The escalating power demands of modern artificial intelligence systems drive researchers to explore fundamentally new computing paradigms, and a team led by Kristian Duran, Nanako Kimura, and Zolboo Byambadorj at the University of Tokyo now presents a significant advance in this field. They have developed a field-programmable spiking neural network implemented using standard CMOS technology, offering a potentially transformative approach to hardware reservoir computing. This innovative system overcomes limitations of existing spiking neural networks by integrating voltage-controlled oscillators and programmable connections within a compact, low-power chip design, achieving remarkable energy efficiency without the need for analogue-to-digital conversion. The resulting architecture demonstrates strong performance on benchmark tasks and opens exciting possibilities for scalable, energy-efficient artificial intelligence systems capable of real-time learning and inference directly on the chip.
CMOS Field Programmable Spiking Neural Networks
This research details the implementation of Spiking Neural Networks (SNNs) using CMOS hardware, focusing on a flexible, programmable architecture. Scientists aimed to move beyond software simulations and create dedicated hardware to harness the potential of SNNs for low-power, event-driven computation. The design utilizes a field-programmable architecture, allowing exploration of different network structures, unlike fixed-function circuits. The SNN is built using Complementary Metal-Oxide-Semiconductor (CMOS) technology, a standard in circuit design, and heavily incorporates reservoir computing, specifically Echo State Networks (ESNs), known for their ease of training and suitability for time-series processing.
Scientists designed CMOS circuits to emulate spiking neurons and synapses, employing analog or mixed-signal techniques to capture the temporal dynamics of spiking. The architecture allows programming of synaptic connectivity and weights, enabling implementation of diverse network structures. SNNs, due to their event-driven nature, inherently offer greater energy efficiency than traditional Artificial Neural Networks (ANNs), and this CMOS implementation aims to realize that potential. The research emphasizes reservoir computing principles, where connections within the network are fixed, and only the output layer is trained, simplifying the learning process.
This work falls within the broader field of neuromorphic computing, which seeks to build computer systems inspired by the brain’s structure and function. SNNs represent a third-generation neural network model, more closely mimicking biological neurons by using spikes, discrete events, for communication. Echo State Networks (ESNs) and Liquid State Machines (LSMs) are specific types of recurrent SNNs used for reservoir computing. Implementing spiking neurons and synapses often requires analog or mixed-signal circuit design techniques to capture the temporal dynamics of spiking. In essence, this research explores the practical realization of SNNs using CMOS hardware, with a focus on a flexible, programmable architecture suitable for reservoir computing applications. The goal is to leverage the potential of SNNs for low-power, event-driven computation in areas like time-series processing, pattern recognition, and robotics.
CMOS Neural Network for Reservoir Computing
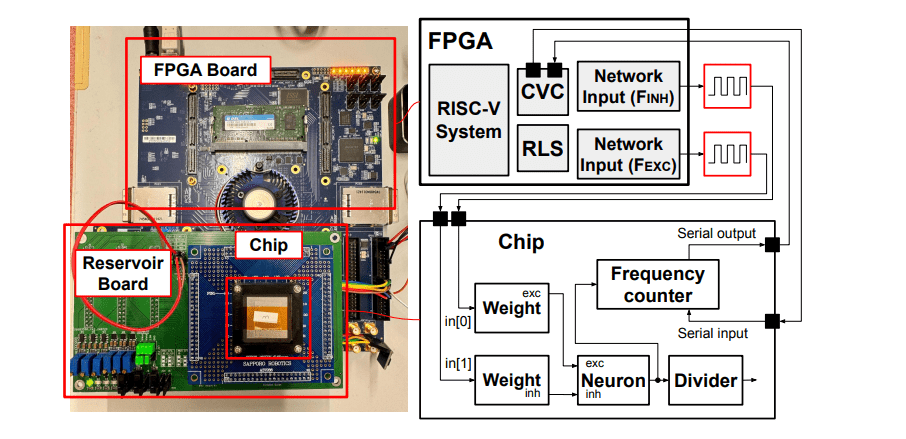
Scientists engineered a novel CMOS-implemented field-programmable neural network architecture for hardware reservoir computing, addressing limitations of traditional systems in edge applications. The core of this system is a Leaky Integrate-and-Fire (LIF) neuron circuit, uniquely integrated with voltage-controlled oscillators and programmable weighted interconnections facilitated by an on-chip FPGA framework, enabling arbitrary reservoir configurations. This design achieves a compact area utilization of approximately 540 NAND2-equivalent units and remarkably low energy consumption of 21. 7 pJ per pulse, eliminating the need for analog-to-digital converters for information readout and making it ideal for system-on-chip integration.
The study pioneered a method for extracting neuron states directly from the chip by converting frequencies to voltages, allowing for real-time optimization using algorithms like FORCE and open-loop optimization. The FORCE algorithm, a feedback approach, dynamically modifies output weights during a teaching period to minimize the error between a teaching waveform and the neural network’s output, utilizing Recursive Least Squares (RLS) for adaptive filtering. To overcome the computational demands of RLS, scientists developed a dedicated accelerator implemented in an external FPGA, significantly enhancing the speed and efficiency of the system. The RLS accelerator features a datapath specifically designed to execute the equations governing the algorithm, including the calculation of the gain vector, the update of the recursion matrix, and the linear combination of neuron states with output weights. The system samples neuron states at discrete time steps, utilizing the approximate capacitor voltage of each neuron as input for the RLS calculations, and then feeds the output prediction back into the reservoir as an adaptive filter. By implementing this hardware acceleration, the research team achieved real-time performance, enabling the system to perform complex learning and inference tasks with high configurability and digital interfacing.
Compact Neural Network Achieves Efficient Reservoir Computing
This work presents a novel CMOS-implemented field-programmable neural network architecture designed for hardware reservoir computing, achieving significant advancements in energy efficiency and scalability. The core of the system is a Leaky Integrate-and-Fire (LIF) neuron circuit, incorporating integrated voltage-controlled oscillators (VCOs) and programmable weighted interconnections facilitated by an on-chip FPGA framework. This design enables arbitrary reservoir configurations and demonstrates effective implementation of the FORCE learning algorithm, alongside benchmarks for linear and non-linear memory capacity and performance on the NARMA10 task, validated through both simulation and actual chip measurements. The neuron design achieves a remarkably compact area utilization of approximately 540 NAND2-equivalent units, paving the way for dense neural networks on a single chip.
Crucially, the neuron exhibits exceptionally low energy consumption, averaging 21. 7 pJ per pulse, without requiring analog-to-digital converters (ADCs) for information readout, making it ideally suited for system-on-chip integration. Experiments demonstrate the system’s capability of solving complex problems, specifically the 10th-degree NARMA10 problem, confirming its computational power. The LIF neuron circuit utilizes a MOS capacitor to integrate incoming signals, accumulating charge onto the capacitor as a voltage, Vcap, through excitation and inhibition transistors. Two VCOs, attached to Vcap, generate currents that modulate ring oscillators, with one VCO increasing and the other decreasing frequency as Vcap changes.
This dual-VCO design allows for precise measurement of the internal neuron voltage and facilitates connections between neurons. Detailed analysis of the neuron’s behavior reveals that excitation signals increase Vcap, while inhibition signals decrease it, demonstrating the integration process. The system’s performance, validated through both simulation and chip measurements, confirms its potential for scalable, energy-efficient real-time learning and inference.
Compact Neuromorphic Chip Demonstrates Reservoir Computing
This work presents a novel, field-programmable neural network architecture designed for reservoir computing, offering a pathway towards low-power, edge-based artificial intelligence. Researchers successfully implemented a system based on Leaky Integrate-and-Fire neurons, constructed using CMOS voltage-controlled oscillators and integrated within a programmable framework, enabling flexible network configurations and efficient computation.
👉 More information
🗞 CMOS Implementation of Field Programmable Spiking Neural Network for Hardware Reservoir Computing
🧠 ArXiv: https://arxiv.org/abs/2509.17355