Support us! Bikerumor may earn a small commission from affiliate links in this article. Learn More
Justice was finally served a little over a week ago. Strava removed over two million rides recorded as “normal” rides, but apparently accomplished on an e-bike. They made the announcement on their subreddit, where they addressed a “full global backfill aimed at problems” expressed by many commenters.
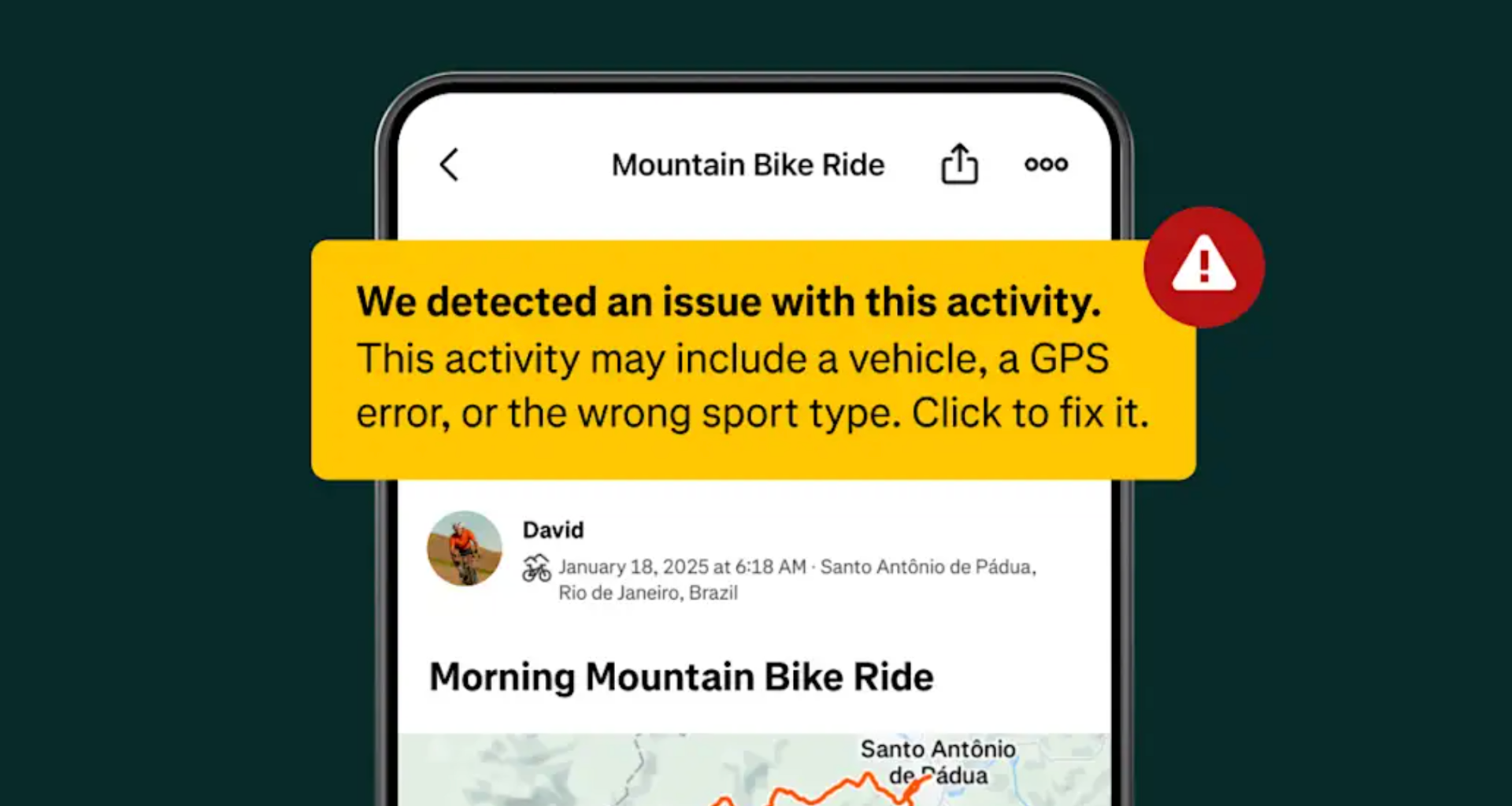
Strava is using “Machine Learning” (ML) models to help clean up logged riding errors, intentional or not. James, an engineer at Strava, explained in the post that the recent crackdowns were threefold.
First, they introduced a new ML model, specifically aimed at catching e-bikes. This “Enhanced E-Bike Detection” flags and removes activities logged as a normal ride, but that were clearly recorded with electric assist.
Secondly, they cleaned up the leaderboard. Strava accomplished this by reprocessing “the top 100 activities on every global ride segment.” They claim this move helps confirm that the leaderboards for these segments are free of vehicle and e-bike use and also of “incorrect sport types,” such as logging a ride as a run.
Lastly, Strava introduced ML that focuses on its run leaderboard, better indicating when a logged “run” is actually completed on a bike.
And, according to Strava’s post, the results of these new actions are pretty astonishing. On the pedal-assist side, they removed 2.3 million apparent e-bike rides. They also detected and removed 1.6 million logged activities using a vehicle. And, because of this, “293k athletes restored to their rightful spot in the top 10.”
How Does Strava Know?
This is a good question, and Strava provides more information in a previous Reddit post from almost a year ago. This time, Nick from the product team provides some context to the longstanding “cheating” issues the app has had. While this previous post doesn’t focus on e-bikes, we can gleam some ideas as to how Strava is tackling these issues.
“Every run activity was broken up into chunks from 800m to marathon length. If a user “broke the world record” during any of those chunks, we know it can’t be a real run. So, we automatically exclude that portion of the activity from segment leaderboards. This keeps the sections recorded in cars or on bikes off leaderboards. But a system like this has a lot of drawbacks. Notably, it doesn’t work on hills. There is no “world record” for hills, especially not hills with different gradients and surfaces. It also doesn’t work if a car drives slowly.”
Nick also notes that the system can be difficult to detect cycling “cheaters,” especially regarding descending.
“For cycling, we also break the activity into chunks and have rules based on the limits of human performance. But in cycling, it’s much trickier to determine what the “world record” for riding over uneven grades actually is. If you “sprint” faster than world-class sprinter Mark Cavendish on a flat or net-uphill road, we know that’s not possible and exclude that part of the activity. But it’s possible for an amateur cyclist to go faster than Cavendish on a given downhill. On the uphills, it’s difficult to say what the limit of performance is. We experimented with using VAM, but these efforts still let vehicles through.”
Strava goes into more detail on how their ML systems work on a post on their website. But, essentially, they look at users’ times that break world records and flag them. Yes, there may be some controversy around users legitimately getting top spots and having their activity flagged. However, we imagine there are ways of proving a run or ride if you’re setting a world record.
Some commenters asked for details on how the ML models detect e-bike rides, but Strava hasn’t released them yet, as it did with its previous ML models. But, they acknowledge that their work isn’t done, and appreciate the subreddit for bringing the “anamolous activities” to their attention.