file da Google Drive. MCP è la chiave che permetterà di creare agenti AI, dove i modelli si passano i dati in modo sicuro e protetto.
Abbiamo anche configurato un server MCP (lo fa Raycast in automatico) per poter accedere ad una cartella specifica del nostro laptop, fornendo quindi ad un modello la capacità di vedere che file ci sono, spostarli, aprirli, gestirli. Qui sotto la richiesta per l’elenco dei file PDF presenti in una directory, libri scolastici, con il chatbot che ha risposto in pochi secondi.
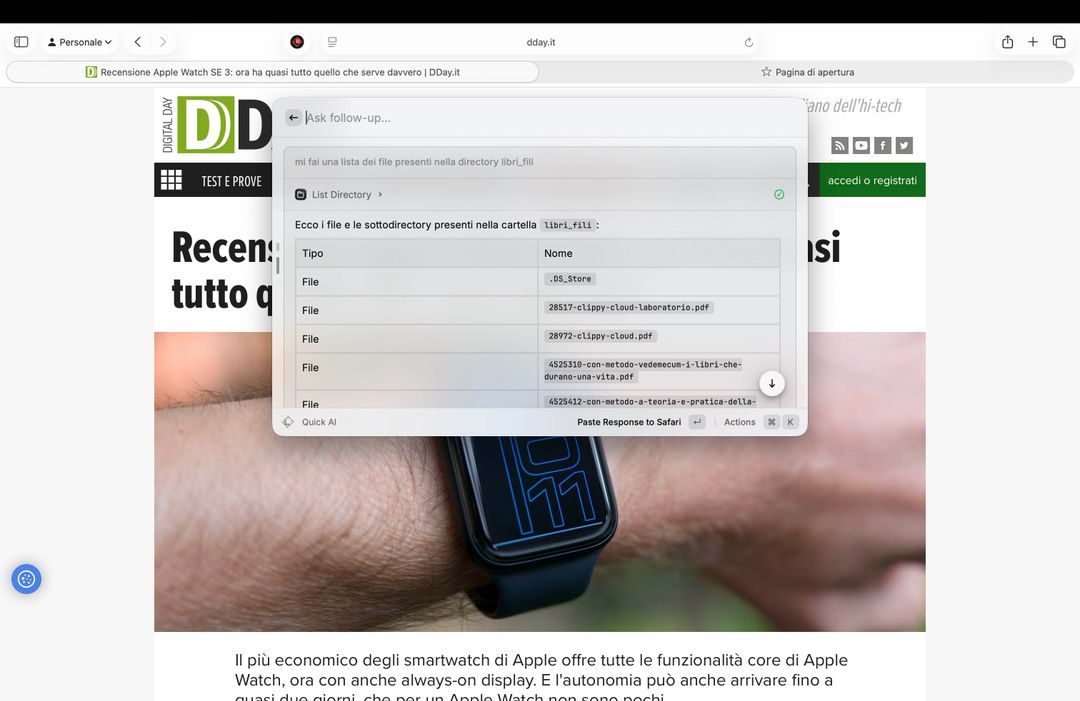
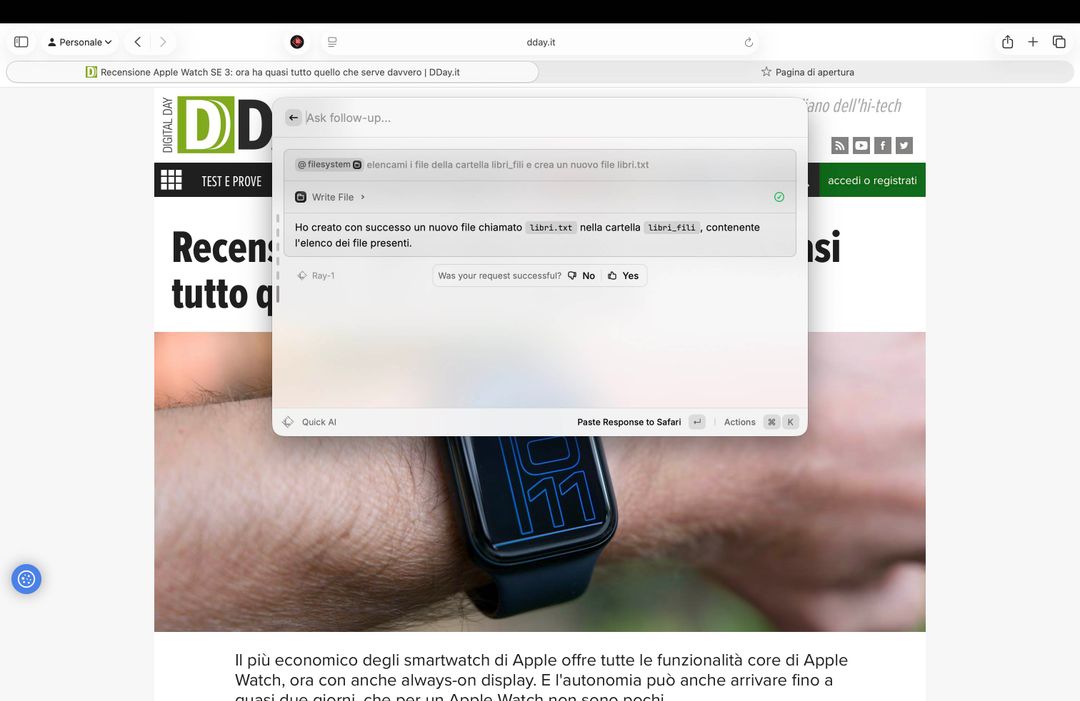
Successivamente abbiamo chiesto di creare un file di testo contenente l’elenco di questi libri formattandolo in un determinato modo e l’IA ha scritto il file, questo dopo averci chiesto il permesso finale per procedere alla scrittura. Impressionante.
Raycast è solo un esempio, ma fa capire benissimo che la potenza di M5 in ambito AI combinata con Ollama e protocolli come MCP sono davvero l’inizio di una rivoluzione “AI”.
Molto di questo si può già fare in cloud, ma vuol dire inviare dati sensibili all’esterno: se sono dati aziendali non si può fare, è contro il GDPR.
Come esiste Raycast esistono decine di app simili, e sono tutte user friendly e facili da usare: c’è Msty.ai, che permette di avere una sorta di NotebookLM in locale, c’è EnConvo, che fa più o meno quello che viene fatto da Raycast, ci sono plugin per Photoshop che permettono di generare immagini da Flux o da Stable Diffusion in locale e ci sono decine di sistemi per creare agenti in locale.
Un inizio, e ci vorrà ancora un po’ di tempo perché a volte questi software sbagliano, e non tutti i modelli sono perfetti, ma con M5 Apple ha posto le basi per la rivoluzione AI che tutti si aspettavano da Apple Intelligence, e che invece arriva dalla porta di servizio. L’IA locale ha senso solo se è veloce e se si possono usare modelli di qualità: su questo MacBook Pro, soprattutto nella versione da 32 GB, si possono usare modelli davvero buoni e i tempi di risposta, e di generazione, sono davvero ottimi.