Test suite
The organization of Benchpress is shown in Extended Data Fig. 1. The test suite does not need to be installed, but executing the tests requires pytest39 and any SDK-specific dependencies. In addition, we use pytest-benchmark40, which provides a robust method for timing tests and generating result information in JSON format. However, because these tools are typically used in the context of unit testing, they are primarily aimed at tests requiring only short durations of time. Here, we are interested in the opposite regime where test times can easily approach an hour or more and, in some cases, have run for a week before being manually terminated. With the large number of tests considered here, running all tests to completion is impractical. As such, we run all tests using a modified version of pytest-benchmark that wraps each test in a subprocess that can optionally be terminated after a specified timeout. Tests that exceed a timeout are automatically added to the skipfile.txt shown in Extended Data Fig. 1. This file dramatically reduces the overhead from repeated test evaluations. However, it is tied to the specific computer on which it is generated and can mask performance improvements if used across different SDK versions. The file used in this work was generated using the same SDK versions given in Table 1. Note that using subprocesses to enforce timing can have adverse effects when timing software uses parallel processing. As such, the modified version of pytest-benchmark used for each SDK differs in the mechanism by which it spawns processes.
To define a uniform collection of tests across SDKs, Benchpress uses abstract classes of tests called workouts, where each test is defined as a method to a Python class, where the name of the method defines the test name, and each test is decorated with xpytest-benchmark by default. Each class of tests is also logically organized into groups using pytest-benchmark. Implementing the actual tests for a given SDK requires overloading the abstract definitions in the workouts with a specific implementation. These are included in the ‘gym’ directory corresponding to the given SDK (Fig. ??) and grouped into their respective categories. We have included a verification mechanism that verifies that only those tests defined in the workouts are allowed to be present at the gym level. We enforce this gym partitioning so that each SDK can be run in isolation, and we execute the tests in each gym in a separate environment. However, to make a uniform testing experience across SDKs, Benchpress makes use of Qiskit throughout its infrastructure, in particular its compatibility with other SDKs and OpenQASM import and export capabilities, to supplement functionality missing in other SDKs, as well as provide reference implementations for data such as abstract backend entangling gate topologies that can, with minimal effort, be consumable by the other SDKs. Thus, Qiskit is a requirement common across all SDKs, but the version of Qiskit can differ, needing to satisfy the minimal requirements only.
Customizing the execution process is done via a configuration file, default.conf, that allows one to set Benchpress-specific options such as the target system used for device transpilation, as well as the basis gates and set of topologies utilized for the abstract transpilation tests defined in the Methods. We have decided to allow multiple device topologies within a given benchmark run, but the basis gates are fixed throughout. This choice is motivated by the fact that we explicitly focus only on the number and depth of 2Q gates in a circuit. With most 2Q gates equal in number up to additional single-qubit rotations, the basis set has less impact on final results than the choice of topology. SDK-specific settings, such as optimization level, can also be set in this file, and additional options can be easily added as there is no hard coding of parameters. In addition, pytest and pytest-benchmark options can be set using the standard pytest.ini file. In this file, we add the flag to allow only a single execution of a test to be performed, as opposed to the usual minimum of five to make runtimes manageable.
Test result definitions
Benchpress accommodates SDKs with disparate feature sets by running the full test suite over each SDK, regardless of whether the individual tests are supported. Our test environment is based on pytest?, and we map each of the standard pytest output types to the following definitions:
-
PASSED: This indicates that the SDK has the functionality required to run the test, and doing so completed without error and within the desired time limit, if any.
-
SKIPPED: The SDK does not have the required functionality to execute the test, or the test does not satisfy the problem’s constraints, for example, the input circuit is wider than the target topology. This is the default status for all notional tests.
-
FAILED: The SDK has the necessary functionality, but the test failed or was not completed within the set time limit, if any.
-
XFAIL: The test fails irrecoverably. It is therefore tagged as ‘expected fail’ rather than being executed. For example, a test is trying to use more memory than available. Note that, because we execute tests in subprocesses to implement a timeout mechanism, some failures can kill the subprocess but otherwise not affect the remaining tests. These are considered FAILED per the definition here.
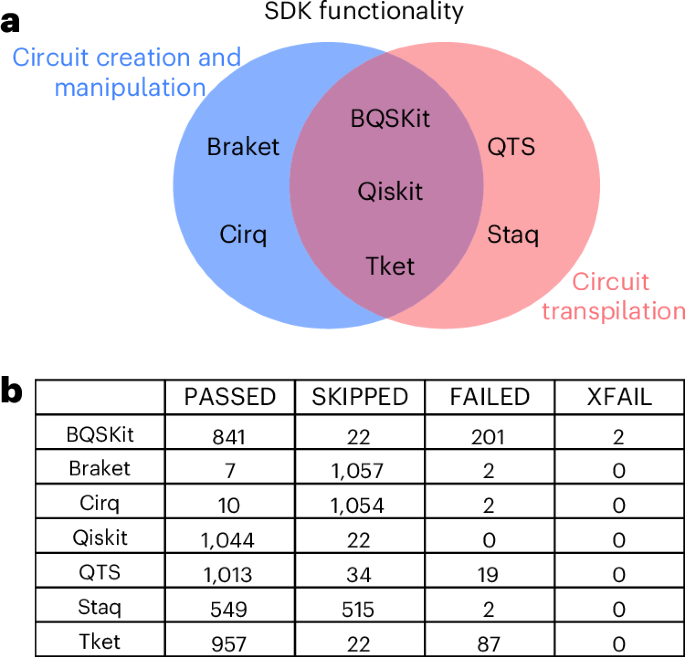
All tests have notional definitions called workouts (Methods) that are placeholders for SDK-specific implementations and default to SKIPPED unless explicitly overwritten in each SDK test suite. In this way, Benchpress can use skipped tests as a proxy for measuring the breadth of SDK functionality, and this can be tracked automatically when additional functionality is added in the form of new tests. Figure 1 shows the distribution of tests by status for the results presented here when running the full Benchpress test suite against each SDK. While the specifics of test failures will be discussed below, we note that 97% of failures occur when running benchmarks originating from other test suites, as opposed to those created explicitly for Benchpress.
Circuit construction and manipulation tests
Although nominally a tiny part of an overall circuit processing workflow time budget, as compared with circuit transpilation, measuring the timing of circuit construction and manipulation gives a holistic view of quantum SDK performance. Moreover, if suitably chosen, such tests can provide insights into other parts of the entire circuit compilation process. The present version of Benchpress includes 12 such tests, with tests aimed at representing scenarios encountered during real-world SDK usage. Circuit construction includes eight tests that look at timing information needed to build 100-qubit circuits for families of circuits such as quantum volume (QV)41 (test_QV100_build), Hamiltonian simulation16 (test_DTC100_set_build), random Clifford circuits42 (test_clifford_build), 16-qubit iterative construction of multicontrolled gates (test_multi_control_circuit) and parameterized ansatz circuits with circular entangling topology (test_param_circSU2_100_build). We will reuse many of these circuits in device benchmarking. We also include the time to bind values to parameterized circuits (test_param_circSU2_100_bind) and import from OpenQASM files into the construction category. This latter set of QASM tests includes importing a 100-qubit QV circuit and reading a file with an integer corresponding to a 301-bit classical register, test_QV100_qasm2_import and test_bigint_qasm2_import, respectively. Our focus on 100-qubit circuits stems from the need for sufficient complexity for gathering faithful timing information and the fact that these circuits are within the number of qubits available on present-day quantum processors.
Circuit manipulation is the set of operations that can be performed on a fully built circuit. Out of the four such tests included, two represent basis transformations, test_QV100_basis_change and test_random_clifford_decompose43, taking an input OpenQASM file and expressing them in a differing set of gates. In a similar vein, we use the same multicontrolled circuit used in the circuit construction tests and time the decomposition into a QASM-compatible gate set in test_multi_control_decompose. In contrast to the previous tests, this decomposition requires a nontrivial synthesis step and provides additional insight into how well the SDKs transform abstract quantum circuits into primitive components. This is captured in the number of 2Q gates in the circuit returned at the end of the test, and this value is also recorded. Finally, we also implement Pauli twirling44,45 in each SDK, test_DTC100_twirling, recording the time it takes to twirl 19,800 CNOT gates in a Hamiltonian simulation circuit.
Circuit transpilation tests
Due to their vast array of possible input parameters and a large fraction of overall runtime, transpilation tests form the bulk of the tests in Benchpress. We split these tests into two groups depending on whether they target a model of a real quantum device, or if their target is an abstract topology defined by a generating function. We label these as ‘device’ and ‘abstract’ transpilation tests, respectively. These tests differ because device testing targets a fixed model of a quantum system, regardless of input quantum circuit size, and includes error rates that can be utilized in noise-aware compilation routines. Noise-aware heuristics can have an impact on both the duration of the compilation process, as well as the 2Q gate count and depth; they can paradoxically lead to worsened performance if applied overly aggressively. However, because we do not execute the resulting circuits on hardware, the impact of these techniques on output fidelity is not included. By contrast, abstract transpilation tests take an input circuit and finds the smallest topology compatible with the circuit. In this manner, we can benchmark SDKs across arbitrary circuit sizes and topology families, allowing for user configuration of the basis gates in the default.conf file (Fig. ??).
Device transpilation tests come from three sources. First, we include a collection of tests that focus primarily on 100-qubit circuits representing circuit families such as QV, quantum Fourier transform, Bernstein–Vazirani (BV) and random Clifford circuits. In addition, circuits generated from Heisenberg Hamiltonians over a square lattice and the quantum approximate optimization algorithm circuits corresponding to random instances of a Barabási–Albert graph are also included. We also add 100- and 89-qubit instances of the same parameterized ansatz circuits used for the circuit construction and manipulation tests, where the former can be embedded precisely on a heavy-hex device, that is, there is an ideal mapping, while the latter cannot. This set also includes a circuit with a BV-like structure, but where the circuit can be optimized down to single-qubit gates if transpiled appropriately. Because this set of circuits is represented in OpenQASM form or generated using QASM-compatible gates only, they do not test the synthesis properties of each SDK. To do so, we include a set of 100 abstract circuits using Hamiltonians included in the HamLib library11 for time evolution. The choice of Hamiltonians is described in ‘Hamiltonian selection criteria’ and results in a set of Hamiltonians from 2 to 930 qubits in size. Finally, we include the Feynman collection8 of circuits that are up to 768 qubits, and also OpenQASM-based, in device transpilation tests. Depending on the target quantum system for device transpilation, some device tests may be skipped due to insufficient physical qubit count. For benchmarking against abstract topologies, we run the same set of Hamiltonian simulation circuits run for device transpilation and include OpenQASM tests from QasmBench9 that go up to 433 qubits.
Our performance metrics for both sets of tests are 2Q gate count, 2Q gate depth and transpilation runtime. In addition, we record the number of qubits in the input circuit, QASM load time (if any) and number and type of circuit operations at the output. Any additional metrics that are compatible with JSON serialization can be included. The target system used in the device transpilation tests is the FakeTorino system, which is a snapshot of a 133-qubit Heron system from IBM Quantum that includes calibration data suitable for noise-aware compilation. Abstract topologies tested are all-to-all, square, heavy-hex and linear, which includes most typical device topologies, and are predefined graphs in the rustworkx library46. We have configured the abstract models to use the basis set [‘sx’, ‘x’, ‘rz’, ‘cz’]. Finally, to limit the duration of the tests, we have set a timeout limit of 3,600 s (1 h), after which the test is marked as FAILED.
In this Article, we focus on testing the predefined transpilation pipelines in each SDK. In this way, we aim to measure the relative performance that a typical user would see, and eliminate the bias involved when creating bespoke transpilation workflows in SDKs of which we have less knowledge than Qiskit. In making Benchpress open-source, we hope that comparisons of optimal performance can be led by community experts in each SDK. Here, we use the default optimization values for both Tket (2) and BQSKit (1). Qiskit does not have a well-defined default optimization level, with the transpile function having a default value of 1, whereas the newer generate_preset_passmanager interface must have the optimization level explicitly set. In this work, we use optimization level 2 for Qiskit that will be the default value for both ways of calling the transpiler functionality starting in version 1.3.0. This same optimization value is used for the QTS as well. Staq was set to optimization level 2 to generate circuits valid for the target topologies. All other transpiler values are left unchanged.
Hamiltonian selection criteria
Hamiltonians included in Benchpress originate from the HamLib Hamiltonian library11, which includes problems from chemistry, condensed matter physics, discrete optimization and binary optimization. We randomly selected Hamiltonians from HamLib to be included in the benchmark suite presented in this work. The random selection is biased toward reflecting the distribution of Hamiltonian characteristics prevalent in HamLib such as the number of qubits and number of Pauli terms. Furthermore, we limited the number of qubits in the selected Hamiltonians to ≤1,092 and the number of Pauli terms to 10,000 or fewer. Furthermore, the random selection is biased toward ‘unique’ Hamiltonians; the selection of different encodings of the same Hamiltonian is discouraged. One-hundred HamLib Hamiltonians are included in this version of Benchpress, where 35 Hamiltonians are from chemistry and condensed matter physics problem classes each, and 15 Hamiltonians are chosen from both discrete and binary optimization problem classes.
SDK-specific considerations
Given quantum computing software’s nascent stage of development, it is common to encounter pitfalls when benchmarking these software stacks. Here, we detail some of these issues as they pertain to executing tests in Benchpress.
BQSKit
BQSKit performs unitary synthesis up to a maximum size specified by the max_synthesis_size argument to the compiler. The compiler will fail if a unitary is larger than this value. However, given an OpenQASM circuit, an end user must first parse the file to learn the correct size for this argument; the returned error message does not include the required value. As there is no manner outside of parsing files to gain this information, we have this parameter to the default value, max_synthesis_size=3, letting tests fail if they have unitary gates outside of this value.
In addition, BQSKit does not support coupling maps that correspond to 2Q entangling gates with directionality; the topology is assumed to be symmetric. The CZ gate used in this work is a symmetric gate, and thus the circuits returned from the BQSKit transpiler pass the structural validation performed here. Selecting a directional gate, such as an echoed cross-resonance gate, would, in general, fail validation.
Qiskit transpiler service
The default timeout value for the QTS is less than the 3,600-s timeout used in this work. As such, we explicitly set the timeout value to match when calling the QTS service for each test.
Tket
The OpenQASM import functionality in Tket requires the user to specify the size of classical registers in the circuit if those registers are larger than 32 bits. Given an arbitrary OpenQASM file, the user must first parse the file to gather the size of the classical registers or try importing the file first, capturing the exception and reading the register size from the error message. To get around this limitation, Benchpress includes a maxwidth parameter in the Tket section of the default.conf file that allows one to specify a maximum allowed classical register size. Given that the maximum number of qubits in the OpenQASM files is 433, we have set this value to 500 in the default.conf.
Staq
Staq cannot return quantum circuits in the basis set of the target backend. Instead, the output is always expressed in generic one-qubit unitary U and CNOT gates. Because of this, we perform structural validation only on circuits returned by Staq. In addition, we compute 2Q gate counts and depth on the CNOT gates. This is valid provided the target 2Q gate is equivalent to a CNOT gate up to single-qubit rotations. For the CZ gate used here, this relation holds.
Optimization level 3 of Staq includes the compiler flag -c that applies a CNOT optimization pass. This pass generates output OpenQASM files that do not obey the entangling gate topology of the target device; the output circuits fail the structural validation check at the end of each test. As such, we have set the default optimization level of Staq to 2.