

Doubling the transistor count every two years and therefore cutting the price of a transistor in half because you can cram twice as many on a given area transformed computing and drove it during the CMOS chip era.
But that Moore’s Law math also means something else. Given a slightly higher power budget each time, you could boost performance of a device by 40 percent a year. And for compute engines, that meant an annual cadence of upgrades could more than keep up with the growth of transactional and analytical workload at most companies. And for those who needed more, there was symmetric multiprocessing (SMP) and then non-uniform memory access (NUMA) clustering to make multiple devices look like one big one – what we call scale up.
With the Web 2.0 Internet era that really got going at the end of the 1990s, one machine, even with SMP or NUMA, this so-called scale up shared memory approach to increasing compute was not enough. (Interestingly and coincidentally, this was also when the exotic federated NUMA configurations in supercomputing, which today we could easily build with off-the-shelf PCI-Express switches, also ran out of gas for traditional HPC simulation and modeling workloads, but at a much higher scale that was too costly for enterprises and the webscale companies like Google that had not yet warped into hyperscale. And so in both cases, scaling out across distributed computing clusters with hundreds to thousands of nodes very quickly became the only way to get a machine to do more work at the same time or do the same work in a lot less time.
And at this point, the network really did become the computer. And the network has been the bottleneck ever since, and is now a huge bottleneck in the GenAI era where GPUs that cost $30,000 or $40,000 or $50,000 are running at maybe 25 percent to 35 percent of their computational capacity as they wait to exchange data with all other GPUs in an AI cluster with every iteration of an AI training run.
We are in what Amin Vahdat, vice president and general manager of AI and infrastructure at Google, called the fifth epoch of distributed computing in the opening keynote at the Hot Interconnects 32 conference this week, and the huge leaps in performance required by GenAI workloads means that the computing industry has to once again rethink the way networking, well, nets and works.
Before we get into what the fifth epoch of distributed computing needs from its networks, here are the epochs according to Vahdat:
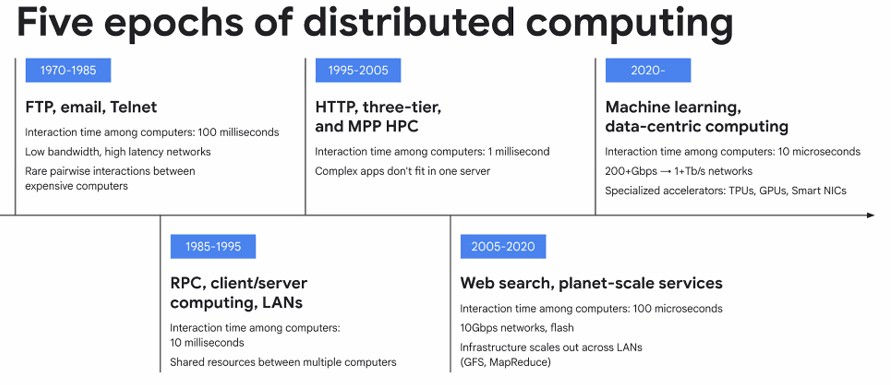
You will note in the table above that with each new epoch in compute, the interaction time between the computers used to run applications went down by an order of magnitude, and that is from 100 milliseconds in the FTP/Email/Telnet era that ended in the mid-1980s to the 10 microseconds in the current machine learning/data-centric computing era, as Vahdat calls it and what we might simplify as “data intelligence.”
The compute and storage capacity grew in kind, using the network and driving it harder as more capacious compute and storage came to the market, creating a virtuous as well as vicious cycle.
“From the period from 2000 to 2020, through tremendous work across the community, we got to a place where we delivered about a factor of 1,000X improvements in efficiency for fixed costs,” Vahdat said in his keynote. “What that means is that in, let’s say approximately 2020, you could have 1,000X the compute capacity or 1,000X times the storage capacity for the same price as you did in 2000. The kinds of things that we can imagine just change dramatically in turn. This set the stage for Gen AI. What I mean by that is we wound up in a place with enough data and enough computing power where we could imagine running massive computation just regularly, for training or for serving in service of these new generations of models. So though, the demand continues to grow, and so while we took 20 years to deliver the last 1,000X improvement in efficiency, we are going to have to deliver the next 1,000X much, much more quickly. And that, I think, is going to be the key to our work.”
This being the age of accelerated computing, it makes poetic sense that the rate of demand for compute is accelerating.
“What we saw in the previous epoch was rapid growth, but really it has been over the past few years that we have seen almost unbounded, 10X year over year growth in demand for computing,” explains Vahdat.
“And along with that demand for computing comes commensurate demand for networking.”
This 10X increase in demand in compute per year in the GenAI era is tough, Vahdat says, because even if you can manage to increase the performance of a compute engine by 2X or 3X by a combination of larger chips (or chiplet complexes) and decreasing numerical precision, you still need to make up another 3.3X to 5X to get to that 10X, and that means the number of endpoints in a distributed computing system will have to keep growing no matter what.
This is why we see a handful of AI model builders having built systems with 100,000 or 200,000 endpoints and lots of people are talking about clusters with 1 million XPUs in the next year or two. And this is not a capacity cluster, to borrow a term from the HPC space meaning a machine that has thousands of workloads all scheduled on a machine in a shared fashion, but a true capability cluster that is intended to run a single workload across the entire machine. Because it has to.
Dicing and slicing the sum total of human knowledge and creating a giant knowledge graph of it to pour queries into to compel a response that makes statistical sense based on that knowledge is one, big job.
The good news is that AI workloads are predictable even if they are needy. Look at this chart that shows the bursty traffic when training the Gemini model, looking at traffic rates over 30 second, 5 second, and 100 millisecond intervals:
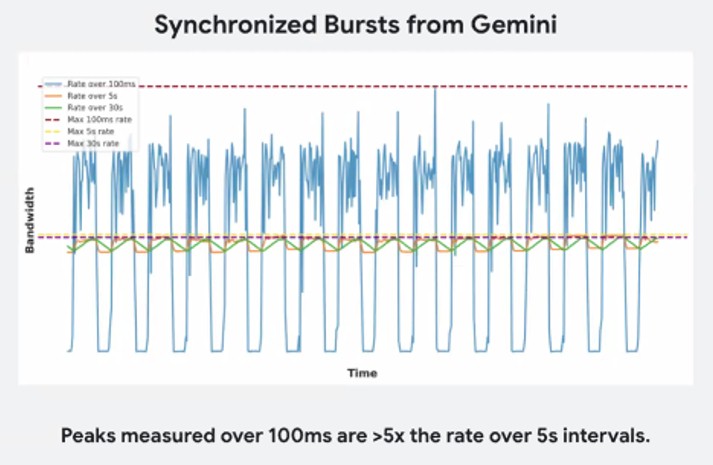
On the 5 second timescale, the bandwidth fluctuations on the host network look like choppy waves but nothing too dramatic, and on the 30 second timescale, it looks like everything is smooth and easy. But this is not an accurate characterization of what is happening. Look at the wild swings in the 100 millisecond blue line. The accelerators are just sitting there waiting a good bit of the time, and then absorbing data like crazy other times.
But again, look at that predictability. If something can be predicted so regularly, then it can be managed and even more importantly it can be scheduled. And that is the secret of the fifth epoch network, and indeed is one of the things that the Ultra Ethernet Consortium is working towards providing for an AI/HPC variant of Ethernet networking.
“Increasingly, you have entire networks, tens of thousands of servers, perhaps dedicated to run a single application at a time, and the phases from computation to communication are very stark,” says Vahdat . “There is no statistical multiplexer. There is one application, and that one application is tightly synchronized. In other words, the computation often requires all-to-all communication, and we’re talking among possibly 10,000-plus servers, which means that the communication then is very synchronized, breaking some of the fundamental assumptions that we have had over the years.”
Here are the new assumptions for AI workloads and their networks as Vahdat laid them out in his presentation:
- Synchronized, periodic line-rate bursts at millisecond granularity lasting for tens of seconds
- Latency sensitive (memory barriers) and bandwidth intensive
- Predictability: For synchronous workloads, the worst-case (100th percentile) latency doesn’t just impact performance – it dictates it
- Workload expects a near-flawless infrastructure (any crash stops the entire job from running)
- Single tenant workload and synchronized high-speed bursts, and there is no benefits from statistical multiplexing across workloads because there is only one
- Accelerator efficiency is paramount, and the network is the single-most critical enabler of system-wide performance, predictability, and reliability
This network of the future, says Vahdat, has to deliver massive burst bandwidth, low latency, ultra-low jitter, and flawless reliability at huge scale. Easy peasy, right?
There are many secrets to this fifth epoch network – and rest assured, Google is probably not going to contribute its hardware designs and protocol specifications to Open Compute and its software to the Linux Foundation – but the important ones are Google’s its Firefly network clock synchronization, Swift congestion control, Falcon hardware transport, and Straggler Detection (which needs a better codename) to identify and isolate hard and soft failures in the network stack and the compute nodes in AI systems.
Of all of these, Firefly might be the most important, and the insight is that with a predictable network load, even one that changes, if you can schedule every aspect of the flows, then you can manage all of those flows and never create congestion in the first place. To do that, as it turns out, you need a clock to synchronize the dance of data on the network that cycles considerably faster than the latency of the network. (Obviously even with such scheduling there is still some congestion on the network or Google would not need Firefly network clocks and traffic scheduling.)
This new datacenter metronome will be revealed at the SIGCOMM 2025 conference in early September in Portugal in a paper called Firefly: Scalable, Ultra-Accurate Clock Synchronization For Datacenters. Google has had atomic clocks in datacenters since around 2010 or so when it was testing out its Spanner globally distributed database, which runs atop its globe-spanning Colossus file system. Back then and now with Firefly, a universal cloud is necessary because, as Vahdat’s presentation at HOTI 2025 puts it, “you cannot schedule what you do not time.” FireFly is literally a metronome for everything across a datacenter, providing a sub-10 nanosecond clock-synchronized fabric that spans the whole shebang.
By timing and scheduling every little thing, the network transforms “from a source of random delays into a deterministic, reliable fabric,” as Vahdat detailed in the presentation. Every data transfer is choreographed, and because the all-to-all communications patterns are so regular (as you see above), this is not as ridiculous as it sounds. The network goes from being reactive with best-effort delivery of packets to a “proactive, perfectly scheduled one.”
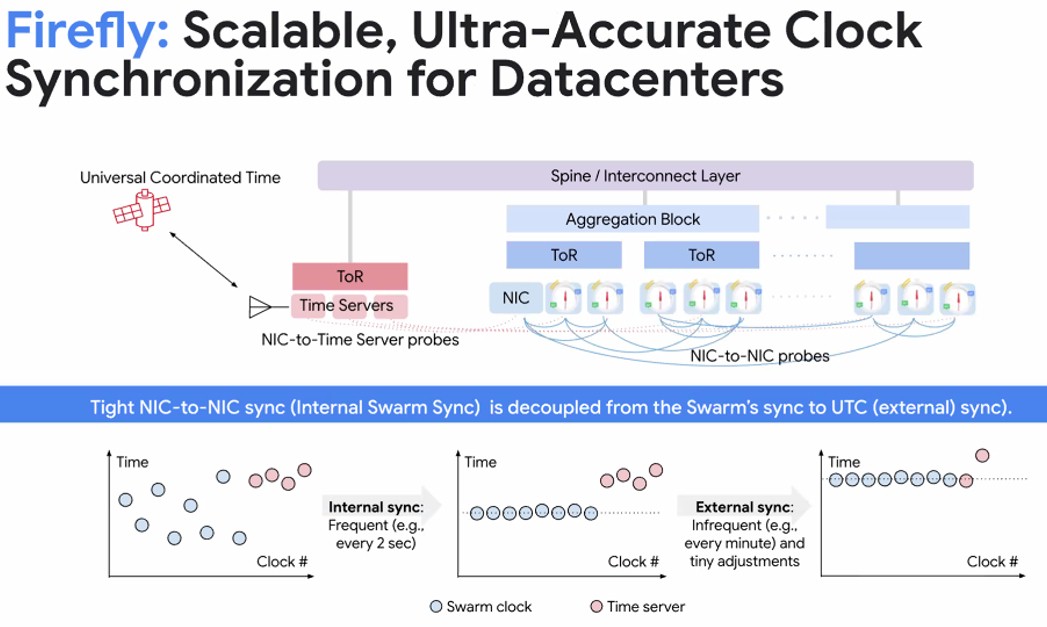
Firefly can synchronize network interface cards (NICs), which do all of the heavy lifting in the network of the future rather than burden host systems and switches, in under 10 nanoseconds and can synchronize a NIC to a Universal Time Clock (UTC) in under 1 millisecond, and this, says Vahdat, allows for the scheduling of AI collective operations in tens of nanoseconds. This is in a world where it takes hundreds of nanoseconds to hope from port to port inside of a high-end Ethernet switch based on something like Broadcom’s “Tomahawk Ultra” StrataXGC switch ASIC and a lot more than that for earlier Tomahawks.
Aside from making AI training work better (and we presume AI inference, too), what using Firefly synchronization and network scheduling means is that the idle time of the XPUs in a cluster will be a known, predictable, and lower quantity than it might otherwise be, which in turn means hundreds of billions of dollars of GPU systems sold in the world each year could drive more value than they currently do when they are sitting around scratching themselves waiting for data.
The Swift congestion control developed by Google is much older than Firefly, which is why it exists at all. This congestion control method was revealed at SIGCOMM 2020 in a paper called Swift: Delay Is Simple And Effective For Congestion Control In The Datacenter. Swift runs on NICs and host servers and basically says “Hold on a second,” which is something that Ethernet doesn’t like to do, to combat network congestion. (Perhaps it should have been called “Waitaminit” eh?)
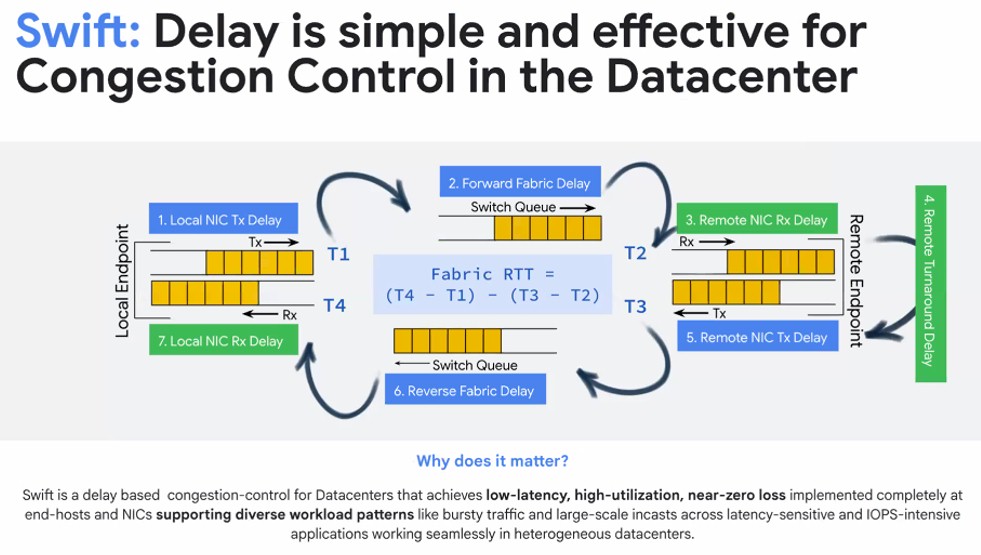
What Swift does, explained Vahdat in his talk, is maintain fine-grained information about all of the information that was queuing up around the network and the hosts and adjust the sending rates of data across the network to hit a targeted level of low-level queuing in the network. The net effect of this is that Ethernet networks running Swift congestion control can handle bursty traffic like AI and HPC all-to-all communications and large-scale incasts and still deliver data with low latency, at high network utilization rates, and with near-zero packets being lost.
That brings is to the Falcon protocol and what Google and Intel call the Intelligent Processing Unit, or IPU, and what most of us call the Data Processing Unit, or DPU.
Google is investing protocols all of the time to optimize the way data is packaged up and passed around on various networks. We told you about the Aquila protocol and its very specific small cluster use case back in October 2022, for instance. There is a more broadly used host networking system called Snap that was revealed by Google in 2019 in a paper called Snap: A Microkernel Approach to Host Networking, which outlines a Linux-derived network operating system with modules coded up in userspace; one of those modules was Pony Express, a data plane engine that for Snap that is the transport layer including flow control, congestion control, and other functions. As far as we can tell, Snap and Pony Express have been deployed in Google’s host networks since around 2016.
More recently, with a switch to smarter DPUs developed in conjunction with Intel (notably the “Mount Evans” IPU that we talked about here), Google developed a new transport layer for the device called Falcon, which is another element of the fifth epoch network.

“Think of Falcon as a hardware implementation of a reliable and low-latency NIC transport, and is it going increasingly after these extreme performance levels, low tail latency, massive application bandwidth at the significant scale,” Vahdat explains.
The Falcon and related technologies were developed by Google with the help of hyperscalers Meta Platforms and Microsoft as well as Nvidia because RDMA over Converged Ethernet “is better suited for niche use cases than general purpose datacenters,” as Vahdat put it succinctly and perhaps kindly. We don’t know much about Falcon, but a paper called Falcon: A Reliable, Low Latency Hardware Transport is also coming out in SIGCOMM 2025 next month and we will keep an eye out for it. It looks like Falcon will implement Swift delay-based congestion control, among other things. The target was for the Falcon transport to provide 10X the operations per second of the Pony Express transport with 1/10th the tail latency, and it looks like that happened from the early tests Vahdat showed off:

The first hardware to implement the Falcon hardware transport layers is the Mount Evans E2100 designed in conjunction with Intel, which has sixteen Arm Neoverse N1 cores and 48 GB of memory with two 100 Gb/sec ports on it.
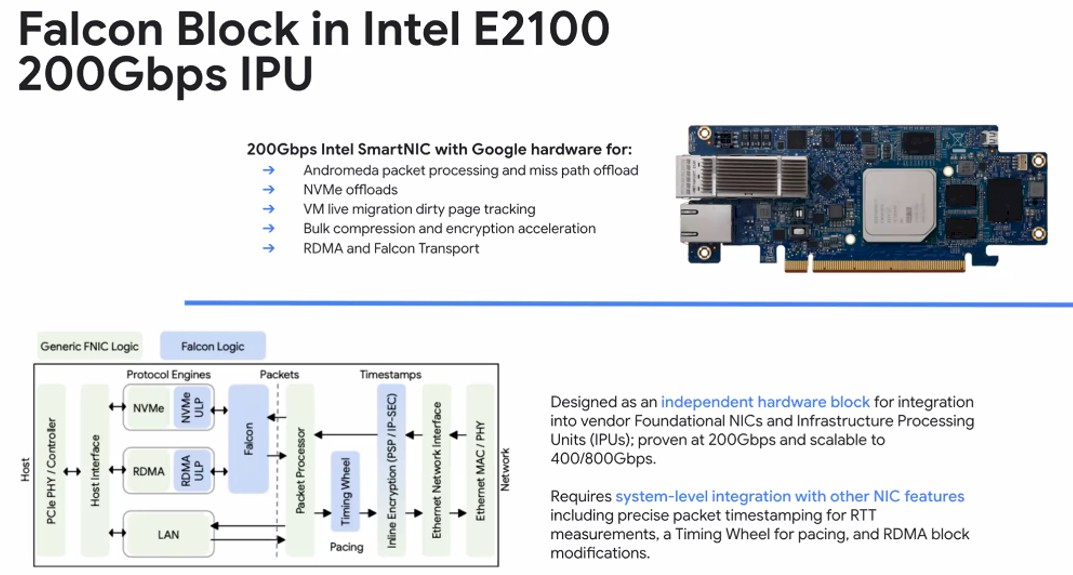
The one that Google is getting has specialized hardware for the company’s homegrown “Andromeda” out-of-band network virtualization stack, which we told you all about way back in November 2017 and elaborated about in a Q&A with Vahdat later that year. The NIC also runs Google’s own implementation of RDMA and has circuits to help with VM live migration, NVM-Express flash virtualization, and compression and encryption for data in flight. Vahdat hints that versions of Mount Evans with 400 Gb/sec and 800 Gb/sec of bandwidth (probably in two-port and one-port versions as Google needs) are coming down the road.
This is something that, as far as we know, Intel has done correctly and has resulted in a DPU that it can hopefully sell into the mainstream.
For Google, the Falcon transport means that both median and tail latencies for its NICs are close to the ideal throughput, and “goodput” is saturated at the maximum link speed. It has about the same latency as an Nvidia ConnectX-7 as the queue pairs increase, but somewhere around 3.000 to 4,000 QPs, the CX-7 latencies spike by just shy of 3X that of the Mount Evans device.
That leaves Straggler Detection as the final piece of the fifth epoch of networks that Vahdat spoke about at HOTI 2025.
“We have robust mechanisms for being able to detect not just the hard failures, but the increasingly challenging soft failures or stragglers that might take place,” says Vahdat. “Say that a node is down, or that network link goes down. Maybe it’s just slow – it might be factor of 2X slower, it might be factor of 4X slower than everybody else for whatever reason. Maybe you have a bit error rate going up, maybe you have some PCI-Express issue. There are a hundred things that could go wrong that don’t actually cause a hard failure. How do you localize that, detect it, and essentially remove that element or repair it from the network, very, very quickly?”
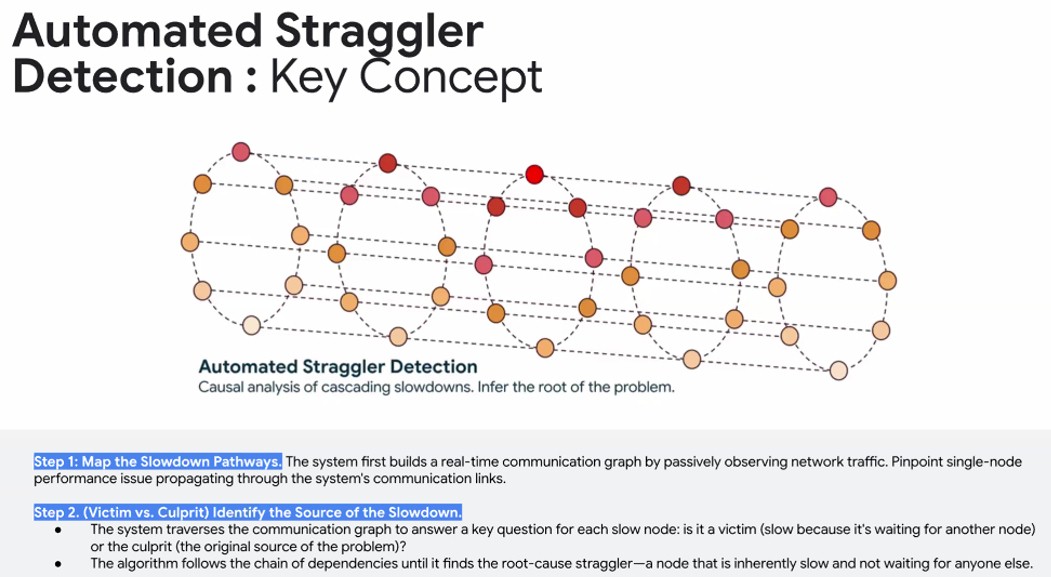
This is not trivial. But remember, in AI workloads, as with HPC workloads, when one node is down, the whole training run or simulation stops or moves so slowly that it might as well. (Which is why checkpointing calculations is equally important with AI and HPC workloads.)
Vahdat ran out of time to get into Straggler Detection in much detail, but says that the system it has come up with for finding faults in the clusters in its datacenters takes a process that might take days of manual debugging from the smartest people at Google down to minutes of automated triage. We would love to know how much AI has been deployed in this system that keeps AI systems going. The gist is that Google takes telemetry from all of the NICs, switches, and hosts in the network and creates a real-time, live communication graph of all of these devices and when there is a fault, finds all of the victims and figures out how to go upstream from them on the graph to quickly find the culprit device that is misbehaving and causing an issue. It does this by finding the root cause straggler – the node that is slow and is not waiting for any other node.
And there you have it. Or, more precisely, there you don’t have it until all of these ideas are implemented by the Ultra Ethernet Consortium, the Open Compute Project, and others.

Sign up to our Newsletter
Featuring highlights, analysis, and stories from the week directly from us to your inbox with nothing in between.
Subscribe now
Related Articles