Data
OSM is a globally encompassing geographic information database based on crowdsourced contributions. While accessible through a map interface at https://openstreetmap.org, its primary value lies in being an indispensable source for open mapping data in both commercial and scientific applications54,55,56. Thanks to its permissive licensing, OSM has fostered a large ecosystem of individual and professional contributors. As a result, the project has achieved comprehensive worldwide coverage, with near-perfect mapping quality across the Western world56, while retaining remarkable detail in the global south55. In this study, we utilized OSM data from fall 2023.
OSM uses a tagging system with key–value pairs to categorize and describe all these map objects. Each map object is typically associated with multiple tags that describe its purpose, but may also include additional information, such as opening hours, or data source references. To avoid the complexities of the OSM data model, for our tasks, it was sufficient to focus on two key map objects related to parks: park elements and park spaces. Park elements are zero-dimensional points representing objects such as benches, individual trees and statues. Park spaces refer to areas within the parks, such as meadows, lakes and forests.
Flickr (https://flickr.com) has established itself as one of the most prominent platforms for sharing photography. Since its inception in 2004, the platform has gained considerable popularity, accumulating billions of images. Notably, many of these images have been precisely geolocated, thanks to the utilization of the (phone) camera’s GPS module.
We utilized a substantial dataset comprising geolocated images posted between 2004 and 2015. This extensive dataset offered us a valuable secondary perspective on activities taking place within the parks of the world. By intersecting these images with the park outlines from OSM, we identified 10,788,686 pictures captured within the boundaries of parks in our study cities. To extract the depicted content from these images, we used user-assigned tags in conjunction with automatically generated computer vision labels57,58.
Study area
Our research focused on 35 cities listed in Table 1, which we selected using three criteria to make our analysis broad yet robust.
First, we selected major cities worldwide with populations of at least 650,000. This threshold includes many of the largest urban areas, such as major European capitals and other densely populated regions where parks play a vital role in public well-being. To improve representation in Oceania, however, we made an exception for Christchurch, New Zealand, which has a smaller population. This first criterion allowed us to examine parks in cities from various parts of the world, each affected by its own climate, history and cultural background.
Second, we only considered cities in countries where at least 80% of the population has Internet access59. This ensured we had enough online data (such as tags on OSM or photos on Flickr) for our study. As there are no detailed global data on Internet use in cities specifically, we used the country’s overall access to the Internet as our guide. We decided on this threshold upon our preliminary analyses, finding that, in many cities in Africa and South America, there was not enough digital information for our approach, which relies on social media and collaborative mapping data.
Third, we selected cities where, on average, at least one-eighth of park areas are annotated with health-related tags on OSM. As our analysis relied heavily on OSM data, this criterion ensured a minimum level of information on the platform for our study. We settled on this one-eighth threshold after observing that, below this level, the lack of contributor-added tags limited our ability to extract meaningful information. This primarily excluded cities where most tagging was done predominantly automatically through Earth observation that was not accompanied by manual tagging of OSM contributors. This was mainly the case in China, where nongovernmental mapping is restricted60.
Identifying health-promoting activities in urban greenery
We identified and categorized park-based activities using input from an expert panel consisting of three co-authors of this study. We compiled a comprehensive list of activities commonly undertaken in urban parks. To collect relevant papers, we used two specific queries of Google Scholar: ‘(urban) AND (parks OR greenery) AND usage’ and ‘(activities in urban) AND (parks OR greenery)’. From this process, we retrieved the top 50 scholarly articles for each search phrase, resulting in a total of 91 unique papers. We reviewed each article and collected all activities, resulting in a diverse set of activity descriptions varying in granularity. For example, the literature included both broad terms such as ‘leisure activities’ or ‘recreation’, as well as more specific categories such as ‘physical’ and ‘social’ activities. We also noted plenty of individual activities such as ‘walking’, ‘performing street theater’, ‘fishing’ and ‘playing all kinds of different sports’. Subsequently, we convened to categorize the identified activities, with a particular focus on their potentially different impact on health and on ensuring a consistent level of specificity across categories. Broad terms such as recreation were deemed too general to be analytically useful, whereas distinctions like physical versus social activities were considered meaningful. This process ultimately yielded six distinct categories: physical, mindfulness, nature appreciation, environmental, social and cultural activities.
Annotating park OSM tags with activities using LLM classifiers
To associate different park elements and spaces with health-promoting activities, we annotated OSM tags describing those elements and spaces with activities. This turned out to be a challenging task. OSM is a collaborative platform with some governance and guidelines (https://wiki.openstreetmap.org/wiki/Map_features) for tagging, but the flexible tagging system offers the crowdsourcing contributors substantial freedom. As a result, the data can be inconsistent and fragmented, necessitating thorough cleaning. Each map object, such as park elements and spaces, can be tagged with an unlimited number of tags, offering in-depth descriptions. As a result, we encountered over 30,000 unique key–value pairs associated with park elements and spaces. As our primary focus is on the core functional aspects of these elements, we conducted a data cleaning step (detailed in the Supplementary Information) to remove irrelevant metadata associated with the map objects. This filtering allowed us to focus exclusively on tags relevant to activity-related features, thereby making the annotation process more pertinent to our study.
Using LLMs for annotation
Even for domain experts, linking these tags unequivocally to health-related activities was difficult. For instance, a bench might relate to socializing, enjoying nature or resting after physical activity. Choosing one activity over another often depended on personal experience, as many tags could plausibly refer to multiple activities. Given the large number of items and the specialized nature of the task, we chose an LLM classifier as an alternative to expert annotation or crowdsourcing.
Using LLMs as classifiers offers several advantages as they provide a more objective and consistent approach to annotation, can handle large volumes of data quickly and do so at relatively low cost. In some cases, LLM classifiers have even outperformed crowdworkers61, who may themselves rely on machine learning tools to complete tasks62. Research also suggests that LLM-based annotations can match the quality of those made by domain experts63. Given these benefits, we established a benchmark in our domain to evaluate the feasibility of using LLMs to map OSM tags to health-promoting activities. Three experts manually annotated the 100 most frequent tags, and final labels were selected by majority vote. We then used this expert-labeled dataset to assess the accuracy of the labels generated by different LLM classifiers. The details of the LLM annotation benchmark can be found in the Supplementary Information. The outcome indicated that GPT-4, set at a temperature of 0.9, yielded the best annotation performance of an F1 score of 0.77.
Operationalization of the taxonomy
Using the taxonomy with six categories of health-promoting activities, and GPT-4 as the best-performing annotation model, we ran the annotation of OSM tags describing park elements and park spaces. These tags were then labeled with one of the health-promoting activities, or ‘none’ if they did not support a particular activity. In doing so, we established a lexicon of park elements and spaces linked to health-promoting activities (Extended Data Table 1). We had to exclude the mindfulness activities category at this stage, as none of the OSM tags found in parks was primarily associated with it.
Computing park health scores by aggregating OSM tags
The core method to characterize parks in terms of their potential for health-promoting activities is based on counting the respective park elements and spaces. These counts are then combined to give each park an overall score for each health-related category. This score represents the potential health benefits of each park.
Counting health-promoting elements and spaces in parks
In our process of assigning health-promoting activity scores to each park, we first gathered park elements and spaces within each park using the osmium library. We then assigned health-promoting activities to these elements and spaces based on the lexicon created in the previous step (Extended Data Table 1). We discarded any elements or spaces whose tags did not match an activity category. In a few instances, park elements or spaces could fall into more than one health-promoting activity category. For example, apple trees are annotated in OSM with the tags [natural=tree, produce=apple]. In our lexicon of park elements and spaces, we map natural=tree to the nature appreciation and produce=apple to the environmental category. To account for this overlap, we proportionally assign the element as 50% nature appreciation and 50% environmental. More generally, when multiple tags are matched to different categories, we proportionally count the resource based on the number of matched tags, ensuring that its contributions are accurately accounted for, thus avoiding underestimating secondary activities of multipurpose facilities.
Transforming counts into health scores
After tallying up the park elements and spaces within the park, we measured the overall effect of the park in promoting healthy activities within a city. This score should account for the park’s size and the range of facilities it offers for different activities. Our proposed scoring method is based on the following considerations.
-
(1)
Amount of health-promoting elements and spaces: The number and area of health-promoting facilities determine how much offering there is for each activity.
-
(2)
Area of the park: The character of a park depends on the concentration of health-promoting facilities. Larger parks must offer more to obtain a high score.
-
(3)
Diminishing returns with increased count: We posit that, as the count of these elements and spaces increases, the associated benefits exhibit diminishing returns.
-
(4)
City-specific normalization of park health scores: The value of a park’s facilities for a certain activity is relative to similar facilities in other parks throughout the city.
To reflect these assumptions into our scoring, we proposed a linear regression model to compute the park health scores shown in equation (1). We used the idea of an ‘average park’ in each city to compute a baseline and used the distance of each park to the average park line, that is, the residual, as a score. The average park baseline was determined by computing separate linear regression models for park elements and spaces in each city, estimating the expected amount of facilities relative to the park area.
$${E}_{{\mathrm{Act}}}({\mathrm{log}}_{2}({\mathrm{count}}({\mathrm{Act}})))=i+s\times {\mathrm{log}}_{2}(\,\text{park area}\,)\,| \,{\mathrm{Act}}\in \,\text{Activity Categories}\,,$$
(1)
where i and s represent the intercept and slope of the regression lines, respectively. To obtain regression models for each activity category and both park elements and park spaces, we utilized the binary logarithm to account for the diminishing returns of an increase in park size. For each city, separate regression models were calculated for each activity category, as well as for park elements and park spaces, which is further detailed in the Supplementary Information.
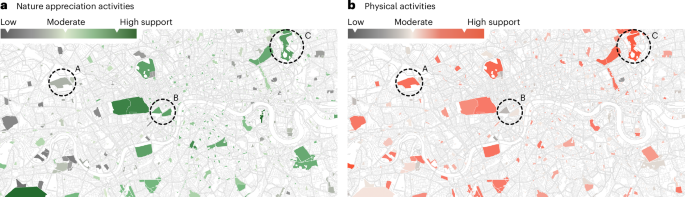
By analyzing the residuals, we identified parks that exceeded expectations (positive residuals) and those that fell short (negative residuals) in providing health-promoting resources for a given activity. We made the linear model dependent on park area so that the resulting scores for health-promoting elements and spaces reflected their density. To reduce the influence of extremely large parks with high amounts of facilities, we applied the binary logarithm. We calculated these scores separately for each city, rather than using a single global model, to ensure that the results reflected each city’s local context. To illustrate this method, we plotted the linear models and the individual park scores in the log–log space for London, UK (Fig. 2). The regression lines denote expected health scores based on park size. The modest R2 values showed that the number of health-promoting facilities could not be explained by park size but instead reflected different design priorities and the needs of local citizens. Park scores for park elements and spaces are residuals from this average park line in the model, adjusting for park size when determining health scores.
Combining scores from park elements and spaces
The regression models gave us individual scores for park elements and park spaces for each activity. To verify the impact of combining these scores into one combined health score, we examined the co-occurrences of park elements and spaces and found that they represent orthogonal concepts in practice, as shown in Extended Data Table 4. Based on this finding, we computed a combined score by first normalizing the scores of park elements and spaces using the z-score transformation, considering all parks in a city. This normalization allowed us to standardize the scores, making them comparable despite being on different scales. Then, we linearly combined these z scores by averaging them together to create the overall score for the park according to equation (2).
$${\mathrm{Score}}({P}_{{\mathrm{Act}}})=\frac{z({\mathrm{residual}}_{{\mathrm{elements}}}({P}_{{\mathrm{Act}}}))+z({\mathrm{residual}}_{{\mathrm{spaces}}}({P}_{{\mathrm{Act}}}))}{2},$$
(2)
where P denotes an individual park, Act is one of the activity categories, the residual scores for elements and spaces stem from equation (1), and z() indicates the z-score transformation.
The combined and normalized scores of park elements and spaces represent a comprehensive and unified measure of the park’s health-promoting amenities and facilities, accounting for both individual elements and cultivated areas. The combination process accounted for the relative importance of each aspect, leading to a more meaningful overall score that represents how well a park is equipped to support performing health-promoting activities. Because the scores are based on z-score-normalized residuals, a value around 0 indicates average support for a given activity, while a score of ±1 means the park is 1 standard deviation above or below the city-wide average.
Quantifying disparities of park scores
One goal of our study was to quantify disparities in health benefits offered by different parks within a city. To measure the disparities in the presence of amenities and facilities associated with health-promoting activities within a city, we propose the following disparity index. The metric essentially quantifies the inequality of the park health scores, as, generally, one could expect that good park management would provide for a similar amount of features and facilities in all parks of a city. As the park health scores could be negative, we cannot directly use a standard inequality metric, such as the Gini index, but had to min–max normalize the park score before computing the Gini index (equation (3)).
$${\mathrm{Gini}}_{{\mathrm{Act}}}(\{{X}_{{\mathrm{Act}}}^{{\prime} }| {X}_{{\mathrm{Act}}}:P\in C\}),$$
(3)
where XAct is the score of activity category Act ∈ [physical, cultural and so on] of a park P in city C, and
$${X}^{{\prime} }=\frac{X-{X}_{{\mathrm{max}}}}{{X}_{{\mathrm{max}}}-{X}_{{\mathrm{min}}}}(\text{min-max}\,\text{normalization}),$$
and the Gini index was computed in a standard way:
$${\mathrm{Gini}}=\frac{A}{A+B},$$
where A is the area between the Lorenz curve and the line of perfect equality and B is the area beyond the Lorenz curve64.
Semantic matching of Flickr labels and OSM tags
In our validation, we leveraged a global dataset of 10.7 million geotagged Flickr images taken within parks across 35 cities. Each image came with user-generated tags, partially annotated by computer vision algorithms. To semantically match these Flickr labels to OSM tags, we used text embeddings, treating the task as an asymmetric semantic search problem. To overcome language diversity in the Flickr labels, we detected the top three non-English languages per city and translated the labels into English using machine translation models. To further improve embedding quality, we enriched OSM tags with concise definitions from the OSM mapping guidelines. The embeddings were generated using the all-mpnet-base-v2 S-BERT model, and matching was done based on cosine similarity, with a threshold of 0.7 to ensure quality. The methodological details are described in the Supplementary Information.
This process yielded 2,171 Flickr-to-OSM matches, with 1,432 corresponding to health-promoting features. To assess accuracy, three experts reviewed the 20 most frequent label–tag matches for London. We aggregated their responses using majority voting. The experts’ annotation agreed with 82% of the matchings, which is highly accurate considering they are based solely on individual tags.
Having assured that the matchings are accurate, we proceeded to profile the parks based on the activities associated with the matched OSM tags, following the same scoring approach as what we used for the OSM park elements and spaces (equation (1)). In our validation, we chose a minimum of 250 images from each park and at least 15 parks in each city. This criterion was established to secure a robust number of images for each park, thus ensuring the accuracy of our analysis. This was a mitigation against potential biases that could have been introduced by individual photographers if a park had only a few images.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.