Real-time three-dimensional perception remains a significant challenge for robotic systems due to the computational demands of accurate processing, but researchers are now demonstrating a pathway to efficient embedded 3D vision. Sibaek Lee, Jiung Yeon, and Hyeonwoo Yu, from Sungkyunkwan University, present a novel approach that moves away from computationally intensive methods, instead employing an interpolation-free tri-plane lifting and volumetric fusion framework. This innovative technique directly projects 3D voxel data into plane features, reconstructing a feature volume through streamlined broadcast and summation, and crucially shifts computational complexity to more efficient two-dimensional convolutions. The resulting system achieves robust real-time performance on embedded hardware, such as the Jetson Orin nano, while maintaining or improving accuracy in tasks like classification and completion, and offering a favourable trade-off between speed and precision for segmentation and detection, thereby paving the way for more capable and responsive robots.
Tri-Perspective View for 3D Scene Understanding
This research details a new method for understanding 3D scenes from 2D images, specifically predicting both the occupancy of space and the semantic label, or type, of objects within it. To address limitations of existing methods, scientists developed a Tri-Perspective View (TPV) method that leverages three different perspectives, front, top, and side, of a single RGB image to improve 3D understanding. The method transforms the input image into these three views, extracts features from each, and unprojects them into 3D voxel space to estimate their likely origin. Combining unprojected features from all three perspectives creates a comprehensive 3D feature map, used to predict both occupancy and semantic labels for each voxel.
This approach allows for strong 3D scene understanding from a single image, eliminating the need for multi-view stereo or depth sensors. Experiments demonstrate that TPV achieves state-of-the-art performance on standard 3D semantic segmentation datasets, including ScanNet and SUN RGB-D, with visualizations confirming accurate reconstruction and labeling of objects in indoor scenes. The research builds upon concepts from related fields, such as Neural Radiance Fields, and integrates well with transformer-based architectures for 3D understanding. It also offers a way to implicitly estimate depth from a single view, drawing connections to related works like BEVFormer and sparse occupancy prediction methods. This presents a novel and effective approach to 3D scene understanding from single RGB images, offering potential applications in robotics, augmented reality, and virtual reality.
Tri-Plane Lifting for Efficient 3D Perception
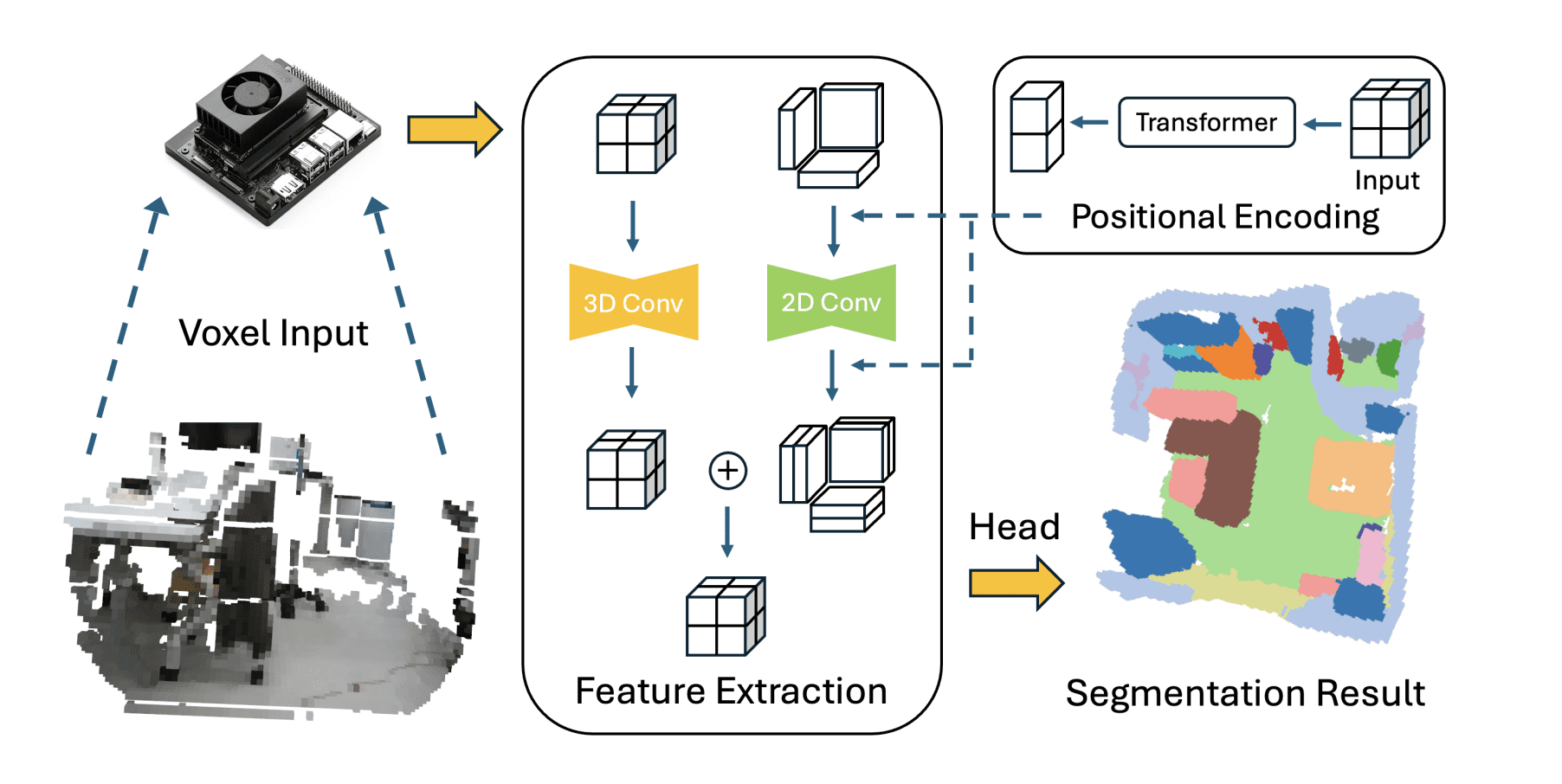
Scientists developed a new method for efficient 3D perception on embedded systems, addressing the significant computational demands of real-time robotic applications. The team pioneered an interpolation-free tri-plane lifting and volumetric fusion framework, directly projecting 3D voxels into plane features using 2D convolutions and reconstructing a 3D feature volume through broadcast and summation. This significantly reduces computational complexity while maintaining full parallelizability. To capture broader contextual information, the team integrated a low-resolution volumetric branch with the lifted features via a lightweight channel-mixing layer, creating a hybrid design that balances efficiency and accuracy.
An adaptive positional encoding module was also incorporated, generating embeddings that capture relationships between slices with minimal computational overhead. Experiments across classification, completion, segmentation, and detection tasks demonstrate the effectiveness of this approach. Results demonstrate that classification and completion tasks retain or improve accuracy, while segmentation and detection achieve significant computational savings with only modest reductions in accuracy. On-device benchmarks conducted on an NVIDIA Jetson Orin nano confirmed robust real-time throughput, establishing a new benchmark for efficient 3D processing and validating its suitability for embedded robotic perception applications.
Tri-Plane Perception for Real-Time Robotics
Scientists developed a new method for efficient 3D perception, achieving real-time performance on embedded robotic systems. The work centers on a tri-plane representation, redesigned to eliminate computationally expensive interpolation and point-wise queries. The method directly projects 3D voxels into plane features and reconstructs a 3D feature volume through broadcast and summation, significantly reducing complexity while maintaining full parallelization. To capture broader context, researchers integrated a low-resolution volumetric branch with the lifted features, using a lightweight channel-mixing step.
This hybrid design preserves global information while enabling end-to-end GPU acceleration, resulting in both efficiency and accuracy improvements. An adaptive positional encoding module was also included, generating embeddings that capture relationships between slices with negligible computational overhead, further enhancing reconstruction fidelity. Experiments across shape classification, completion, semantic segmentation, and object detection demonstrate the method’s effectiveness. Classification and completion tasks retained or improved accuracy, while segmentation and detection achieved significant computational savings with only modest reductions in accuracy. On-device benchmarks on an NVIDIA Jetson Orin nano confirmed real-time throughput, validating the practical relevance of the design for embedded robotic perception.
Hybrid 2D-3D Perception for Efficient Robotics
This research presents a novel approach to 3D perception, addressing the challenge of balancing computational demands with accuracy in robotic systems. Scientists developed an efficient hybrid architecture integrating a full-resolution 2D tri-plane stream with a low-resolution 3D volumetric stream, fused through a lightweight integration layer for accelerated processing. An adaptive positional encoding further enhances geometric fidelity with minimal computational overhead. Extensive experiments across diverse tasks, including classification, completion, segmentation, and object detection, demonstrate substantial computational savings.
The method maintains or improves accuracy for classification and completion tasks, while achieving efficiency gains for segmentation and detection with only modest reductions in accuracy. On-device benchmarks using embedded hardware confirm the ability to achieve real-time throughput, highlighting the practical relevance of this design for resource-constrained robotic applications. Further research could explore leveraging multi-core processors to improve throughput and enhance the system’s capabilities. This work establishes a promising direction for efficient 3D perception, enabling robust real-time performance on embedded systems and advancing the field of robotic vision.
👉 More information
🗞 Efficient 3D Perception on Embedded Systems via Interpolation-Free Tri-Plane Lifting and Volume Fusion
🧠 ArXiv: https://arxiv.org/abs/2509.14641