Biases affecting clinical LLM systems can arise at multiple stages, including data-related biases from collection and representation, model-related biases from algorithm design and training, and deployment-related biases stemming from real-world use and feedback5. Cognitive biases—here referring to systematic deviations from rational reasoning that affect clinical decision-making—can interact with and emerge at each of these stages3,5. For instance, these biases can enter LLM systems through incomplete or skewed training data (e.g., datasets that underrepresent certain patient populations), incorporation of flawed heuristics into algorithms (e.g., diagnostic rules that overlook atypical symptom presentations in certain groups), or deployment in contexts that amplify existing healthcare disparities5,6. The results are tools that not only inherit these clinical reasoning flaws but potentially magnify them through automation3,6. Clinical LLM applications may commonly encounter several notable cognitive biases, though many others exist:
-
Suggestibility bias (prioritizing user agreement over independent reasoning) can lead LLMs to adopt incorrect answers when confronted with persuasive but inaccurate prompts. This can emerge from reinforcement learning methods that optimize for user satisfaction metrics or from training approaches where agreement with user inputs is inadvertently rewarded more than factual correctness6. For example, when presented with confident-sounding rebuttals—particularly those citing external sources—LLMs frequently revised correct diagnostic answers to align with user suggestions, even when doing so meant sacrificing accuracy7.
-
Availability bias (relying on the most easily recalled or commonly seen information) can influence LLM-driven decision support when training data contains overrepresented clinical patterns or patient profiles, causing models to give disproportionate weight to common examples in their corpus6. In an experiment with four commercial LLMs, each model recommended outdated race-adjusted equations for estimating eGFR and lung capacity—guidance no longer supported by evidence—demonstrating how the prevalence and recallability of race-based formulas in the training corpus became the models’ default advice8.
-
Confirmation bias (seeking evidence that supports initial hypotheses) can emerge in clinical LLMs in both development and deployment stages. During development, confirmation bias can be encoded when training labels, such as those used in supervised fine-tuning, reinforce prevailing clinical assumptions or when model evaluation metrics favor agreement with existing diagnostic patterns5. At deployment, the bias can manifest in human-model interactions when interfaces are designed to highlight outputs that match clinicians’ initial impressions5. In one study, pathology experts were significantly more likely to keep an erroneous tumor‑cell‑percentage estimate when an equivalently incorrect LLM recommendation aligned with their preliminary judgment, illustrating how human and model errors can co‑reinforce rather than correct one another9.
-
Framing bias (influence of presentation or wording on decision-making) can affect LLM-enabled systems when the same clinical information presented in different ways leads to different model outputs. This may occur when LLMs learn language patterns where certain descriptive words or presentation formats are statistically associated with particular clinical conclusions in their training data10. One study found that GPT-4’s diagnostic accuracy declined when clinical cases were reframed with disruptive behaviors or other salient but irrelevant details—mirroring the effects of framing on human clinicians and highlighting the model’s susceptibility to the same cognitive distortion10.
-
Anchoring bias (relying on early information in making decisions) can surface in LLM-enabled diagnosis when early input or output data becomes the LLM’s cognitive “anchor” for subsequent reasoning. This effect can emerge when LLMs predominantly process information sequentially (autoregressive processing), generating each part of their response based on what came before, giving more weight to earlier-formed hypotheses when interpreting new information11. In a study of challenging clinical vignettes, GPT-4 generated incorrect initial diagnoses that consistently influenced its later reasoning, until a structured multi-agent setup was introduced to challenge that anchor and improve diagnostic accuracy11.
When medical experts transfer their cognitive biases to AI systems through training data, validation processes, deployment strategies, or real-time interactions during prompting, these systems risk amplifying rather than reducing clinical errors, potentially embedding human cognitive limitations into ostensibly objective computational tools. Yet, it is also worth considering if certain forms of cognitive bias—such as suggestibility—might support the adaptability and responsiveness that give large language models clinical utility, raising the question of whether zero bias is always optimal. At the same time, it is important to recognize that not all model failures are reflections of cognitive bias—for instance, large language models may also generate content that departs entirely from clinical fact, an effect better described as hallucination (Fig. 1).
Fig. 1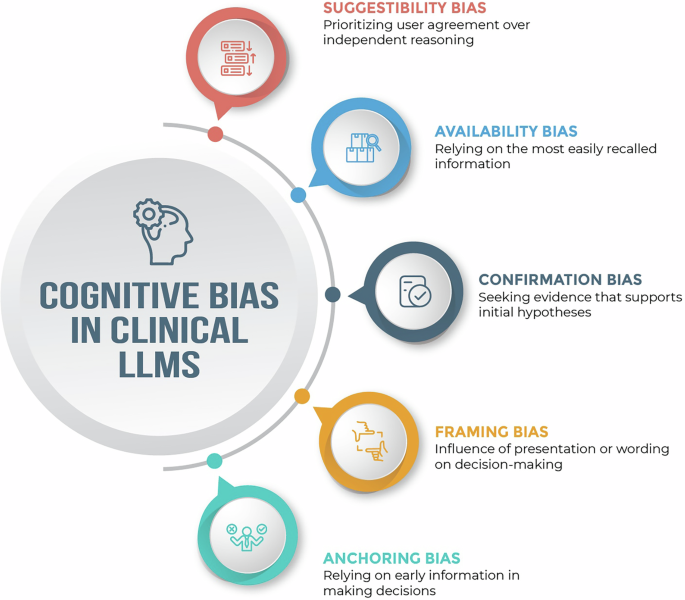
Select cognitive biases in clinical large language models.