
Qualcomm ha annunciato Snapdragon X Elite nel 2023: dopo anni di tentativi con processori ARM per Windows poco competitivi rispetto alla concorrenza x86, ricordiamo lo Snapdragon S4 che veniva usato sui primi laptop Windows RT nel 2012 o il più recente Snapdragon 8CX nel 2019, per la prima volta con X Elite ci siamo trovati davanti ad un processore che ha saputo dare filo da torcere ad AMD e Intel.
In questi due anni Qualcomm ha trovato l’appoggio incondizionato dei produttori di PC da una parte, sono stati lanciati sul mercato decine di design, differenti per prezzo e prestazioni, e di Microsoft dall’altra, che ha sostenuto ARM sia con la gamma Surface sia con lo sviluppo di Windows per ARM, aggiungendo piano piano quello che mancava alla piattaforma per poter rivaleggiare con Intel e AMD anche sul piano della compatibilità.
L’aggiunta di recente delle istruzioni AVX/AVX2 nell’emulatore Prism, la crescita delle app native, il supporto dei diversi anticheat a livello kernel per i giochi e lo sviluppo delle DirectX con un occhio anche ad ARM hanno fatto il resto: oggi, nonostante gli scetticismi di chi difende la soluzione più tradizionale, i laptop con Snapdragon iniziano ad avere una quota di mercato non enorme ma rilevante, siamo sopra il 10% per il segmento di prezzo di riferimento, che è quello premium.
 Kedar Kondap, SVP & GM of Compute e Gaming di Qualcomm è a capo della divisione PC Snapdragon
Kedar Kondap, SVP & GM of Compute e Gaming di Qualcomm è a capo della divisione PC Snapdragon
Snapdragon X Elite può essere considerato la “beta” per Qualcomm nel segmento PC Windows, e questi due anni hanno segnato l’inizio di un percorso che tutti sapevano, Qualcomm inclusa, non sarebbe stato facile ma che era comunque necessario per far capire che quello dell’azienda di San Diego non era un tentativo per saggiare la reazione del mercato, ma solo il primo passo di un percorso che sarebbe durato anni.
Oggi, grazie alla compatibilità quasi totale con l’ecosistema Windows, e vale sia per i software sia per l’hardware (stampanti e altre periferiche), con l’arrivo di Snapdragon X2 Elite Qualcomm si prepara alla seconda fase. Una fase contraddistinta da obiettivi ancora più ambiziosi: diventare il punto di riferimento in ambito PC per quanto riguarda l’autonomia, per le prestazioni e per l’IA. Con un bonus, il gaming: Qualcomm è convinta che il suo nuovo processore potrà sbloccare il gaming in mobilità su Windows, offrendo prestazioni superiori a quelle di Intel e AMD quando si tratta di giocare a batteria e con grafica integrata.
 Tre anni di processori Qualcomm per PC: i primi prodotti con il nuovo chip li vedremo nella prima metà del 2026
Tre anni di processori Qualcomm per PC: i primi prodotti con il nuovo chip li vedremo nella prima metà del 2026
Un po’ di Apple, un po’ di Intel e un po’ di AMD: a caccia di talenti per colmare il gap
La storia dello Snapdragon X Elite la sappiamo: nei primi mesi del 2019 tre veterani dell’industria dei semiconduttori, Gerard Williams III, Manu Gulati e John Bruno, hanno fondato Nuvia per realizzare un nuovo processore per datacenter.
Williams ha lavorato per anni in Apple come Chief CPU Architect e ha un passato anche in ARM, Gulati e Bruno hanno anch’essi esperienze in Apple (e in alcuni casi in Google) nelle architetture SoC e chip mobili.
Il 12 gennaio 2021 Qualcomm annunciò l’acquisizione di Nuvia per circa 1,4 miliardi di dollari: Qualcomm si portò in casa non solo la tecnologia, ma anche il team di progettisti di Nuvia con l’idea di sviluppare internamente microarchitetture custom ARM che potessero competere in ambiti oltre gli smartphone. Nasce così il core Oryon, usato su X Elite prima e su Snapdragon 8 Elite nella sua seconda versione.
In questi anni Qualcomm ha fatto shopping di talenti guardando all’intera industria dei computer, e a San Diego la scorsa settimana, quando Qualcomm ha voluto raccontarci nel dettaglio come era stato progettato il nuovo X2 che arriverà sui PC nella prima metà del 2026, abbiamo avuto modo di parlare con ciascuno di loro.
C’è Pradeep Kanapathipillai, CPU Architect e Vice President of Engineering di Qualcomm, che ha lavorato per 4 anni a PA Semi, l’azienda che Apple ha acquisito per creare Apple Silicon e successivamente 12 anni in Apple, dove ha lavorato sulla famiglia A degli iPhone dall’A6 all’A14: è lui che ci ha raccontato nel dettaglio come e perché la nuova CPU di Snapdragon X2 è diversa da tutti gli altri processori sul mercato.
 Pradeep Kanapathipillai, CPU Architect e Vice President of Engineering di Qualcomm, ci ha raccontato la CPU nel dettaglio
Pradeep Kanapathipillai, CPU Architect e Vice President of Engineering di Qualcomm, ci ha raccontato la CPU nel dettaglio
C’è Eric Demers, 10 anni passati in AMD, che ci ha raccontato nel dettaglio l’architettura della nuova GPU Adreno e Lucian Codrescu, che ha lavorato per 21 anni al DSP Hexagon trasformandolo da semplice coprocessore a unità per il calcolo neurale e l’IA.
Chiude Guy Therien, 31 anni in Intel e da oltre un anno in Qualcomm per supervisionare la parte di efficienza termica e consumi.
In questo lungo articolo cercheremo di raccontarvi tutto quello che ci è stato detto in due giorni davvero intensi a livello di informazioni.
31 miliardi di transistor per un processore “all inclusive”
Il nuovo Snapdragon X2 Elite è più di una evoluzione: nonostante sia possibile rivedere il tipico scherma a blocchi di ogni processore Qualcomm, ogni singolo elemento che lo compone è stato rivisto per soddisfare quelli che sono i requisiti di un computer.
Qualcomm realizzerà tre differenti versioni dello Snapdragon X2 Elite: ci saranno due versioni con CPU a 18 core e quattro “slice” GPU e una versione con CPU a 12 core e tre “slice” GPU. Più sotto entreremo nei dettagli.
Nel singolo chip, grande quanto un francobollo, trovano posto oltre 31 miliardi di transistor realizzati con il processo produttivo a 3 nanometri più avanzato: dovrebbe essere N3X, la versione di N3P che supporta tensioni operative più alte (1.2v) permettendo così di raggiungere frequenze di clock più elevate. Il core Oryon di terza generazione su Snapdragon X2 Elite Extreme raggiunge infatti i 5 GHz di clock.
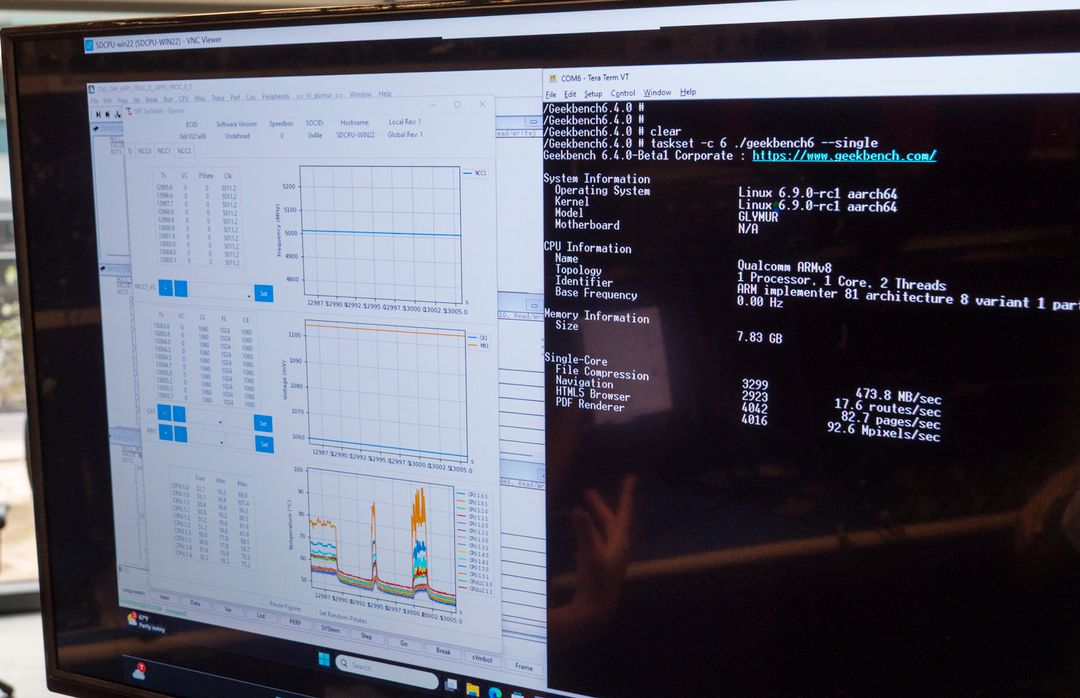 In laboratorio, sbirciando sui monitor durante le misure di consumo, abbiamo letto chiaramente un valore di tensione più alto di quello classico, a conferma che dovremmo trovarci davanti ad un processo che nessuno ha ancora usato
In laboratorio, sbirciando sui monitor durante le misure di consumo, abbiamo letto chiaramente un valore di tensione più alto di quello classico, a conferma che dovremmo trovarci davanti ad un processo che nessuno ha ancora usato
Al centro del SoC troviamo la CPU con 18 core Oryon di terza generazione divisi in tre cluster, ciascuno ottimizzato per un compito specifico. I due cluster principali integrano 6 core ad alte prestazioni ciascuno che raggiungono i 5 GHz in modalità dual-core boost.
Qualcomm dichiara un incremento notevole rispetto allo Snapdragon X Elite, +39% in single-core e +50% in multi-core.
Un secondo gruppo di 6 core è dedicato al bilanciamento tra consumi e potenza, ma restano comunque core ad alte prestazioni.

Rispetto alla prima versione, che usava 12 core identici, Qualcomm ha pensato di differenziare i core (poi vedremo come) ma ha mantenuto la scelta di non avere un cluster “efficiency” dedicato: il lavoro “always-on” è gestito dal Sensing Hub, non dalla CPU. Rispetto ad uno smartphone, che ha uno stato di “stand-by” più attivo con notifiche, always-on display e task che vengono eseguiti quando il telefono è in tasca, nel caso dei notebook lo stand-by ha meno esigenze.
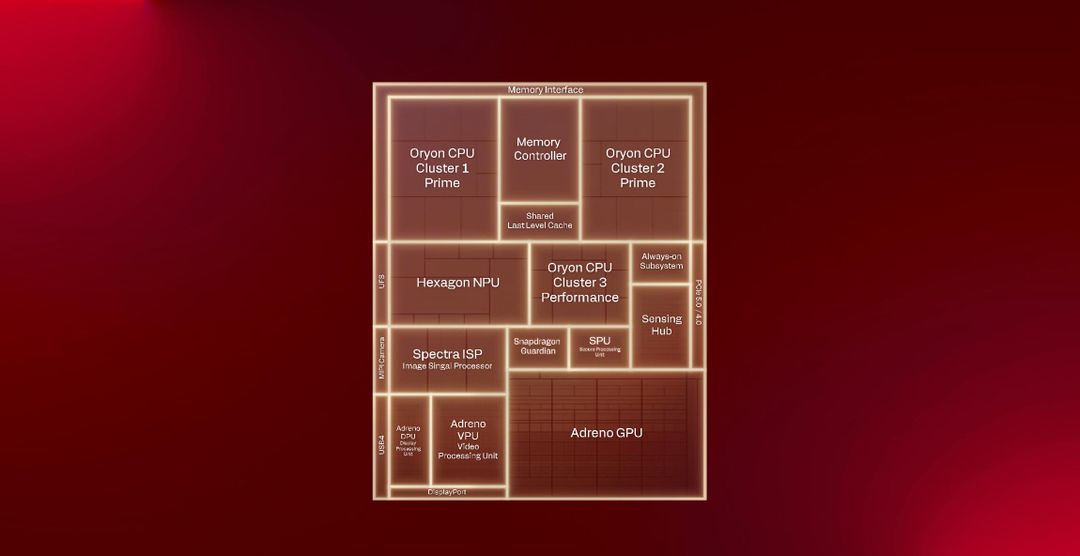
Il comparto grafico è uno dei settori dove Qualcomm compie il salto più evidente. La nuova GPU Adreno X2-90 raggiunge prestazioni fino a 2,3 volte superiori rispetto alla generazione precedente, e qui il miglioramento deriva da tre interventi chiave: un’architettura più ampia e parallela, percorsi di memoria dedicati alle operazioni grafiche e una gestione termica che mantiene clock elevati più a lungo.
A fianco della GPU è stato inserito un nuovo Display Processing Unit che apre a scenari da workstation: possono essere gestiti fino a 4 monitor 4K a 144 Hz oppure oppure 4 display 5K a 60 Hz.
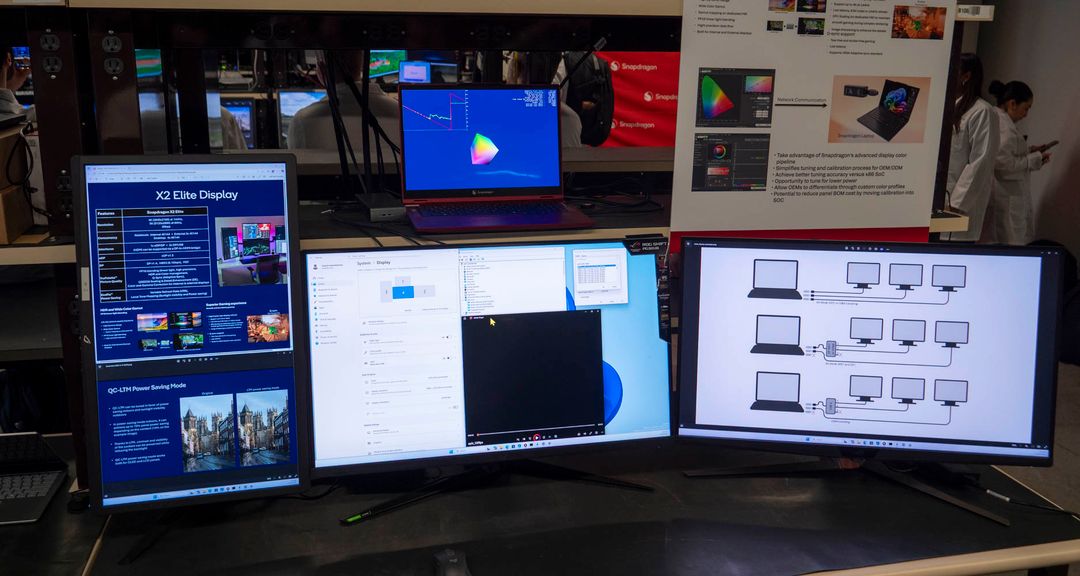
Qualcomm, in laboratorio, ci ha spiegato che non solo si sono preoccupati di gestire più monitor per chi ha la necessità di gestire configurazioni multiple ma ha anche trovato un modo facile per abilitare la calibrazione hardware di fabbrica su ogni display. Ha creato una interfaccia hardware che i produttori possono usare per salvare direttamente nella Display Processing Unit la calibrazione dello schermo che può essere eseguita su ogni singolo modello durante la fase di produzione. Sta al produttore decidere se implementarlo, ma avrebbe costi bassissimi e ogni display avrebbe una accuratezza cromatica che oggi solo i laptop pensati per i content creator, e venduti come tali possono vantare.

In un mondo dove tutto ormai ruota attorno all’IA, e dove si cerca di dare potenza di calcolo per gestire al meglio l’IA locale (a breve quella in cloud sarà tutta a pagamento) il Neural Processing Unit del nuovo Snapdragon X2 Elite è forse uno degli elementi più impressionanti: Qualcomm indica un miglioramento del 78% rispetto alla generazione precedente.
La memoria riveste poi un ruolo fondamentale per un computer, e il sottosistema memoria dello Snapdragon X2 è progettato per evitare colli di bottiglia: nella versione Extreme ha un bus a 192 bit e una larghezza di banda fino a 228 GB/s (+69%, M5 di Apple ha 153GB/s), supporta memorie LPDDR5X fino a 9523 MT/s e può essere ordinata a Qualcomm con 128 GB indirizzabili on-package.
Come avevamo visto allo Snapdragon Summit la versione Extreme del chip avrà le memorie saldate sul chip come gli Apple Silicon e Lunar Lake, e la versione che Qualcomm venderà ai produttori avrà 48 GB di memoria a bordo, tre moduli da 16 GB, ma volendo un produttore potrebbe ordinare versioni da 64 GB, 96 GB o 128 GB.

Abbiamo chiesto a Qualcomm se la scelta di avere memorie saldate sul processore, quindi è lei a dover acquistare le memorie rivendendo il chip ad un prezzo più alto, non sia controproducente in un periodo dove il costo della RAM non è stabilissimo ma ci dicono che non dovrebbero esserci grossi problemi visto che la versione Extreme sarà comunque limitata. I produttori, lo sappiamo, non hanno apprezzato la scelta di Intel di saldare le RAM sul chip e per questo motivo Qualcomm propone le altre due versioni “nude”, con i banchi di RAM da acquistare a parte.
Per permettere a tutti i cluster di accedere agli stessi dati senza doverli spostare dalla RAM Qualcomm ha implementato una cache condivisa da 9 MB con banda aumentata del 70% rispetto a quella del primo X Elite: cluster CPU e cache sono uniti da una Custom Spine Coherent Fabric che garantisce interconnessione a larga banda con latenza minima.
Sullo Snapdragon X2 Eite troviamo, come abbiamo scritto, molti elementi già conosciuti perché usati in questi anni sui processori per smartphone: uno dei componenti più peculiari del SoC è ad esempio il Qualcomm Sensing Hub, un sottosistema autonomo che resta attivo anche quando il PC è in sospensione.

Questo integra una doppia micro-NPU (6x più potenti della gen precedente) che viene usata per gestire elaborazioni neurali a computer spento: si potrà attivare il computer con un comando vocale o attivare lo schermo ogni volta che una persona passa davanti alla webcam se la cover è aperta.
C’è anche lo Spectra ISP, che porta la fotografia computazionale sul PC. Secondo Qualcomm è finalmente riuscita con Snapdragon X a pareggiare la qualità video offerta dalla webcam PC con quella dei Mac, che da anni è il riferimento del settore.

Lo Spectra ISP a 18 bit supporta una doppia webcam da 36 megapixel a 30 fps, nel caso in cui un produttore voglia aggiungere una webcam stereoscopica 3D, o una singola camera con sensore da 64 megapixel e con Zero Shutter Lag; per la ripresa video arriva a gestire dalla webcam flussi video 1080p fino a 120 fps.
Il sistema di gestione può pilotare contemporaneamente fino a 4 telecamere, incluse anche quelle a infrarossi e quelle RGB usate per l’autenticazione biometrica.

Qualcomm ha fatto analisi dettagliate delle diverse situazioni di ripresa che si verificano durante le videoconferenze con strumenti come Teams o Zoom, e si è accorta che i problemi principali sono gli artefatti (i produttori usano moduli piccoli e rumorosi), la gestione del controluce e il consumo del processore. Per gestire l’effetto “bokeh” che tante persone usano per non far vedere dove sono, o nascondere particolari di casa se sono in smart working, molti processori datati divorano la batteria.
Sulla nuova generazione è stata quindi integrata una nuova pipeline di riduzione del rumore AI, che combina analisi spaziale e temporale usando algoritmi che compensano i movimenti tra i frame oltre al multi-frame HDR, utile per compensare il controluce dovuto a finestre dietro la schiena. Il bokeh gestito dallo Snapdragon, secondo Qualcomm, consuma il 40% in meno grazie alla collaborazione tra ISP e micro-NPU del Sensing Hub.
 I test di qualità e riduzione di rumore con la webcam nei laboratori a San Diego
I test di qualità e riduzione di rumore con la webcam nei laboratori a San Diego
Qualcomm aspira a proporre la versione Extreme del suo nuovo chip ai content creator, e sebbene Premiere sia ancora in versione “beta” su ARM gli ingegneri di San Diego si sono portati avanti integrando una nuova VPU dual-core che permette l’editing 8K senza carico su GPU e CPU.
La Video Processing Unit introduce un modulo di encoding 8K 30fps e un modulo di decodifica che gestisce due stream 8K a 60fps insieme, moduli che supportano tutti i codec in hardware, AV1 incluso. Secondo Qualcomm non solo tutta la pipeline video può essere gestita in HDR a 10 bit a quelle risoluzioni, ma si può anche fare encoding e decoding simultaneamente per supportare gli streamer che usano soluzioni come OBS per prendere flussi video 4K da camere esterne per unirle alla sequenza di gioco e inviare poi il flusso finale, compresso in tempo reale, su una piattaforma come Twitch.

Presente anche il supporto al codec APV (Advanced Professional Video), anche se è solo un supporto software senza accelerazione hardware che invece è presente su Snapdragon 8 Elite Gen 5. Il motivo ce lo aveva spiegato Jude Heapp di Qualcomm allo Snapdragon Summit: X2 era stato “disegnato” prima. APV, lo ricordiamo, è il codec professionale “open” e senza costi di licenza che diverse aziende stanno supportando per cercare di sostituire il ProRes di Apple, che è proprietario.
Lato ingressi e uscite troviamo un controller USB4 a 40 Gbps (fino a 3 porte), PCIe 5.0 (12 lane) e PCIe 4.0 (4 lane), un doppio controller NVMe PCIe 5.0 che può supportare anche un RAID oltre alla possibilità, per i prodotti meno costosi, di usare storage UFS 4.0. C’è anche il controller per lo slot SD Express – SDXC.

Qualcomm per la ricarica si affida alla sua soluzione Quick Charge 5+ che è però pienamente compatibile con Power Delivery, aggiunge solo più livelli di protezione. Sarà possibile caricare i portatili con velocità fino a 140 W (20V a 7A) usando sia caricatori QuickCharge sia caricatori Power Delivery usando la porta USB-C.

Snapdragon X2 Elite non include né il modem 5G né il modulo Wi-fi: Qualcomm ovviamente li propone come abbinata, ma abbiamo visto in questi anni che, nonostante da tempo l’azienda di San Diego punti sulla possibilità di avere i PC “sempre connessi”, i produttori poi scelgono di non integrare il modem per questione di costi.
L’X75 5G, modem che permette download fino a 10 Gbps e upload fino a 3.5 Gbps, viene venduto come modulo M.2 PCIe 3.0 e può essere aggiunto solo se serve, anche nel caso di configurazione “custom” dell’utente durante l’ordine del computer. La scelta è sensata, e volendo si può aggiungere anche aftermarket.
Per la connettività viene invece proposto il sistema FastConnect 7800 che offre Wi-Fi 7 fino a 5.8 Gbps con latenza minima di 2 ms, multi-link simultaneo e doppio Bluetooth.

Snapdragon Guardian, un modem 4G con eSim pagata da Qualcomm per trovare il PC rubato
C’è una funzione che merita più di una parola, ovvero Snapdragon Guardian: Qualcomm doterà i laptop di una funzionalità simile a Find My di Apple che permetterà di localizzare il portatile in caso di furto. Lo farà usando la rete 4G con un modem 4G low cost e una piccola embedded SIM dotata di traffico dati pagato, traffico che sarà usato solo ed esclusivamente per la localizzazione, non può essere usato per navigare.
Abbiamo scritto nel precedente paragrafo che i laptop non saranno tutti dotati di un modem 5G, ma Guardian usa un modem 4G differente, che costa al produttore circa 3 dollari: secondo l’azienda non c’è motivo per il quale un produttore debba rinunciare a questa caratteristica sicuramente richiesta a livello di sicurezza. Se il produttore deciderà di mettere il modem 5G, Guardian funzionerà su quest’ultimo.
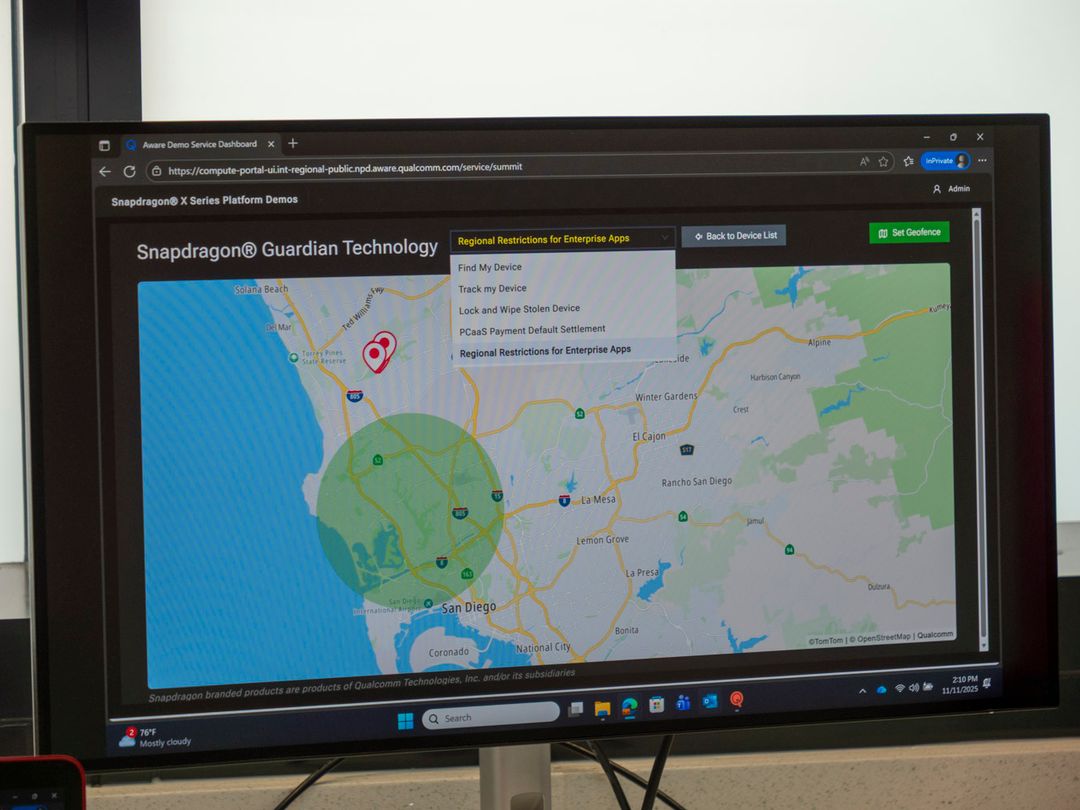
Se a livello consumer Guardian permette di localizzare il PC in caso di furto, gestendo anche un eventuale blocco e la cancellazione dei dati da remoto, in ambito business può essere usato anche per la diagnosi a distanza o per applicare un recinto geografico (geofencing) alle applicazioni: una azienda potrebbe decidere che certe app aziendali funzionano solo se il computer si trova all’interno di una certa area.
Il core Oryon gen 3 nel dettaglio: 5 GHz di velocità e cache enorme
Qualcomm, come abbiamo visto, ha optato per una configurazione inusuale con 18 core totali, ma non tutti i core sono uguali. L’azienda ha implementato infatti cluster distinti, ciascuno ottimizzato per uno scopo specifico.
I primi sono due cluster “Prime” da 6 core ciascuno, progettati per le massime prestazioni: hanno frequenza base di 4.4 GHz e possibilità di boost fino a 5.0 GHz in modalità dual-core. Ogni cluster Prime dispone di 16 MB di cache L2 condivisa, per un totale di 12 core ad alte prestazioni.

A questi si affianca un cluster “Performance” da 6 core, che opera a frequenza base di 3.6 GHz, con 12 MB di cache L2 condivisa. Questi core sono ottimizzati per l’efficienza energetica e possono operare anche sotto i 2W di potenza.
La cache L2 totale ammonta a 44 MB, esattamente il doppio rispetto alla generazione precedente: questo non è un dettaglio secondario, perché la cache funziona come una dispensa vicina alla cucina e più è capiente e veloce da raggiungere meno volte il processore deve andare fino alla memoria principale, che è molto più lenta, per recuperare i dati necessari.
Qualcomm ci ha raccontato i core Prime con due parole: “wider and faster”, ovvero più larghi e più veloci, ma cosa significa in pratica?
Con “larghi” si riferisce ai decoder, quei componenti della CPU che trasformano le istruzioni del programma in operazioni eseguibili dal processore. Un decoder “a 9 vie” può processare 9 istruzioni contemporaneamente per ogni ciclo di clock, e per fare una analogia è un po’ come avere 9 casse aperte al supermercato invece di 3: più casse significano più clienti serviti nello stesso tempo e meno code.
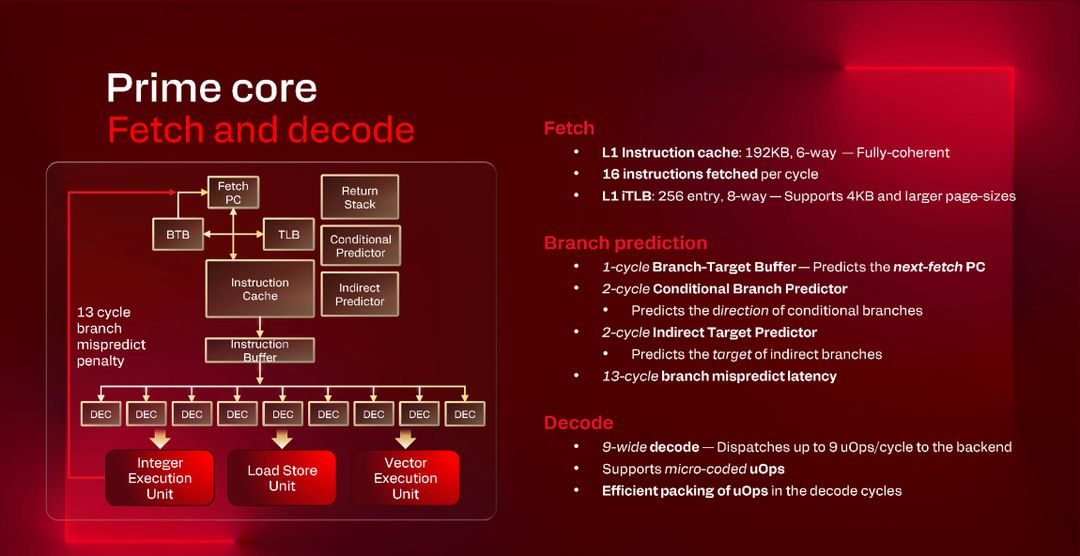
Se i core Prime hanno un decoder a 9 vie, i core Performance ne hanno uno più stretto, probabilmente a 6-7 vie, anche se Qualcomm non ha specificato il numero esatto. Questo permette ai Prime di alimentare più velocemente le unità di esecuzione, mantenendo il processore costantemente occupato.
Enorme la cache: quella di primo livello dei core Prime è da 192 KB, una dimensione notevole se confrontata con la concorrenza: Apple M5 si ferma a 128 KB, mentre Intel Core Ultra e AMD Zen 5 hanno entrambi solo 32 KB.
I programmi di oggi sono enormi: Chrome, Photoshop, Visual Studio hanno milioni di linee di codice e con una cache così grande il processore può tenere in memoria più parti del programma attivo, evitando costosi accessi alla memoria principale che possono richiedere come “sacrificio” centinaia di cicli di clock.

La mano dei chip designer che hanno progettato in passato i processori Apple A e M si vede nel modo in cui sono stati progettati alcuni elementi dei core, non solo per la larghezza del front-end, ma anche nella profondità della finestra out-of-order e nell’uso aggressivo di tecniche come il register renaming su larga scala, scelte tipiche delle architetture ARM ad alte prestazioni di scuola “Apple/Nuvia”.
I processori moderni infatti non eseguono le istruzioni nell’ordine in cui compaiono nel codice, le riordinano dinamicamente per evitare attese inutili e massimizzare l’efficienza.
Consideriamo un esempio:
- Caricare dalla memoria il valore A (operazione lenta: circa 100 cicli).
- Calcolare B = C + D (operazione immediata: 1 ciclo).
- Calcolare E = A + 10 (dipende dal valore A).
- Calcolare F = G x H (3 cicli).
Una CPU “in-order” eseguirebbe le istruzioni in ordine, rimanendo ferma per quasi 100 cicli in attesa del caricamento di A, mentre una moderna CPU out-of-order carica A in background e nel frattempo esegue tutte le operazioni che non dipendono da A: prima B, poi F.
Solo quando A è finalmente disponibile conclude il calcolo e ricava il valore di E. Invece di 104 cicli, l’intera sequenza richiede circa 100 cicli, il tempo richiesto per il caricamento di A, il resto del lavoro viene “ammortizzato” durante l’attesa.
Apple è la regina dell’Out Of Order moderno: i suoi core sono in assoluto quelli più “lavorano mentre aspettano” e parte della velocità degli Apple Silicon è dovuta alla velocità con cui la sua struttura riesce a colmare ogni buco di attesa causato dalla latenza della RAM.
Con oltre 400 registri fisici (Apple ne dovrebbe avere sui core più recenti 700) il core Oryon ha un Out Of Order molto aggressivo, simile per filosofia a Apple e superiore alle architetture AMD/Intel lato efficienza per watt.

Le unità di esecuzione sono il vero muscolo del processore. I core Prime dispongono di 6 unità ALU per operazioni intere e 4 unità vettoriali per calcoli floating-point, e ciascuna può processare 4 numeri in virgola mobile FP32 per volta.
A 5 GHz di clock, la velocità di picco, ogni core Prime può teoricamente eseguire 160 miliardi di operazioni floating-point al secondo, che corrispondono a 160 GFLOPS. Moltiplicato per 12 core Prime otteniamo circa 1.9 TFLOPS solo dalla CPU.
A fianco di queste unità è presente, per ogni cluster, un Qualcomm Matrix Engine, un acceleratore AI dedicato che lavora fianco a fianco con la CPU. È ottimizzato specificamente per le moltiplicazioni di matrici, che sono il cuore di tutti gli algoritmi di machine learning: può lavorare con elementi numerici a 64 bit, griglie 8×8, registri vettoriali da 512 bit e vari formati numerici tra cui BF16, FP16, FP32, INT8, INT16 e INT32.

Se qualcuno si stesse chiedendo perché integrarlo nella CPU invece di affidarsi solo alla NPU dedicata, ci sono tre vantaggi significativi. Primo la latenza è bassissima, perché il Matrix Engine accede alla stessa cache L2 dei core CPU. Secondo offre grande flessibilità, e può accelerare piccole porzioni di codice AI senza dover trasferire dati alla NPU, operazione che richiederebbe tempo. Terzo è molto efficiente dal punto di vista energetico, perché opera in un dominio di clock separato e può rallentare senza impattare la CPU principale.
Quando la CPU lavora a 5 GHz il Matrix Engine può eseguire letture e scritture a 64 byte con la cache L2, fornendo un’enorme larghezza di banda per le operazioni matriciali che caratterizzano i moderni modelli di intelligenza artificiale. Gli acceleratori matriciali (SME) sono presenti anche nell’architettura ARM classica ma Qualcomm, come Apple, ha sviluppato una sua soluzione proprietaria.
Nei mesi scorsi abbiamo parlato di come Apple con A19 abbia implementato la Memory Integrity Enforcement per proteggere il sistema da attacchi di memoria e attacchi speculativi, e anche Oryon ora implementa un’architettura di sicurezza che protegge secondo Qualcomm contro tutti gli attacchi noti degli ultimi 10 anni.
Apple alza la barriera contro gli attacchi alla memoria. iPhone 17 blindato contro gli spyware governativi
Negli ultimi dieci anni sono stati scoperti numerosi attacchi che sfruttano l’esecuzione speculativa delle CPU e Qualcomm ha implementato protezioni specifiche contro Spectre, che sfrutta la predizione dei branch, Meltdown che permette accesso non autorizzato alla memoria kernel, PACMAN che attacca la pointer authentication, Straight-Line Speculation che sfrutta l’esecuzione speculativa lineare, e Augury che usa attacchi timing sui data cache.
Una novità interessante che X2 Elite eredita dal’architettura ARM è il Memory Tagging, che funziona come un sistema di “lucchetto e chiave” per la memoria. Ogni blocco di memoria ha un “tag”, come un lucchetto, e ogni puntatore ha una “chiave”: la CPU verifica che chiave e lucchetto coincidano prima di ogni accesso. Questo protegge da use-after-free, quando si usa memoria già deallocata e dal classico buffer overflow, che sovrascrive memoria adiacente ed è spesso sfruttato per attacchi ai sistemi.
Mentre i core Prime sono progettati per le prestazioni massime, i core Performance sono ottimizzati per il bilanciamento tra prestazioni ed efficienza.
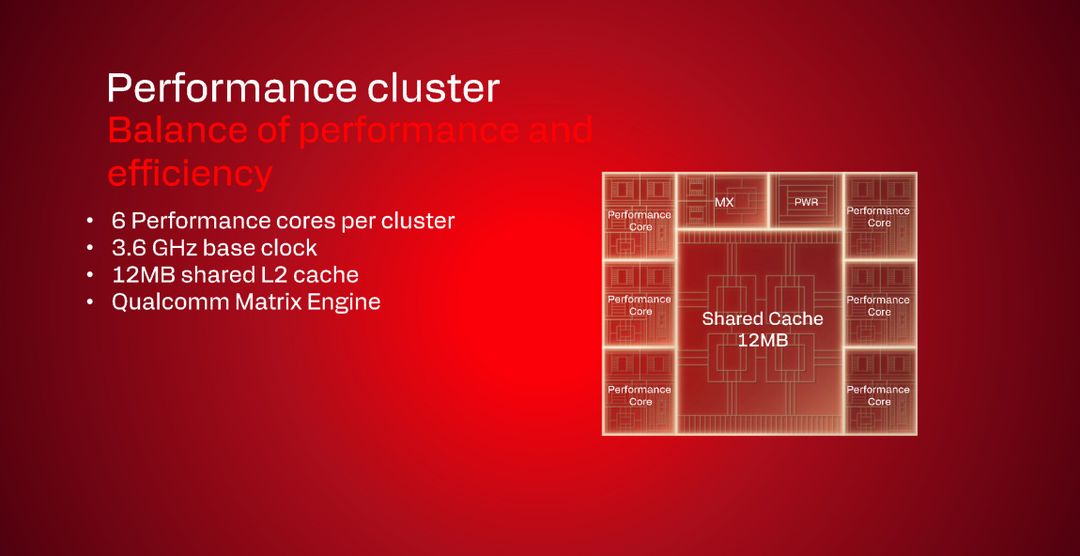
Condividono la stessa microarchitettura out-of-order dei Prime, ma con implementazione diversa. Il decoder è più stretto, probabilmente a 6-7 vie invece di 9, la finestra out-of-order è più piccola con meno istruzioni in volo contemporaneamente, le cache sono più contenute con 12 MB di L2 condivisi invece di 16 MB e la frequenza è più bassa a 3.6 GHz invece di 4.4-5.0 GHz.

Il risultato di queste scelte è che questi core possono operare efficacemente sotto i 2W di potenza, rendendoli ideali per carichi di lavoro prolungati come navigazione web, riproduzione video, lavoro d’ufficio e task in background.
Qualcomm li posiziona come core che offrono la “migliore efficienza energetica ai livelli di prestazioni a basso consumo” mantenendo comunque un’architettura moderna e performante.
Le prestazioni misurate: il salto è impressionante
I benchmark sintetici della nuova CPU con Geekbench 6.5 mostrano un salto prestazionale impressionante. C’è un incremento di velocità del 39% a parità di consumo rispetto al modello precedente e una riduzione del 43% nel consumo energetico a parità di prestazioni.
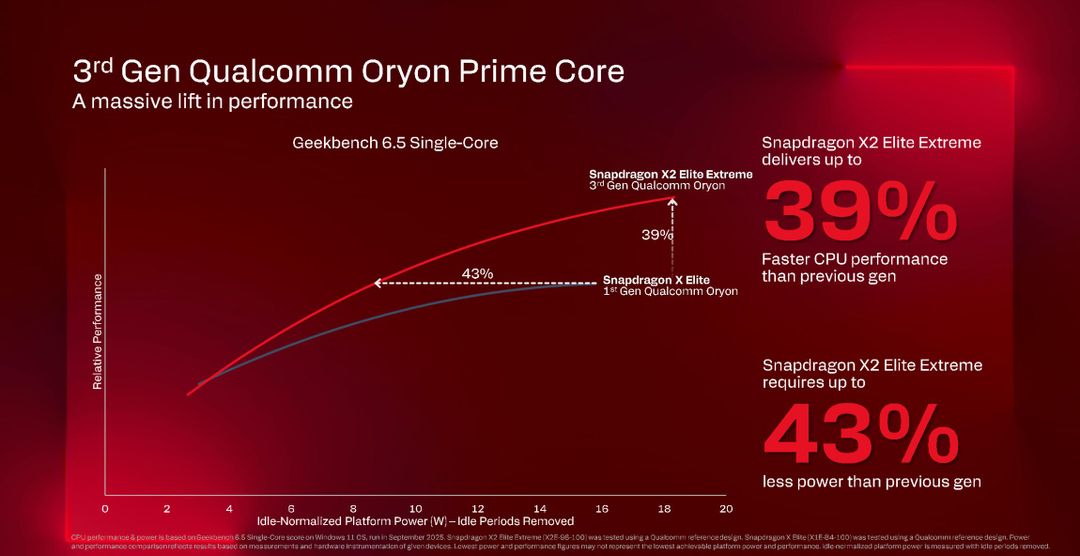
Come è stato raggiunto questo risultato lo abbiamo visto prima: è una combinazione di fattori che lavorano in sinergia a partire da una frequenza più alta, da 4.0 a 5.0 GHz, che offre da sola un guadagno teorico del 25%.
L’IPC, cioè le istruzioni per ciclo, sono migliorate grazie al decoder più largo a 9 vie, ai predittori migliorati, alle cache più grandi con quella da 192 KB per le istruzioni e 96 KB per i dati e al prefetching più aggressivo.
Con la GPU Adreno X2-90 il ray tracing arriva su Windows ARM
La GPU Adreno X2 utilizza la stessa architettura slice-based vista anche su Snapdragon 8 Elite, dove ogni “slice” è un’unità di rendering completa e indipendente. Potete pensare agli slice come stazioni di lavoro autonome: più ne avete, più lavoro potete fare in parallelo.
La configurazione completa delle versioni con 18 core GPU prevede 4 slice totali, e ogni slice 2 shader processors, 512 ALU FP32, 128 KB di cluster cache e 5.25 MB di Adreno High Performance Memory, una memoria ultra-veloce.

La versione da 12 core ha solo 3 slice, e secondo Qualcomm si perde circa il 15% di prestazioni: la potenza non scala in modo proporzionale all’aumentare o al calare del numero delle “fette”.
Se sommiamo tutti gli elementi di calcolo presenti nella versione top di gamma della Adreno X2-90, la GPU nella sua forma più evoluta dispone di 2048 ALU FP32, 128 texel per ciclo di texturing, 21 MB di Adreno High Performance Memory on-chip, 2 MB di cache di secondo livello unificata, supporto per memorie LPDDR5X a 9523 Mbps (228 GB/s di banda) e può operare a frequenze fino a 1.85 GHz.
Qualcomm ci spiega che a 1.85 GHz le 2048 ALU forniscono circa 7.6 TFLOPS di potenza computazionale: per dare dei riferimenti utili la PlayStation 5 offre circa 10 TFLOPS, la Xbox Series S circa 4 TFLOPS, la Steam Deck circa 1.6 TFLOPS e l’Adreno X1 della generazione precedente circa 3.3 TFLOPS. Ricordiamo che ci troviamo davanti ad una piattaforma che non raggiunge i consumi di una console, consuma meno della metà.
La vera rivoluzione dell’Adreno X2 è però il ray tracing hardware dedicato, una prima assoluta per le GPU Qualcomm destinate ai PC. Il ray tracing, lo ricordiamo, simula come la luce realmente si comporta nel mondo fisico: traccia raggi di luce che rimbalzano sugli oggetti, calcola riflessi accurati in tempo reale e gestisce l’illuminazione globale in modo realistico.

Ogni slice dell’Adreno X2 ha Ray Tracing Units dedicate che accelerano operazioni specifiche: senza hardware dedicato servirebbero centinaia di cicli di clock per capire in che modo i raggi colpiscono i vari elementi della scena, mentre ora le unità di ray-box e ray-triangle intersection integrate da Qualcomm calcolano matematicamente dove i raggi colpiscono gli oggetti, completando l’operazione in pochi cicli invece di decine.
Il supporto software include DirectX Raytracing e Vulkan Ray Pipeline, e questo significa che i giochi esistenti che già supportano il ray tracing su altre piattaforme funzioneranno immediatamente anche su Snapdragon senza necessità di modifiche da parte degli sviluppatori.
Al momento le prestazioni non sono tuttavia quelle che ci saremmo aspettati, almeno in ray tracing: abbiamo provato Cyberpunk usando le stesse impostazioni che abbiamo usato per la prova di Apple M5 e mentre il processore Apple tiene i 28/29 fps, lo Snapdragon X2 Elite arriva a 7/8 fps. Secondo gli ingegneri Qualcomm è già tanto se allo stato attuale dei driver il gioco gira in ray tracing: mancano mesi al lancio e tutta la parte driver è ancora da finalizzare.

La gpu Adreno dello Snapdragon X2 Extreme è anche la prima GPU ARM con supporto completo alle DirectX 12.2 Ultimate, il che è significativo perché mette la piattaforma Qualcomm sullo stesso piano delle GPU discrete moderne.
Lo Shader Model 6.8 include funzionalità chiave per i giochi moderni come il Mesh Shading, fondamentale per tecnologie come Nanite di Unreal Engine 5 e il Variable Rate Shading, che permette di renderizzare il centro dello schermo a qualità massima e la periferia a risoluzione ridotta, migliorando le performance del 20-30% senza perdita visibile di qualità. Il VRS sfrutta il principio che l’occhio umano ha risoluzione massima solo nella zona centrale della visione, e la zona periferica può quindi essere trascurata.
Per migliorare le prestazioni della grafica integrata Qualcomm ha dotato la GPU di una memoria dedicata, l’Adreno High Performance Memory: sono 21 MB di SRAM on-chip, con 5.25 MB per ogni slice.

Questa memoria è cruciale per le prestazioni complessive della GPU: accedere alla RAM principale costa 100-200 cicli di clock, mentre l’AHPM ha una latenza di circa 50 cicli e soprattutto una banda di 4 TB al secondo contro i 228 GB al secondo della RAM. Stiamo parlando di una velocità 20 volte più superiore, una scheggia.
La GPU adotta un approccio Tile-Based, dividendo lo schermo in piccoli riquadri (tile) ed elaborando ciascun tile interamente nella velocissima memoria locale interna, scrivendo il risultato nella RAM di sistema solo a lavoro finito. Questo approccio riduce il traffico verso la memoria principale del 70-80%, traducendosi in minore consumo energetico.
Qui entrano in gioco i 21 MB di memoria Adreno: funzionano come un enorme polmone che permette di mantenere on-chip non solo i dati dei tile attivi, ma anche gran parte delle texture e delle geometrie usate più di frequente. In questo modo, operazioni complesse come l’anti-aliasing e il post-processing possono avvenire attingendo i dati da questa memoria ultra-veloce e a bassa latenza, evitando il collo di bottiglia della RAM condivisa.
Abbiamo chiesto a Qualcomm per quale motivo non hanno dotato la GPU di acceleratori neurali, e come hanno intenzione di gestire eventuali motori di upscaling AI per i giochi, ma ci viene spiegato che al momento pensano di abbracciare la soluzione Microsoft Super Resolution. Non c’è alcuna previsione al momento per soluzioni di upscaling o frame generation proprietarie. Non è da escludere però che possa venir supportata dai driver una soluzione open di qualche con corrente.
Per chi gioca arriverà a breve anche il pannello di controllo, questo anche per i prodotti attuali. Era una richiesta degli utenti.
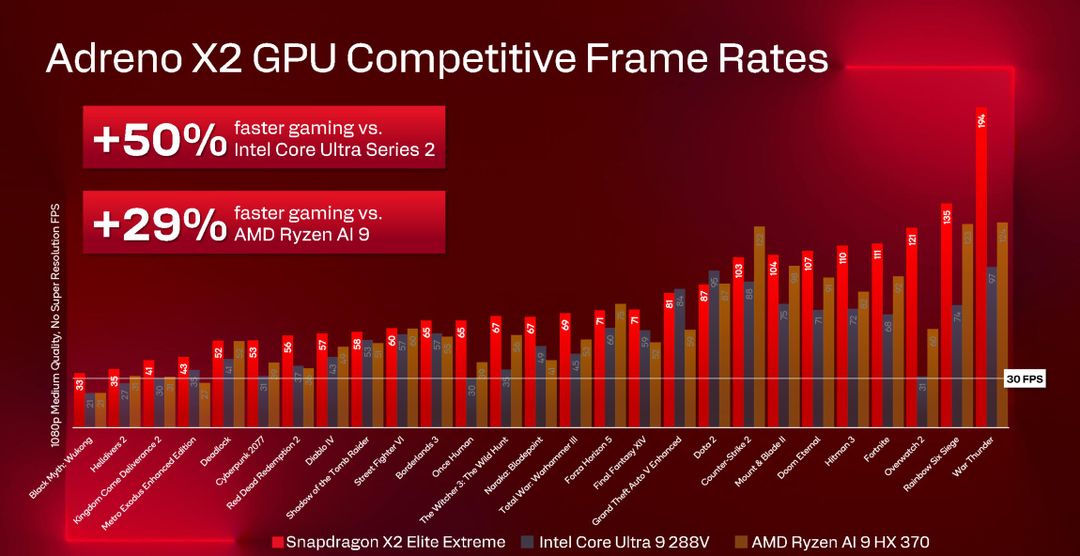
Le prestazioni grafiche: il confronto con Intel e AMD
Confrontato con l’Intel Core Ultra Series 2, lo Snapdragon X2 Elite Extreme mostra un vantaggio del 50% nella performance media a 1080p con qualità media, e domina nei titoli moderni come Cyberpunk 2077, Doom Eternal e Forza Horizon 5.
Contro l’AMD Ryzen AI 9 HX 370 il vantaggio è del 29% sempre a 1080p qualità media, con Qualcomm che vince specialmente sui titoli DirectX 12 moderni che sono meglio ottimizzati.
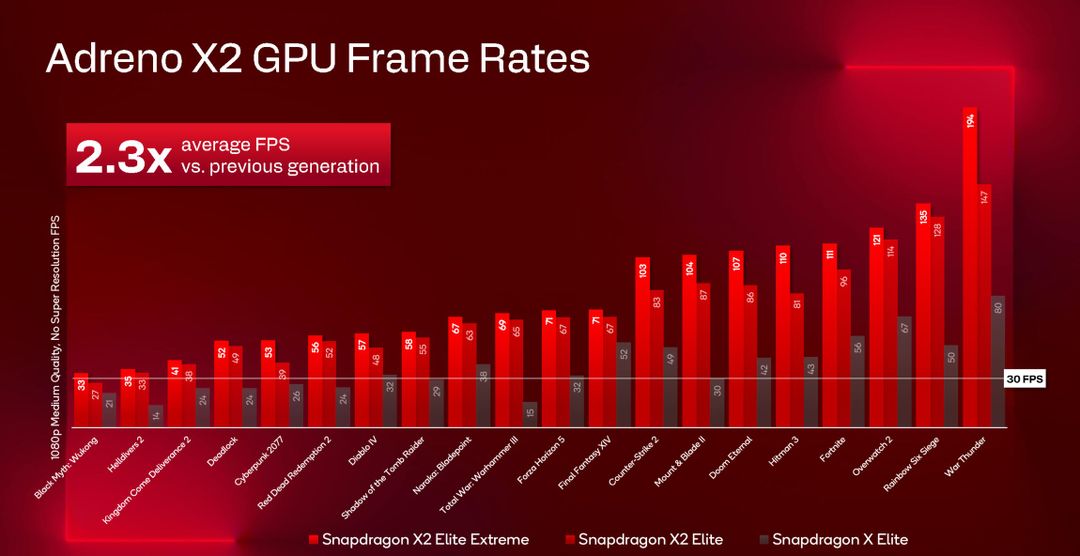
Qualcomm mostra anche il confronto con la generazione precedente, e si vede chiaramente come la potenza della sola GPU sia praticamente raddoppiata: si fanno il doppio degli FPS. Si nota anche come sia aumentato il parco di titoli giocabili.
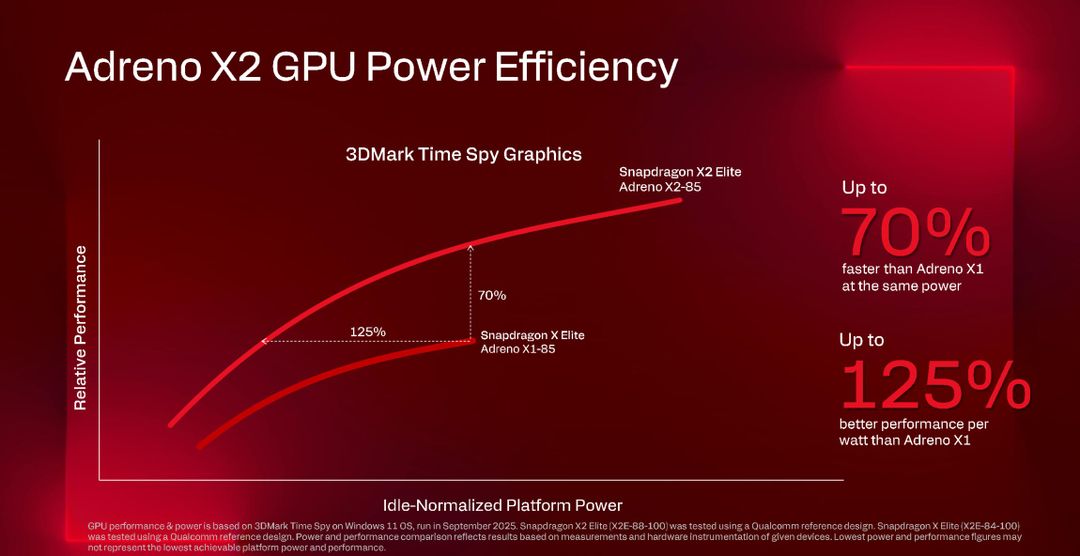
Qualcomm a supporto dei benchmark in gioco dichiara che la sua GPU è il 70% più veloce a parità di consumo rispetto alla generazione precedente, e parla di un miglioramento del 125% in performance per watt.
In termini pratici questo significa più autonomia a batteria durante il gaming, che è il punto debole delle soluzioni oggi basate su GPU dedicate come quelle NVIDIA, meno calore generato quindi laptop più silenziosi ma soprattutto la possibilità di creare form factor più sottili perché serve meno spazio per il sistema di raffreddamento.
Il problema del gaming su Windows ARM, lo sappiamo bene, riguarda non tanto le prestazioni ma è soprattutto la compatibilità con diversi titoli e il supporto dei sistemi anti-cheat che operano a livello kernel, la stessa barriera contro la quale al momento si è scontrata Steam con Proton e SteamOS.
Qualcomm ha lavorato direttamente con i principali fornitori per garantire supporto nativo: Tencent ACE Anti Cheat, Roblox, Denuvo by Irdeto, InProtect GameGuard, BattleEye e Uncheater sono ora tutti supportati nativamente.
Giochi popolari come Fortnite, PUBG e Apex Legends funzionano senza workaround o hack, esattamente come su piattaforme x86 tradizionali. Fortnite è da poco disponibile e funziona abbastanza bene: su X2 gira senza alcun problema a 120 fps e massimo dettaglio.

Durante la nostra visita inoltre ci è stato spiegato perché quella che viene chiamata “emulazione” impatta davvero poco sui giochi.
Il codice del gioco, anche quando non è compilato nativamente per ARM, viene tradotto automaticamente dal formato x64 al formato ARM64EC e questo viene fatto una sola volta: dopo aver riscritto il codice l’impatto a livello di performance è minimo.
La parte grafica, poi, viene gestita dai driver Adreno ARM64EC sviluppati in modo nativo per l’architettura ARM e questo permette alle chiamate DirectX di essere processate senza passaggi intermedi superflui, e consente di sfruttare appieno la GPU: se la parte “cpu” del codice è trascritta, la parte grafica è invece gestita nativamente. Secondo Qualcomm è quasi inutile chiedere giochi “nativi” perché tanto ci sono componenti di Steam, per fare un esempio, che non lo sono e che comporterebbero l’uso dell’emulatore. L’emulazione, lo abbiamo già visto con Proton, non è oggi un collo di bottiglia. Al massimo lo è il sistema operativo, ma non è escluso che in futuro l’azienda possa supportare oltre a Windows anche Linux.
Alla nostra domanda specifica, supporterete Bazzite, Kedar Kondap ci ha detto sorridendo: “Non rilascio commenti”.

Non solo giochi: una GPU pensata anche per 3D e content creator
La GPU non è utile solo per il gaming: il Windows Compute Runtime offre supporto nativo per il calcolo general-purpose, permettendo di usare la potenza della GPU per accelerare applicazioni professionali.
Adobe Creative Suite con Photoshop, Premiere e After Effects, DaVinci Resolve per l’editing video professionale, Blender per la modellazione 3D, e varie applicazioni di machine learning possono tutte sfruttare la GPU e Qualcomm si è mossa in questa direzione. Non ci hanno voluto dire che punteggio spunta su Blender Benchmark, “lo vedrete” ci hanno detto, ma secondo l’azienda le performance sono ottime.
Da quanto abbiamo visto è una buona GPU, ma non è una GPU miracolosa ed è giusto accennare anche alle limitazioni intrinseche dell’architettura. La memoria LPDDR5X ad esempio è condivisa con la CPU e altri componenti del sistema: questo significa che la larghezza di banda è condivisa, con un limite massimo di 228 GB al secondo che deve essere spartito tra tutti i componenti che ne hanno bisogno. Questo limite è inoltre legato alla versione Extreme, che sarà la più cara: le altre versioni hanno bus a 128bit con banda più bassa.
Una RTX 4060 di NVIDIA, per fare un confronto diretto, ha circa 272 GB al secondo di bandwidth dedicata solo alla GPU ma Qualcomm mitiga questo problema con i 21 MB di memoria on board; resta comunque un vincolo per i carichi di lavoro più estremi.
La potenza è un altro fattore limitante: la GPU di Qualcomm arriva a consumare circa 30-40W contro i 200W delle GPU per laptop NVIDIA, pertanto le prestazioni assolute non possono competere con le soluzioni dedicate presenti nei laptop top di gamma: sia per il gaming che per applicazioni AI / editing / content creation NVIDIA su PC resta la scelta per chi vuole le prestazioni.
Inoltre l’ecosistema software è ancora in costruzione: Premiere è ancora in beta e non è dato sapere quando uscirà dalla beta e anche all’interno di molti software manca l’accelerazione hardware GPU, supportata invece su Apple e su NVIDIA.
La nuova NPU garantisce 80 TOPS di potenza AI
Qualcomm non è nuova nel campo degli acceleratori neurali. L’architettura Hexagon nasce come Digital Signal Processor nel lontano 2004, ed è stata inizialmente pensata per elaborare filtri audio in modo efficiente. Nel corso di due decenni, e con oltre 20 miliardi di core spediti nei dispositivi di tutto il mondo, questa architettura si è evoluta attraverso diverse generazioni ognuna caratterizzata da un salto qualitativo nelle capacità.
Dal 2019 al 2024, se consideriamo quella che viene definita Hexagon NPU, ci sono state ben sei evoluzioni di NPU chiamate numericamente da NPU1 a NPU6.

Snapdragon X Elite usava NPU3, Snapdragon X2 Elite utilizza la nuova NPU6 ottimizzata specificamente per i Large Language Models moderni, capace di decine di migliaia di MAC (Moltiplica e Accumula) per ciclo.
Entrando nel dettaglio, la NPU di sesta generazione dello Snapdragon X2 Elite è costruita attorno a tre unità di calcolo specializzate. Non è una scelta di design curiosa: rispecchia esattamente il modo in cui funzionano i carichi di lavoro di intelligenza artificiale moderni, che non utilizzano un solo tipo di operazione, ma una combinazione di attività molto diverse.
La prima unità è lo scalar processor, che possiamo immaginare come il “coordinatore” della NPU. È composto da 12 thread distribuiti in 6 coppie disposte a griglia ma questi thread non fanno i calcoli pesanti, si occupano dell’organizzazione.

Sono come direttori d’orchestra che non suonano, ma dicono a tutti gli altri strumenti quando partire. Nella NPU gestiscono la preparazione degli operatori, controllano le altre unità, curano la sincronizzazione veloce dell’hardware e gestiscono la memoria. In questa generazione, Qualcomm ha raddoppiato la banda verso la memoria principale e ha introdotto un Direct Memory Access a 64 bit, così da poter gestire modelli molto più grandi. Il risultato è un aumento del throughput del 143% rispetto allo Snapdragon X Elite.
Concretamente, cosa fanno questi thread scalar? Ogni volta che un modello deve eseguire un’operazione complessa, lo scalar processor carica dalla memoria i parametri necessari, configura le unità vector e matrix indicando loro quali operazioni eseguire, coordina il flusso dei dati affinché arrivino al momento giusto e gestisce le dipendenze tra operazioni, facendo sì che una parte del modello aspetti il risultato dell’altra quando è necessario.
Il supporto al multi-threading simultaneo su 6 thread e il set di istruzioni a 4 vie per ciascun thread permette a ogni thread di eseguire fino a quattro operazioni per volta, mascherando così la naturale latenza che si ha quando si cerca di accedere alla memoria.
La seconda unità è il vector processor, che potremmo definire il mulo da soma per tutte le operazioni ripetitive ma fondamentali: funzioni di attivazione, normalizzazioni, e tutte le operazioni “element-wise”, cioè quelle applicate a ogni elemento di un vettore o di una matrice.

Il vector processor è composto da 8 motori paralleli, ognuno capace di processare 128 byte in modalità SIMD: anche qui il miglioramento del 143% nel throughput deriva dall’introduzione di nuovi formati numerici come FP8 e BF16, oltre che da diverse ottimizzazioni microarchitetturali.
La terza unità, e probabilmente la più importante, è il matrix processor ed è qui che la NPU dell’X2 fa il salto più evidente.
Questa unità è dedicata alle moltiplicazioni di matrici su larga scala, cioè proprio l’operazione che da sola rappresenta circa il 90% del lavoro nei moderni modelli transformer, l’architettura alla base di GPT e di tutti i Large Language Models.

Il matrix processor accelera nativamente operazioni integer e floating-point in FP16, BF16 e FP8, dispone di cache separate per pesi e attivazioni, implementa operazioni fuse (più operazioni combinate direttamente in hardware), ha un suo power rail dedicato per consumare meno e raggiunge un incremento del 78% nel throughput rispetto alla generazione precedente.
Per chiudere una delle innovazioni più significative della NPU è il supporto hardware nativo per pesi a 2 bit. Nei modelli neurali tradizionali ogni peso, cioè ogni parametro della rete, occupa 16 o 32 bit. Un modello come GPT con miliardi di parametri richiede quindi decine di gigabyte di memoria solo per memorizzare i pesi. La quantizzazione a 2 bit significa che ogni peso può assumere solo 4 valori possibili, rappresentabili con le combinazioni 00, 01, 10, 11 e i benefici pratici sono enormi. I modelli diventano da 8 a 16 volte più piccoli, si caricano dalla memoria da 8 a 16 volte più velocemente, e il consumo energetico si riduce drasticamente. Sono anche meno precisi, ma per la pura inference locale questo potrebbe non essere un problema.
All’atto pratico un modello da 7 miliardi di parametri, che normalmente occuperebbe 14 gigabyte in formato FP16, con quantizzazione a 2 bit occupa meno di 2 gigabyte: questo lo rende eseguibile completamente nella cache invece di dover continuamente caricare pezzi dalla memoria principale, con un impatto enorme sulle prestazioni.
Le performance misurate: cosa significano 80 TOPS
Qualcomm dichiara “fino a 80 TOPS”, che sta per tera operations per second, ovvero 80 trilioni di operazioni al secondo. Ricordiamo che Microsoft, per i suoi Copilot+ PC richiede almeno 45 TOPS e ad oggi le altre piattaforme, se guardiamo alla sola NPU, sono abbastanza distanti da questo valore.
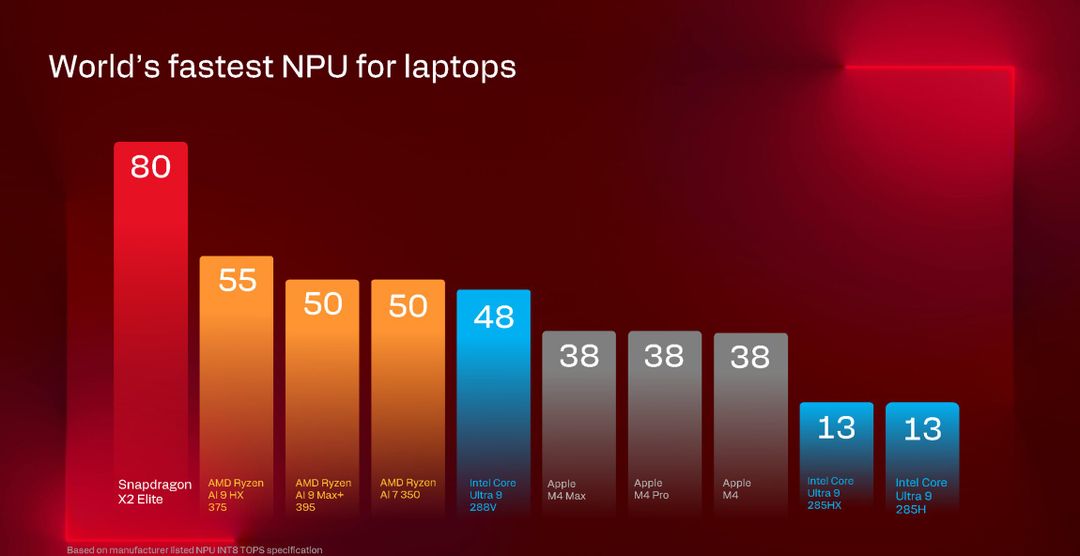
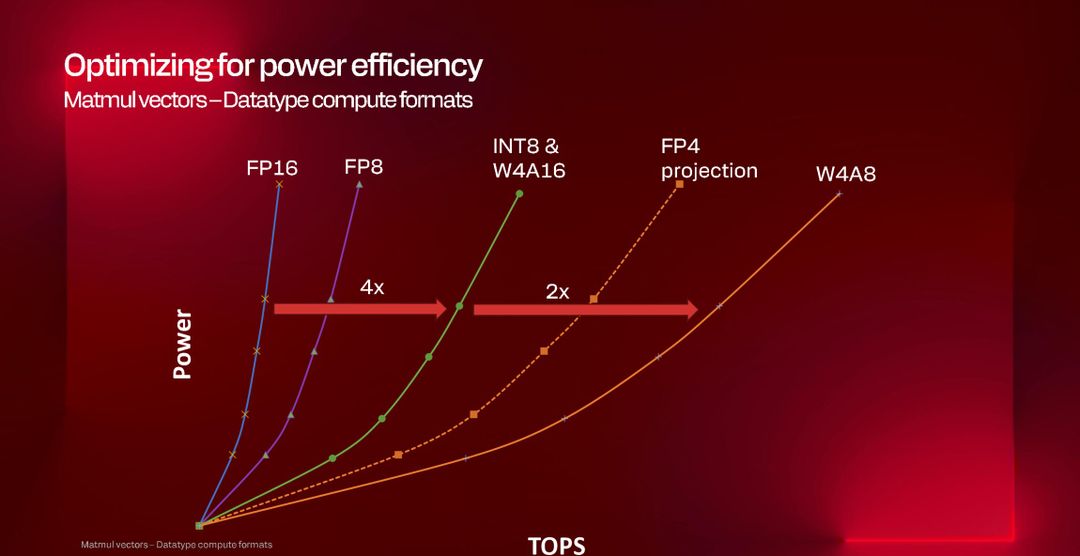
Questo numero va tuttavia contestualizzato perché può significare cose diverse a seconda del formato numerico: Qualcomm ci spiega che con operazioni INT8, integer a 8 bit, otteniamo effettivamente 80 trilioni di operazioni al secondo, ma se passiamo ad esempio a FP16, operazioni in virgola mobile a 16 bit, otteniamo circa 40 TOPS perché ogni operazione richiede il doppio delle risorse.
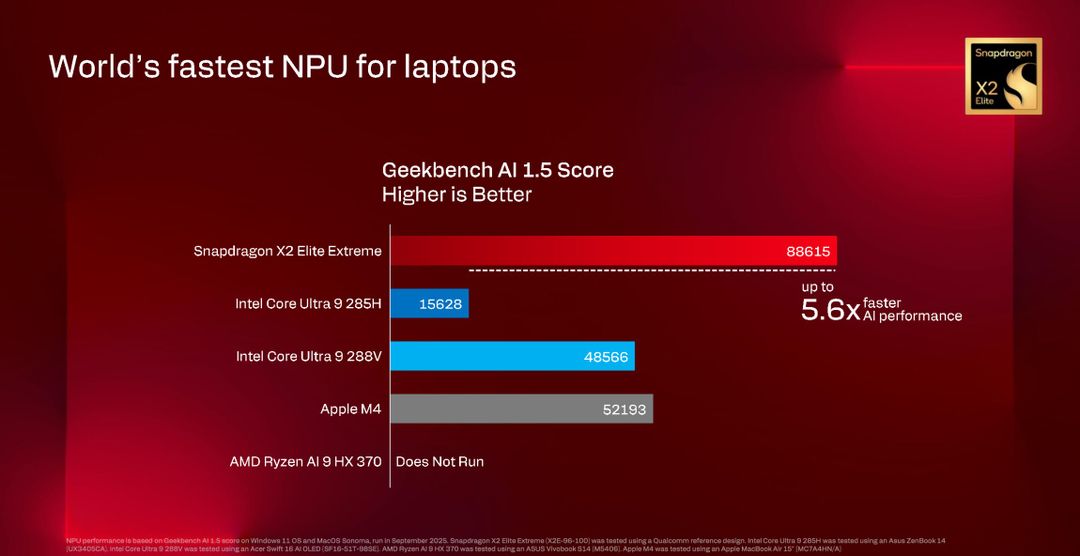
I benchmark reali confermano l’entusiasimo di Qualcomm per la sua NPU: su Geekbench AI 1.5 lo Snapdragon X2 Elite Extreme ottiene un punteggio di 88615 mentre l’Intel Core Ultra 9 285H si ferma a 15628, quindi 5.7 volte più lento. L’Intel Core Ultra 9 288V arriva a 48566, 1.8 volte più lento, e persino l’Apple M5 ottiene 57345, quindi 1.5 volte più lento.
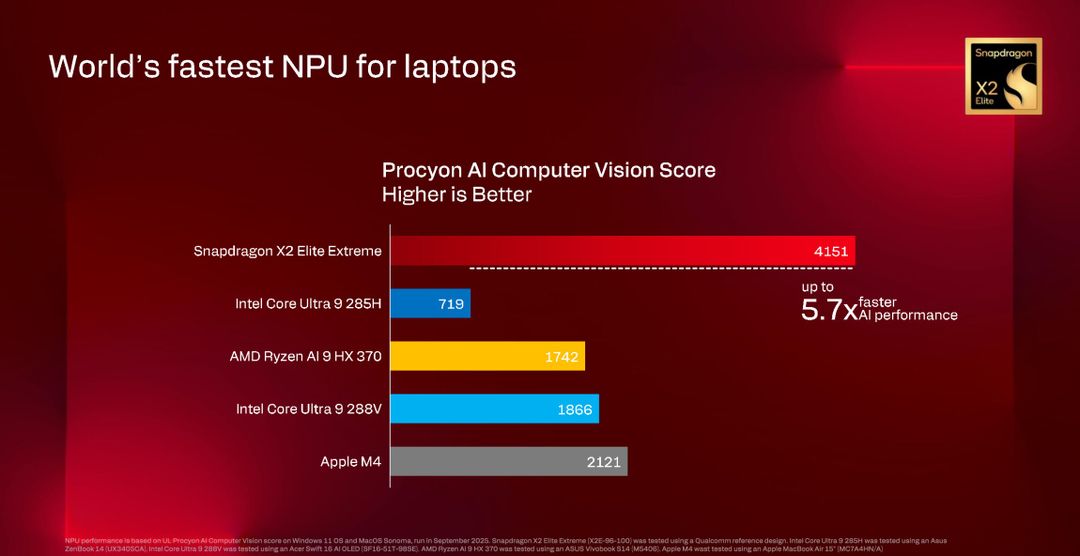
Su Procyon AI Computer Vision, benchmark che misura specificamente le capacità di elaborazione di immagini con intelligenza artificiale, X2 Elite Extreme ottiene 4151 punti, l’Intel 285H solo 719 punti (5.7 volte più lento), l’AMD Ryzen AI 9 arriva a 1742 punti quindi e per avvicinarsi bisogna prendere Apple con M4, che fa comunque un punteggio inferiore. Ricordiamo tuttavia che si sta confrontando la NPU, e CoreML per certi carichi di lavoro sfrutta, come NVIDIA, la GPU.
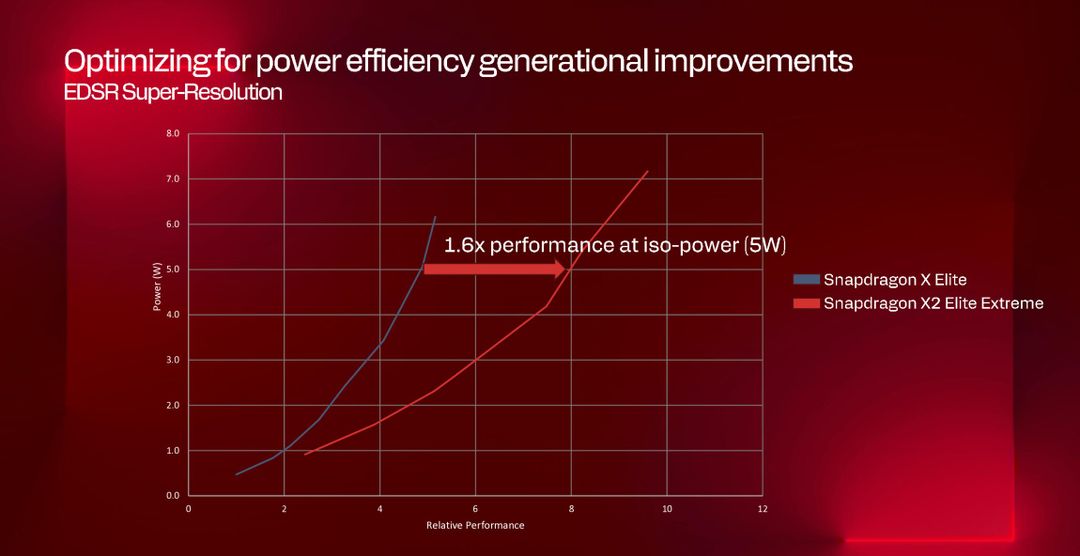
Nei sue giorni a San Diego Qualcomm non ha mai parlato di prestazioni senza abbinare la parte “consumi”: un grafico, sempre fornito da Qualcomm, ci mostra inoltre che fissando il consumo a 5 watt la nuova NPU raggiunge 1.6 volte le performance della generazione precedente.
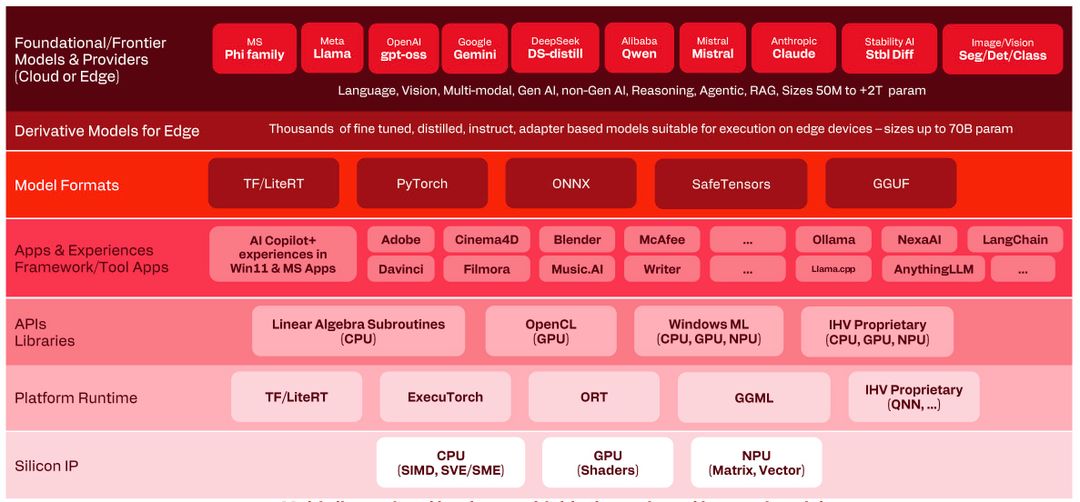
L’ecosistema AI software: dove l’hardware viene sfruttato a pieno
Su Mac, lo abbiamo visto nella recente prova di MacBook Pro M5, sta iniziando a svilupparsi un interessante ecosistema software che sfrutta la potenza dell’IA locale. Ma su Windows?
Qui le cose sono diverse, perché il problema è la classica frammentazione che colpisce le piattaforme non verticali: NVIDIA ha le sue soluzioni, Microsoft ha api generiche per l’IA che non offrono sempre le performance migliori e anche Qualcomm ha i suoi framework.
Per velocizzare la creazione di app compatibili con gli Snapdragon Qualcomm ha creato AI Hub, un sito che contiene oltre 1000 modelli già ottimizzati specificamente per il suo processore: questa libreria copre un’enorme gamma di applicazioni e ci troviamo i più famosi foundational models, ovvero i modelli aperti usati anche come base per la distillazione di altri modelli.
Troviamo la famiglia Microsoft Phi con Phi-3 e Phi-3.5, che modelli compatti ma sorprendentemente potenti, Meta Llama con le versioni 3.2 e 3.1, Large Language Models open source diventati uno standard, DeepSeek con versioni distillate particolarmente efficienti e Alibaba Qwen con modelli multilinguistici ottimi per lingue non occidentali, oltre a Mistral 7B e Stable Diffusion per la generazione di immagini.
Qualcomm offre questi modelli sia agli sviluppatori sia agli utenti che vogliono usare app come LM Studio, ma è consapevole che ad oggi una persona preferisce usare modelli Cloud per velocità e qualità.
Sposta quindi il focus sulle app con funzioni “AI”, e qui dichiara oltre 300 esperienze AI già abilitate su Snapdragon X Series, quindi anche sui modelli attualmente in commercio.
Nell’ambito della computer vision troviamo così funzionalità come Super Sharp che aumenta la nitidezza delle immagini in modo intelligente, Upscale che porta le immagini da bassa ad alta risoluzione mantenendo i dettagli, Color Grading per correzione colore professionale automatica, Masking e Object Selection per isolare automaticamente soggetti nelle immagini, Auto-Crop che ritaglia intelligentemente le foto, Super Resolution che genera dettagli artificiali ma plausibili, Generative Fill che riempie aree selezionate con contenuto generato dall’AI e Generative Erase che rimuove oggetti dalle foto in modo naturale.
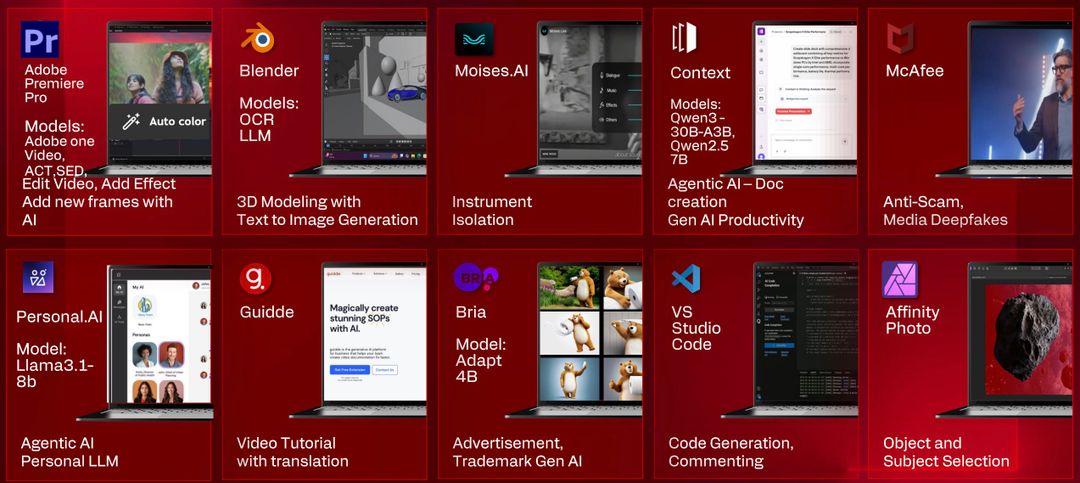
Applicazioni come Adobe Premiere Pro, Affinity Photo, Topaz Labs, Luminar Neo e DaVinci Resolve supportano queste funzionalità.
Per audio e musica ci sono Voice Separation che isola le tracce vocali dalla musica, Stem Separation che separa i singoli strumenti musicali, Beat Mix per mixaggio automatico basato sul tempo, Audio Transcription per trascrizione speech-to-text, Music Generation per creare musica originale, Singer Voice Conversion per cambiare il timbro vocale, Echo e Noise Reduction per pulizia audio professionale.
CapCut, Steinberg, Moises e DJ Pro sono tra le app che usano queste funzioni specifiche del framework AI. Ne abbiamo avuto un assaggio nel laboratorio audio.
 I microfoni posti di fianco all’orecchio in camera anecoica
I microfoni posti di fianco all’orecchio in camera anecoica

Nell’ambito della videoconferenza e della comunicazione, Zoom e Microsoft Teams hanno aggiunto in questi mesi funzioni come la trascrizione in tempo reale durante le videochiamate, la traduzione simultanea in tempo reale, la cancellazione del rumore per eliminare i rumori ambientali, e lo sfondo magico per gli sfondi virtuali avanzati. Sono tutti già supportati.
 Il laboratorio audio dove vengono elaborati i filtri che cancellano il rumore tramite AI
Il laboratorio audio dove vengono elaborati i filtri che cancellano il rumore tramite AI
Per l’Agentic AI locale servono più di 50 TOPS
Una delle evoluzioni più interessanti della piattaforma AI di Qualcomm è però l’intelligenza artificiale agentica: non si limita a rispondere a domande, può agire autonomamente per raggiungere obiettivi.
Qualcomm ci ha mostrato una serie di demo dove questa funzione, da poco aggiunta anche dentro Windows 11, è già funzionante: l’utente dice semplicemente: “Aggiungi al mio calendario il meeting con il cliente domani alle 14:00” e dietro le quinte l’AI esegue a catena una serie complessa di operazioni.
L’agente, che è un Large Language Model, estrae le informazioni chiave: l’evento è un meeting, il tempo è domani alle 14 e deve accedere al calendario per aggiungerlo. Identifica che serve il Calendar Agent per questa operazione e chiama così il Calendar Agent passandogli i parametri estratti, e quest’ultimo usa un modello locale per comprendere il contesto, accede all’API del calendario di sistema, ad esempio Outlook, crea l’evento con tutti i dettagli e conferma all’agente primario che l’operazione è completata.
L’IA a questo punto risponde all’utente: “Ho aggiunto il meeting di domani alle 14”. Tutto questo gira sulla NPU locale, senza mandare dati sensibili al cloud, mantenendo completa privacy.
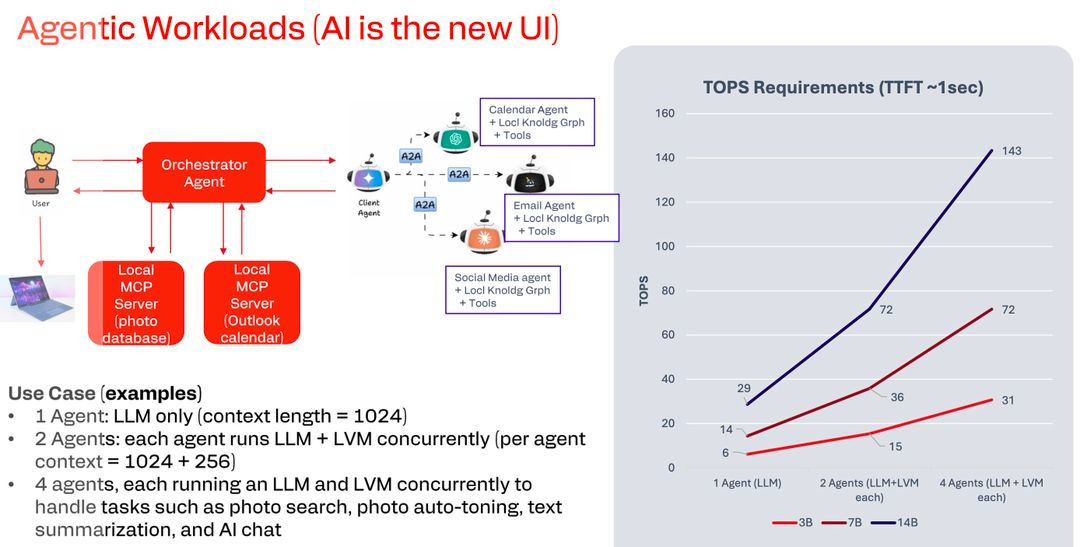
I requisiti computazionali per questi workflow agentici sono elevatissimi: in uno scenario con 4 agenti che lavorano contemporaneamente, per esempio per photo search, photo auto-toning, text summarization e AI chat, ciascuno con un Large Language Model e un Large Vision Model e usando modelli da 3 miliardi di parametri, servono 31 TOPS di potenza. Se si vogliono usare modelli da 7 miliardi servono 72 TOPS, con modelli da 14 miliardi servono addirittura 143 TOPS: questo spiega perché gli 80 TOPS della NPU sono cruciali.
Quattro agenti che lavorano contemporaneamente su modelli di dimensioni realistiche possono facilmente saturare tutti gli 80 TOPS disponibili, specialmente se si vogliono usare modelli grandi e capaci: un agente AI complesso potrebbe doverne usare di più.
Non solo prestazioni ma anche bassi consumi: la ricetta di Qualcomm per una giorno di autonomia
In questo lungo articolo, siamo alla fine, abbiamo capito che Qualcomm ha provato a spremere dai 31 miliardi di transistor ogni singola goccia di performance. Abbiamo anche visto che a parità di prestazioni la CPU consuma il 43% in meno, e che la GPU mostra un miglioramento del 125% in performance per watt. Qualcomm ci ha dato anche altri dati ad esempio c’è una riduzione superiore al 10% nei consumi su carichi quotidiani come web browsing, Office, YouTube e Teams.
Un aspetto poi trascurato, ma fondamentale per i laptop, sono le performance quando il laptop è alimentato a batteria: molti laptop x86 tradizionali hanno cali prestazionali significativi quando scollegati dall’alimentazione.
Lo Snapdragon X Elite aveva un comportamento praticamente identico, Snapdragon X2 Elite mostra un leggero calo di performance tra batteria e rete ma con la maggior parte dei benchmark mantiene il 95-100% delle prestazioni anche se scollegato. Sotto vedremo i dati.
Ma quanto consumano realmente questi Snapdragon? Lo scorso anno abbiamo fatto un po’ fatica a capirlo, quest’anno entrando nei laboratori dove vengono analizzati i consumi e parlando direttamente con Guy Therien ci siamo fatti un’idea più precisa.
 Il laboratorio dove vengono misurati i consumi
Il laboratorio dove vengono misurati i consumi
Qualcomm usa una metrica chiamata INPP, che sta per Idle-Normalized Platform Power, per misurare i consumi in modo accurato e confrontabile tra piattaforme diverse.
L’INPP è definito come la potenza totale della piattaforma dalla quale viene tolta la potenza idle minima. I componenti misurati includono il SoC completo con CPU, NPU, GPU e fabric, la DRAM, e le perdite di conversione di potenza nei PMIC.
La potenza totale viene misurata tramite data acquisition usando diverse strumentazioni di test che vediamo nelle foto. La potenza idle è misurata senza app attive, con brightness al minimo e connettività disabilitata.

Perché l’INPP è importante? Misurare solo il consumo del SoC come fanno altri produttori può essere fuorviante, perché non tiene conto di componenti essenziali: l’INPP misura i consumi a livello di piattaforma completa, includendo la RAM che consuma energia durante gli accessi, le perdite di conversione DC-DC che possono essere significative e i chip accessori come audio codec, PMIC e connettività.
Usare questo parametro secondo Qualcomm permette confronti equi tra piattaforme diverse indipendentemente dall’implementazione specifica scelta dai produttori.
Per Qualcomm la situazione è differente rispetto a quella di Apple, che produce sia il processore che la macchina: Qualcomm vende il processore ai produttori e ogni produttore decide come costruire poi il laptop attorno al processore, quindi non c’è certezza che il comportamento delineato dall’azienda di San Diego si rifletta poi sui prodotti che si trovano in vendita.
Qualcomm ha realizzato quelle che secondo lei dovrebbero rappresentare le implementazioni reali di prodotto, le due Compute Reference Design che sono anche i due laptop da noi usati per i test.

Il primo è un reference design “unconstrained”, che si basa sulla versione Extreme del processore, l’X2E-96-100. È un laptop abbastanza grande con raffreddamento attivo sovradimensionato, che permette al processore di esprimersi al meglio senza mai andare in throttling termico.
Come ci ha mostrato Qualcomm questa versione, con il processore a 18 core, può toccare per pochi secondi anche i 140 Watt di potenza complessiva della piattaforma.
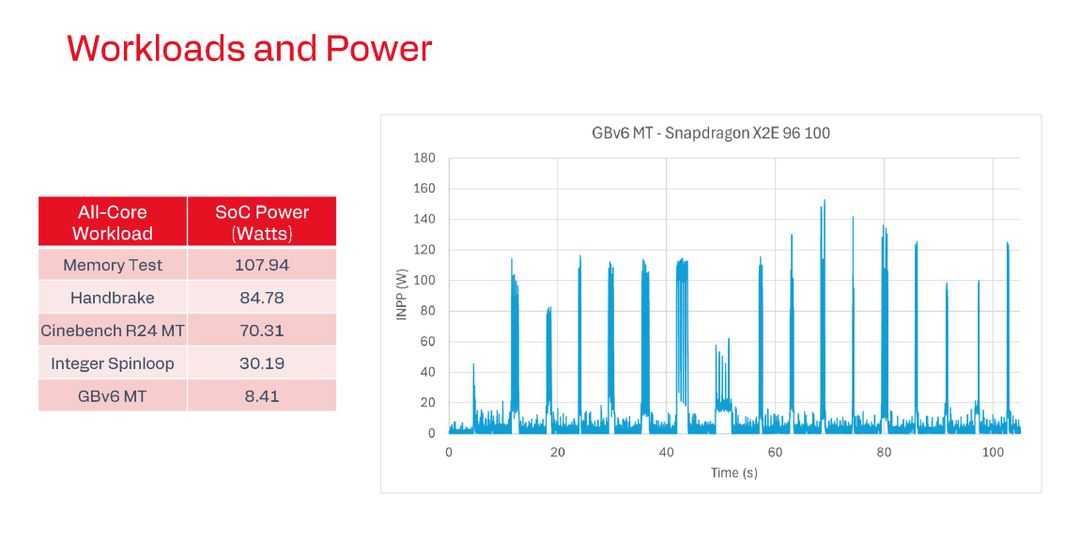
Il grafico sopra mostra il tipico andamento di Geekbench v6: si vedono chiaramente i periodi di pausa tra un test e l’altro, e i picchi in alcune sequenze del test che sfruttano a piano tutti i core. Si tratta ovviamente di consumi istantanei che difficilmente vengono replicati poi in situazioni reali.
Per chi invece vuole una soluzione più silenziosa, con un ottimo velocità / autonomia, Qualcomm propone un reference design più compatto con una sola ventola basato sui due processori X2E-88-100 e X2E-80-100. Questo reference design è dotato di una dissipazione sostenuta del SoC di 22 watt, quindi dopo un boost iniziale ha un throttling termico più conservativo.

Sarà comunque più facile capire se il produttore ha seguito le indicazioni di Qualcomm. Questa nuova versione di processore avrà un’interfaccia software per la telemetria che potrà essere usata da software come HWiNFO: permetterà di monitorare in tempo reale i consumi separati di CPU, GPU e NPU, le temperature dei vari componenti, le frequenze operative, e i power limits attivi in ogni momento.
Si tratta di misurazioni secondo Qualcomm poco precise e stimate, ma sta continuamente raffinando il sistema per migliorare l’accuracy: sarà comunque possibile creare grafici e avere una analisi più accurata con strumenti che oggi le persone usano su altre piattaforme.
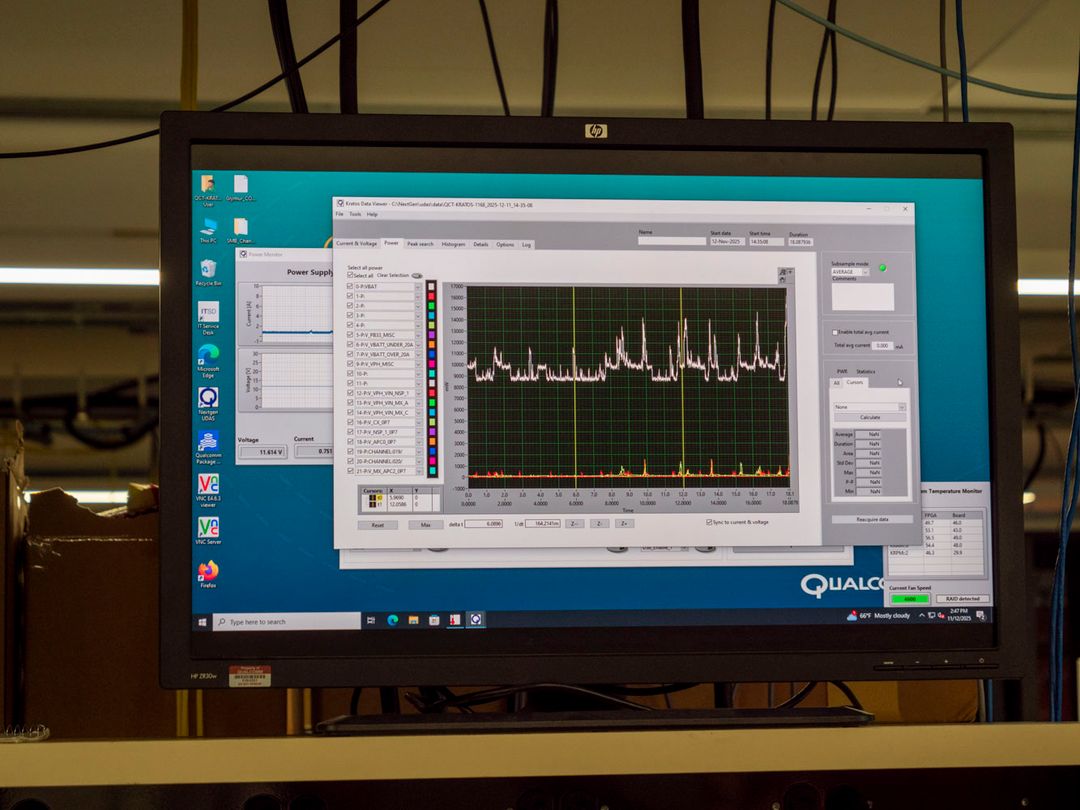 La misura dei consumi che abbiamo fatto in laboratorio
La misura dei consumi che abbiamo fatto in laboratorio
Come ha fatto Qualcomm a tenere consumi così ridotti
Una delle innovazioni chiave per ottenere un elevatissimo rapporto prestazioni consumi è il boost multi-livello per cluster. Ogni cluster Prime ha un boost indipendente e granulare che scala in modo intelligente: con 1 core attivo può raggiungere 5.0 GHz, con 2 cores attivi scende a 4.8 GHz, con 3 cores attivi arriva a 4.47 GHz e con 4, 5 o 6 cores attivi si stabilizza a 4.45 GHz.

Perché questo è importante? Nei workload single-thread tipici di browser e applicazioni Office il sistema può portare un singolo core a 5.0 GHz mentre tiene gli altri core idle o in low-power, massimizzando la reattività dell’interfaccia.
Nei workload multi-thread, come rendering video o compilazione di codice, può distribuire il lavoro su tutti i core operando a frequenze leggermente ridotte per mantenere la temperatura sotto controllo. I due cluster Prime hanno controllo indipendente, quindi possono operare a frequenze diverse contemporaneamente ottimizzando per il carico specifico di ogni cluster.
Il sistema di controllo sviluppato da Qualcomm, chiamato Scenario-Based Optimization, o SBO, ottimizza automaticamente i controlli hardware e software in base al caso d’uso rilevato. Il sistema rileva automaticamente scenari specifici e configura di conseguenza le frequenze di CPU e GPU, i limiti di potenza e l’aggressività del thermal throttling.
Gli scenari ottimizzati includono riproduzione video locale dove si riduce la potenza di GPU e CPU perché non servono prestazioni elevate per riprodurre un video, gaming, dove bilancia attentamente GPU e carico termico, l’esecuzione di un’app dove applica un boost aggressivo breve per aprire l’applicazione velocemente e infine il browser, dove ottimizza la latenza per rendere la navigazione fluida.
Il sistema è configurabile da ogni produttore, il che significa che i vari HP, Lenovo, Acer etc possono personalizzare i profili SBO per le singole famiglie di portatili ottimizzando per le caratteristiche termiche e di alimentazione del loro design.
Qualcomm ci ha mostrato usando Cinebench la scalabilità perfetta di Snapdragon X2. A 20 watt di INPP ottiene circa 750 punti con la versione base di X2 Elite da 12-core. A 40 watt INPP arriva a 1500 punti, a 60 watt tocca i 1750 punti mentre a 100 watt raggiunge i 2000 punti con X2 Elite Extreme da 18-core.
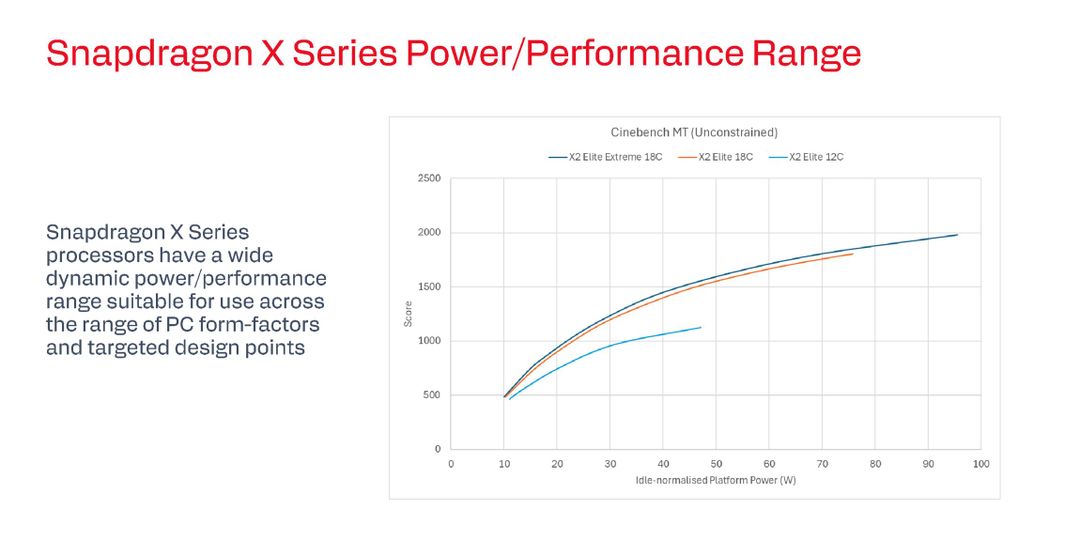
Confrontato con i competitor, il Ryzen AI 9 HX370 mostra curve simili, ma Snapdragon è sempre davanti del 10-15% mentre il Ryzen 7 350 è circa il 20% dietro. Il Core Ultra 9 288V parte meglio a bassa potenza, ma Snapdragon oltre i 40 watt lo passa senza problemi e la stessa cosa succede con il Core Ultra 9 285H, che è competitivo a bassa potenza ma viene superato anche lui da Snapdragon, nettamente, quando si passano i 60 watt.
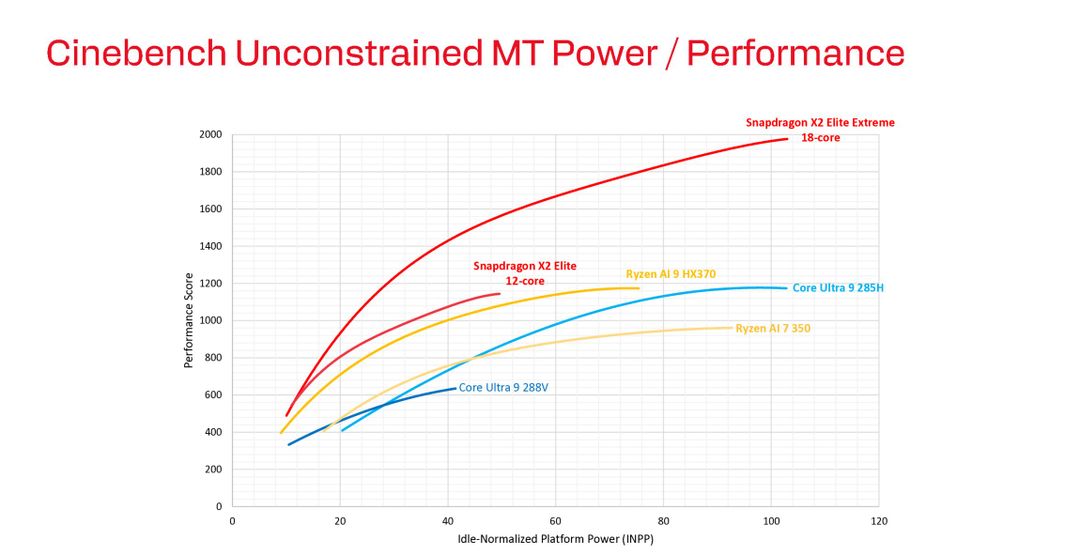
La chiave di lettura è che Snapdragon X2 Elite scala quasi linearmente fino a 100 watt, mentre AMD e Intel tendono a saturare prima, raggiungendo un tetto oltre il quale consumare più energia non porta più benefici prestazionali significativi. La curva di appiattisce.
La gestione delle temperature: la scocca mai rovente
La gestione termica sotto carico è uno degli aspetti più importanti per capire le prestazioni reali di un processore, molto più dei valori di picco mostrati negli screenshot. Qualcomm, per mostrare il comportamento dello Snapdragon X2 Elite in condizioni realistiche, ci ha mostrato dati dettagliati sulle frequenze e sui consumi quando il chip lavora all’interno di una scocca reale e in laboratorio.
 La piattaforma raffreddata con un AIO a liquido nei lab di San Diego
La piattaforma raffreddata con un AIO a liquido nei lab di San Diego
Il test di riferimento è un loop di Cinebench multi-thread da 2.400 secondi, ovvero 40 minuti di stress continuo. Siamo davanti ad uno scenario che nessun utente comune raggiungerebbe, ma che serve a mettere in luce il comportamento del sistema alla temperatura di equilibrio.
Le temperature interne registrate durante questo test sono elevate, ma pienamente controllate. I cluster CPU raggiungono valori compresi tra 85 e 96 °C a seconda del gruppo di core, mentre la GPU si stabilizza intorno ai 74 °C e la NPU sui 80 °C. La temperatura di giunzione complessiva del SoC arriva a un massimo di 96,5 °C, un valore in linea con quello che ci si aspetta da un chip moderno sotto stress estremo.
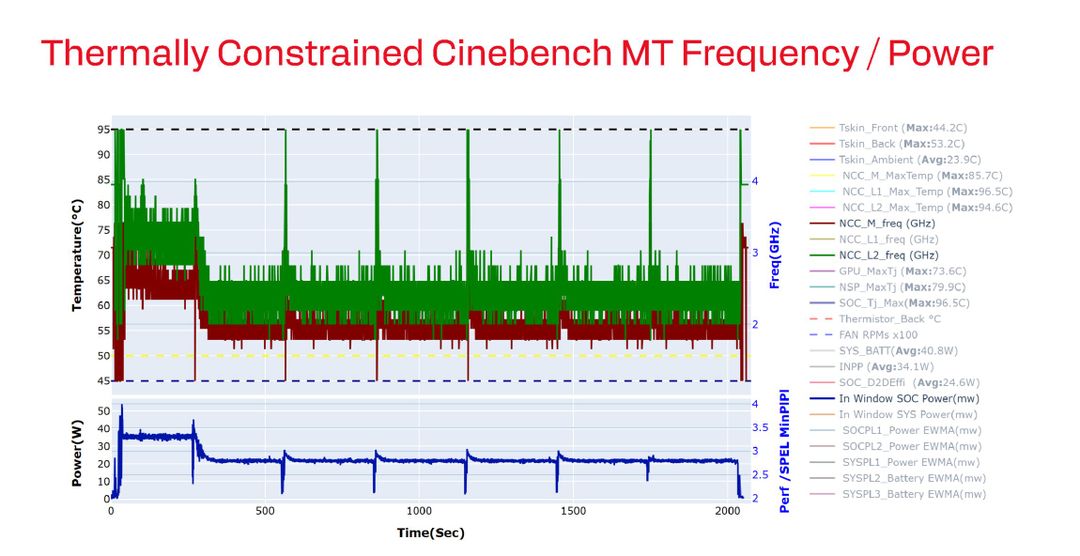
Ancora più interessante è vedere come si comportano le frequenze sotto questo carico prolungato. I cluster Prime mantengono una media di circa 2,8 GHz, con sporadici boost fino a 3,5 GHz, mentre il cluster Performance opera intorno ai 2,0 GHz. È un comportamento molto stabile: nonostante il calore accumulato non si osservano crolli drammatici, ma un controllo preciso della potenza. Il consumo medio del SoC è di circa 25 watt, con picchi brevi fino a 40 watt durante le fasi di boost.
Se le temperature interne mostrano l’efficienza del design, quelle superficiali raccontano quella che sarà l’esperienza utente.
Durante Cinebench multi-thread a circa 31 watt la parte superiore del laptop, dove si appoggiano le mani, raggiunge un massimo di 44,2 °C. La parte inferiore arriva fino a 53,2 °C, ma in un’area che non viene toccata dall’utente durante l’uso. Questo con temperatura ambiente di 23,9 °C, quindi superiore alla media della temperatura che si può trovare in casa.
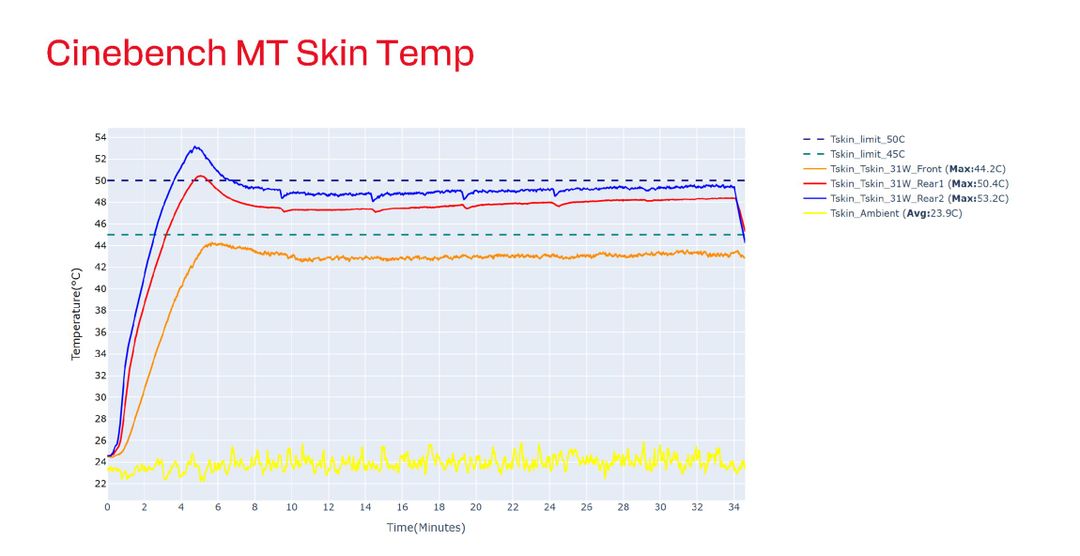
Secondo Qualcomm le misure fatte confermano che lo Snapdragon X2 Elite può offrire prestazioni elevate anche in chassis sottili o con sistemi di raffreddamento non particolarmente generosi, al contrario dei concorrenti che richiedono anche una doppia ventola per evitare un termale throttling aggressivo.
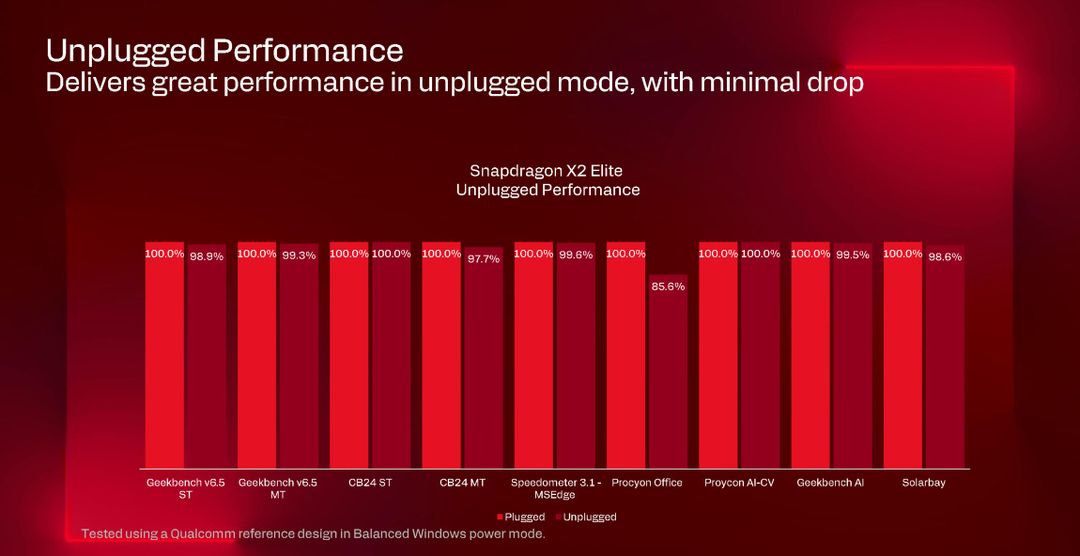
L’ex manager di Intel apre una parentesi finale sulla questione batteria / corrente. “Su molti laptop x86 tradizionali il calo è drammatico per preservare l’autonomia” ci spiega,
I benchmark a batteria, in modalità Windows “bilanciata”, mostrano risultati impressionanti: Geekbench 6.5 single-thread mantiene il 98.9% delle prestazioni con solo l’1.1% di calo, Geekbench 6.5 multi-thread mantiene il 99.3% con solo lo 0.7% di calo, Cinebench 24 single-thread mantiene addirittura il 100.0% mentre in multi-thread tiene il 97.7%, con solo il 2.3% di calo.
Procyon Office mostra un 85.6% quindi un calo del 14.4% che è l’unica deviazione significativa dovuta probabilmente ad un profilo di consumo particolarmente aggressivo; Solarbay, per spostarci anche sulla GPU, mantiene l’98.6% con l’1.4% di calo.
I benchmark sintetici: cosa aspettarsi dai tre prodotti della famiglia
Le prime misurazioni interne fornite da Qualcomm permettono di avere una visione più completa delle prestazioni reali della nuova piattaforma Snapdragon X2 Elite ed Extreme. L’azienda ha condiviso una serie di benchmark sintetici e applicativi che coprono CPU, GPU, NPU e scenari d’uso quotidiani, mostrando come i diversi modelli della famiglia si posizionano all’interno della stessa architettura.
I risultati, raccolti con alimentazione collegata per ottenere le massime prestazioni, offrono un quadro abbastanza dettagliato delle differenze tra le configurazioni a 18 core e quella a 12 core, e mostrano in quali ambiti la piattaforma può vantare un vantaggio significativo. La tabella seguente riassume tutti i valori dichiarati che possono essere confrontati con quelli dei PC attualmente sul mercato.
Ambito
Benchmark
Test
Versione
X2 Elite Extreme
18 core
X2E-96-100
X2 Elite
18 core
X2E-88-10
X2 Elite
12 core
X2E-84-100
L’autonomia reale: 22 ore di uso continuo
Nonostante l’aumento netto di potenza, Qualcomm dichiara miglioramenti significativi nell’autonomia complessiva. Secondo l’azienda c’è stata una riduzione superiore al 10% nel consumo del chip su scenari multipli come web browsing, Office, streaming video e videochiamate su Teams e Zoom.
Qualcomm sta finendo di ottimizzare i driver, ma ci dice che sta puntando ad un consumo identico a quello di Snapdragon X per quanto riguarda l’idle, questo nonostante un processore molto più potente.
Secondo l’azienda di San Diego il consumo del laptop quando l’utente non sta facendo nulla di “attivo” è significativo perché la maggior parte del tempo davanti ad un computer viene passata leggendo mail, pagine di testo, scrivendo documenti, con il processore quasi inutilizzato. La differenza di autonomia che esiste oggi tra PC e Mac è legata al fatto che Apple Silicon, in idle, consuma un terzo rispetto alle controparti AMD e Intel.
 La board di sviluppo di Snapdragon X2 Elite
La board di sviluppo di Snapdragon X2 Elite
Qualcomm non fornisce cifre esatte di autonomia, perché dipendono troppo dal dispositivo specifico, dalla dimensione della batteria e dall’utilizzo reale, tuttavia i miglioramenti di efficienza suggeriscono proiezioni interessanti: in uno scenario tipico di web browsing, Office e video l’X2 Elite potrebbe raggiungere 18-22 ore mentre l’X2 Elite Extreme, con più core e quindi più potenza, potrebbe arrivare a 15-18 ore.
In scenari pesanti come gaming o rendering la riduzione è significativa, ma rimane comunque migliore della concorrenza grazie all’efficienza intrinseca dell’architettura ARM.
Meraviglioso sulla carta, lo aspettiamo l’anno prossimo
Qualcomm ci ha raccontato il suo processore, ce lo ha fatto provare in decine di diverse situazioni e abbiamo potuto anche verificare nei laboratori parte di quello che è stato dichiarato. L’anno prossimo, con i prodotti finiti, vedremo poi se le promesse verranno rispettate.
Quando viene annunciato qualcosa di nuovo, e Snapdragon X Elite era due anni fa qualcosa di effettivamente nuovo, c’è sempre un periodo di assestamento e si dice che la seconda versione è quella da prendere.
Snapdragon X non è andato male: chi lo ha comprato è soddisfattissimo del suo prodotto e sicuramente in questi due anni, grazie anche al lavoro di Qualcomm e Microsoft, la situazione sul fronte della compatibilità è migliorata tantissimo. Qualcomm ha avuto forse più fortuna, commercialmente, con le versioni X e X Plus: Lenovo IdeaPad Slim 5x e Samsung Galaxy Book4 Edge si trovano oggi a circa 650 euro e a questo prezzo sono una soluzione migliore, per il 90% degli utenti, in termini di autonomia, performance e reattività di molti laptop che si possono comprare a prezzi simili ma con processore Intel e AMD.
Ci sarà sempre chi ha necessità particolari, ma proprio per questo motivo il mercato offre un ampio ventaglio di possibilità anche con sistemi operativi differenti.
Abbiamo chiesto a Qualcomm per quale motivo ha puntato ancora, come prodotto di lancio, sui modelli più costosi: la stessa Qualcomm è consapevole che se si superano gli 800$ di prezzo sui laptop c’è una sorta di monopolio Apple, con quote di mercato che in alcuni paesi del mondo, stiamo parlando ovviamente di utenza consumer, arriva anche al 90%.
Qualcomm ci dice che secondo loro il problema è legato proprio all’incapacità delle soluzioni x86 di competere con Apple a livello di autonomia e immediatezza, e hanno scelto di annunciare prima la versione X2 Elite, con prodotti che costeranno sicuramente più di 800$, proprio per dare a chi vorrebbe Windows, ma oggi prende Mac, una alternativa che sia altrettanto potente ma abbia la stessa identica autonomia degli Apple Silicon.
C’è un altro aspetto da considerare, a prescindere dal prodotto. Oggi gli utenti consapevoli e appassionati non fanno il mercato, e il marketing sia sugli utenti sia sui punti vendita ha un forte impatto sul consumatore indeciso.
Se guardiamo al mondo dei PC Windows la situazione negli ultimi anni è abbastanza tragica: AMD, soprattutto in Europa, snobba quasi completamente la comunicazione e il marketing sui prodotti consumer perché è concentrata su datacenter e processori AI. Il consumer rappresenta una briciola del suo fatturato.
La penuria di laptop dotati di processori AMD sui punti vendita è un riflesso di questa situazione.
Intel ha sempre investito milioni di euro sui vari produttori per spingerli a usare i suoi processori, e ha anche speso milioni di euro sui punti vendita per avere un assortimento di PC Intel; ha anche pagato le pubblicità di tutti i produttori.
Le campagne viste in questi anni da parte di aziende che fanno PC Windows sono state pagate in parte da Intel e in parte da Microsoft, anche perché i produttori non hanno margini tali da potersi permettere campagne costose.
Intel è anche lei in un momento particolare, ha praticamente smantellato la struttura comunicazione / marketing in Italia e in Europa: si dovrà attendere qualche anno, quando si vedranno i primi prodotti combinati Intel – NVIDIA, per rivedere la Intel di un tempo, forte degli investimenti che sicuramente NVIDIA metterà sul piatto.

Oggi l’unica azienda che si può permettere di investire centinaia di milioni di euro per promuovere un laptop è Qualcomm con Snapdragon: dalla sponsorizzazione della Formula 1 a quella del Manchester United il reparto marketing di Qualcomm è fortissimo, e ha lavorato in questi anni per promuovere il brand Snapdragon.
L’anno prossimo dovrebbero essere almeno 100 i differenti design di prodotti con Snapdragon X2 Elite, e gli Snapdragon X resteranno in gamma sia con Windows sia con il nuovo sistema operativo Android per PC. Sarà molto più facile trovare un computer con Snapdragon rispetto a uno con AMD o Intel sul punto vendita: gli investimenti, ci dicono, saranno enormi.
L’unica incognita in questo settore è NVIDIA: l’azienda ha pronto il suo chip ARM per Windows ed è lo stesso chip, il GB10, che ha inserito dentro il piccolo DGX Spark.
Un chip con processore ARM e GPU Blackwell che ha mostrato i muscoli questa settimana con Proton: Cyberpunk, a 1080p con impostazioni massime, Ray Tracing Ultra e DLSS 4 con Multi Frame Generator arriva a più di 175 fps, questo con un consumo attorno ai 110 Watt. Un piccolo miracolo per un SoC integrato con quel consumo.
Crediamo che NVIDIA possa annunciare questo processore nella prima metà del 2026: ha semplicemente atteso la compatibilità delle varie piattaforme anticheat per ARM, arrivata di recente.
Ne siamo certi: tra M5, Qualcomm, NVIDIA e Android PC sarà un 2026 frizzante. Prezzo delle RAM permettendo.