Discovery and replication cohorts
Our discovery cohort included 2,147 children and adolescents aged 5–20 years from the HOLBAEK Study, 45% of whom were from the general population and 55% from the Children’s Obesity Clinic in Holbæk, Denmark (Fig. 1a). For replication of the genetic effects on plasma protein levels, we included 1,000 additional children and adolescents from the HOLBAEK Study and 558 adults with alcohol-related liver disease aged 19–82 years, matched with healthy controls recruited from the Region of Southern Denmark5. Baseline characteristics for all cohorts are provided in Tables 1 and 2, with the discovery cohort further stratified by sex in Supplementary Note 1. We conducted single-nucleotide polymorphism (SNP)-based genotyping and MS-based plasma proteome profiling (Fig. 1b and Methods). We acquired plasma proteome profiles of all participants (n = 2,147) with a data-independent acquisition (DIA) strategy and a single-run workflow, using a liquid chromatography system designed for robust clinical use24 coupled online to a recently released Orbitrap Astral mass spectrometer25 (Fig. 1c). We performed sample preparation and liquid chromatography–MS analysis using equal plasma volumes, with precursor-level MS signal normalization across samples using Spectronaut’s cross-run normalization method (Methods and Supplementary Note 2)26. After stringent quality control, 1,216 proteins remained with 91% data completeness. Analyzing 94 quality assessment samples over a 6 week measurement period revealed a 33% median coefficient of variation for the entire workflow (Supplementary Fig. 1a–d). We estimated the effect of age, sex, BMI-standard deviation score (BMI-SDS) adjusted for age and sex27 and 5.2 million SNPs on plasma protein levels (Fig. 1d).
Table 1 Participant characteristics in the discovery cohortTable 2 Participant characteristics in the replication cohortsFig. 1: Study overview and proteomics workflow.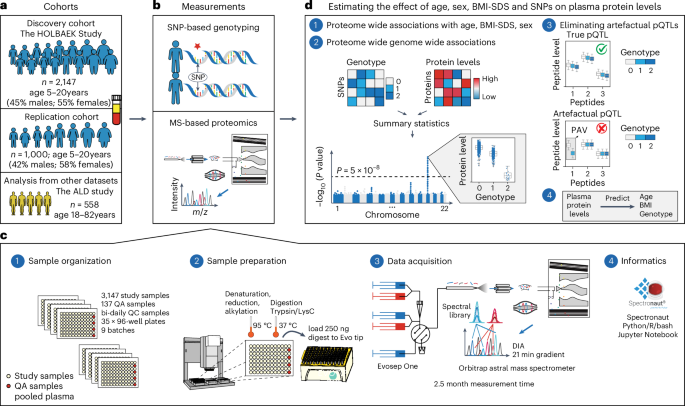
a, Discovery and replication cohorts used in this study. b, MS-based plasma proteome profiling and SNP-based genotyping were performed on the discovery and replication cohorts. c, Proteome profiling workflow and the computational tools used for processing of proteomics data, including (1) sample organization, (2) sample preparation, (3) data acquisition and (4) informatics. d, Schematic representation of (1 and 2) the association analysis with (3) a quality control step to eliminate artefactual pQTLs as described in the main text and (4) prediction of age, BMI and genotype based on plasma protein levels. ALD, alcohol-related liver disease; m/z, mass to charge ratio; QA, quality assessment; QC, quality control.
Impact of demographic and health factors on plasma proteome
To the best of our knowledge, this is the first MS-based proteomics study on neat plasma with substantial depth (>1,000 proteins), largely owing to the use of the Orbitrap Astral mass spectrometer25 for this purpose. We investigated the biological processes represented by the quantified proteins. The most prevalent processes included complement and coagulation cascades, metabolism and inflammatory response, reflecting the key roles of plasma proteins in immunity, blood clotting and transport (Fig. 2a).
Fig. 2: Age-associated, sex-associated and BMI-SDS-associated plasma proteins.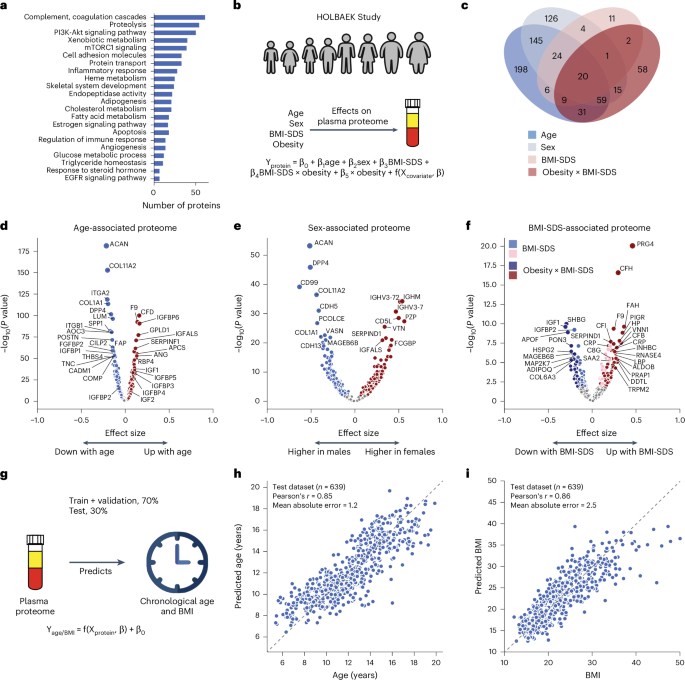
a, Biological processes represented by all identified proteins after quality control. b, Schematic representation of linear modeling of protein levels using various factors. c, Number of proteins associated with age, sex, BMI-SDS and the interaction term between obesity status and BMI-SDS; n = 1,601 biologically independent samples. d–f, Volcano plots showing proteins associated with age (d), sex (e) and BMI-SDS (f), highlighting strongly associated proteins. For c–f, multiple linear regression was used to test for association, with beta coefficients estimated using ordinary least squares regression. Two-sided P values were approximated using a t-distribution with significance set at Benjamini–Hochberg-corrected P g, Schematic representation of linear modeling of age and BMI using plasma proteome. h,i, Prediction of age (h) and BMI (i) in the test set. Pearson’s correlation coefficients between predicted and real values are indicated; n = 639 biologically independent samples.
To assess the impact of age, sex and BMI-SDS27 on the plasma proteome, we performed multiple linear regression analysis (Fig. 2b and Methods). In total, 58% of the quantified plasma proteins were associated with at least one of these factors (40% with age, 32% with sex and 22% with BMI-SDS), with 8% linked to all three based on the current dataset and our modeling (Fig. 2c). Proteins most strongly associated with age included known age-related proteins such as F9 (ref. 28), RBP4 (ref. 29) and COL1A1 (ref. 9) as well as others not previously linked to age, such as GPLD1, APCS and IGFALS (Fig. 2d and Supplementary Table 1). The age association of IGFALS aligns with evidence that defects or low expression of IGFALS can cause pubertal delay in children30. In addition to individual proteins, our dataset reveals insights into three critical biological processes that occur during pediatric development. Firstly, we observed an age-related increase in IGF1 receptor signaling, with IGF1 levels peaking at ages 12–13 years in female adolescents and 14–15 years in male adolescents and then declining (Extended Data Fig. 1a,b), consistent with the literature31,32. IGFBP5 mirrored IGF1, although the levels of IGFBP1 and IGFBP2 declined from childhood through adolescence (Extended Data Fig. 1c–e). IGFBP1 and IGFBP2 were consistently reduced in children with obesity, along with adiponectin (Extended Data Fig. 1d–f). Similarly, SHBG, A2M and CRP all showed obesity-dependent levels (Extended Data Fig. 1g–i). Secondly, we captured post-pubertal declines in essential bone development proteins (ACAN, COL1A1, COL1A2, THBS4, COMP and POSTN), reflecting sex-specific differences in growth plate closure during skeletal maturation (Extended Data Fig. 1j–m). Aggrecan (ACAN) is a major proteoglycan in cartilage, and mutation in this protein causes early growth cessation, resulting in a severely reduced adult stature31. Our data documents a more than tenfold decline in ACAN levels starting at age 12–13 years for female adolescents and 13–14 years for male adolescents, offering the potential for early growth disorder diagnostics. Thirdly, proteins involved in angiogenesis and cellular adhesion (ANGPTL3, CDH5, ITGB1, ICAM1, VCAM1 and ACE) showed an age-related decline (Extended Data Fig. 1n–q). This analysis identified proteins not previously associated with childhood obesity, to the best of our knowledge, including A2M, PON3, ADAMTSL4, HSPG2 and MAGEB6B, all of which showed decreased levels in children with obesity.
Similarly, we recapitulated known sex differences in protein levels, such as PZP and BCHE, and identified proteins without previously reported sex-specific differences, including CD5L (Fig. 2e and Supplementary Table 1). Notably, CD5L and IGHM emerged as the top proteins associated with sex, aligning with the observation that females have higher IgM levels than males33. This finding is further supported by a recent report showing that CD5L is an obligate member of circulating IgM34.
We included an interaction term between BMI-SDS and obesity status to assess whether protein association with BMI-SDS differed between subgroups. Of the 240 BMI-SDS-associated proteins, 163 were specific to the obesity group and 32 showed differing effect sizes between groups (Fig. 2c). This suggests that a general population of similar size would have yielded fewer BMI-SDS-associated proteins. Inflammatory proteins showed the strongest associations with BMI-SDS, including CRP, complement system proteins (C3, CFH, CFI) and acute phase proteins (A2M, APCS, SAA1, LBP)35 (Fig. 2f). Most of these were also statistically significant in the normal weight group, albeit with smaller effect sizes, indicating that elevated inflammatory protein levels with increasing BMI-SDS are not exclusive to obesity (Supplementary Table 1). Among the BMI-SDS-associated proteins is ANGPTL3, which has shown variable associations with BMI and obesity in previous studies (Supplementary Note 3). Notably, we observed that PRG4 decreased with weight loss35, consistent with its positive association with BMI-SDS in this dataset. Interestingly, PRG4 deficiency protects mice against glucose intolerance and fatty liver disease, suggesting the therapeutic potential of the proteins identified here36.
Further exploring age, sex and BMI-SDS interactions revealed 24 proteins with interaction effects between age and BMI-SDS, 18 between sex and BMI-SDS and 149 between age and sex, including PZP, AGT, SHBG and the above-mentioned bone development proteins (Supplementary Table 2).
Plasma protein levels can serve as a ‘biological clock’ in adults9. We extended this concept to children and adolescents, accurately estimating age within ±1.2 years using the 50 most predictive proteins (Pearson’s r = 0.85 between predicted and actual age) in a subset of 639 individuals not included in model training (Fig. 2g,h, Supplementary Table 3 and Methods). Likewise, a panel of 50 proteins consistently indicated BMI (Fig. 2i). Age-predictive proteins primarily regulated IGF1 receptor signaling, cartilage and skeletal development, fibroblast growth factor response and cell–cell adhesion. Notably, the top five to ten proteins alone predicted age nearly as well (mean absolute error, 1.5–1.6 vs 1.2 years for all 50). BMI-predictive proteins included established obesity markers and obesity-related proteins, including adiponectin, CRP, IGFBP1, IGFBP2, PRG4, SHBG, apolipoproteins (APOA4, APOF) and inflammatory response proteins (A2M, APCS, LBP, HSPG2, HP, AOC3, ITGB1, VNN1).
Effect of SNPs on the plasma proteome
We tested 5.2 million SNPs for association with plasma levels of 1,216 proteins in 1,909 individuals (Methods). We defined the primary protein QTL (pQTL) of a protein as the most significant variant in linkage disequilibrium (r2 > 0.2) within ±1 Mb of the protein-coding gene (Supplementary Note 4)37,38.
In addition, we performed genome-wide association analysis on nearly 10,000 peptides after quality control. Protein-altering variants can lead to alterations in amino acid sequences and modify the binding surfaces in the case of affinity-based technologies, potentially introducing biases in proteomics studies17,22,39. To address this source of potential bias, we developed a framework leveraging peptide-level data to exclude artefactual pQTLs and categorize pQTLs into confidence tiers based on peptide-level evidence (Methods and Extended Data Fig. 2a–d).
Applying a study-wide significance level of P −11 (5 × 10−8 adjusted for 1,216 proteins tested) yielded 1,252 primary pQTLs for 327 proteins (Supplementary Table 4). For downstream analysis, we adopted the conventional genome-wide association study (GWAS) significance threshold of P −8, identifying 1,947 primary pQTLs for 443 proteins (Fig. 3a,b). Approximate conditional analysis revealed 733 conditionally independent pQTLs for 443 proteins (Methods and Supplementary Table 5). Genomic inflation was well controlled (median lambdaGC = 1.002, s.d. = 0.004; see Supplementary Note 5 for quantile–quantile plots). Comparison with our previous dataset, which was generated using an older generation of MS40, reveals that our methodology produces highly consistent protein quantification across time points and instrumentations (Extended Data Fig. 3a–h, Supplementary Table 6 and Supplementary Note 6). This confirms the robustness of our findings and suggests that our approach can reliably detect biological variation despite technological advancements or delays in sample analysis.
Fig. 3: Characterization of pQTLs.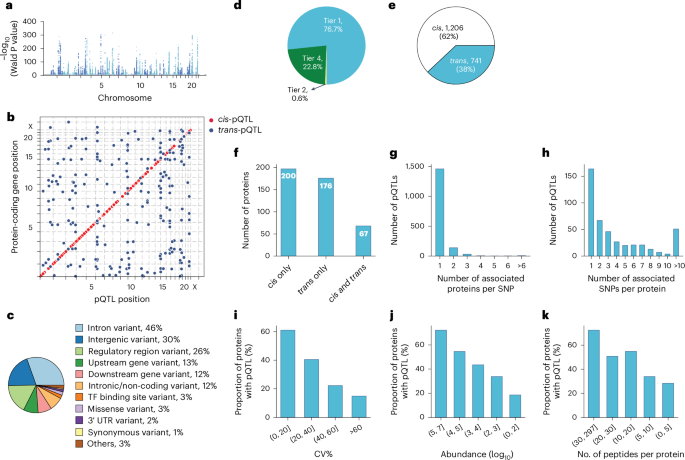
a, Primary pQTLs across the genome (two-sided Wald test in a linear mixed model with genome-wide significance P −8). b, Primary pQTLs against the locations of the transcription start site of the gene coding the protein target. c, Variant annotation. d, Classification of pQTLs based on peptide-level evidence. e, Number of cis-pQTLs and trans-pQTLs. f, Number of proteins that are associated with cis only, trans only and both cis and trans-pQTLs. g, Distribution of the number of associated proteins per SNP. h, Distribution of the number of associated SNPs per protein. i–k, Proportion of proteins with genetic associations when stratifying proteins into buckets based on technical variation (i), median abundance (j) and number of identified peptides after quality control per protein (k). TF, transcription factor; UTR, untranslated region; CV, coefficient of variation.
These pQTLs are primarily located in the non-coding regions, with only 3% representing missense and 1% synonymous variants (Fig. 3c, Supplementary Table 4 and Methods). The dominance of non-coding variants among the identified pQTLs is consistent with previous studies reporting 86% and 98% of them37,41.
Genetic variations normally affect the expression level of the entire protein. Therefore, all peptides identifying the same protein should generally show the same fold change between genotypes. Our peptide-level analysis showed that 77% of reported pQTLs had at least two supporting peptides (Fig. 3d and Supplementary Table 4). Notably, in 94% of these cases, all peptides exhibited the same direction of effect, indicating highly consistent quantitative information at the peptide level (Extended Data Fig. 4a–c). The peptide-level data also helps quantify protein variants affected by amino acid substitutions, a limitation in affinity-based proteomics as demonstrated by the influence of rs9898 on histidine-rich glycoprotein abundance42. We identified the association between rs9898 and circulating histidine-rich glycoprotein levels, which was successfully replicated in both the pediatric and adult cohorts, with a 62% protein sequence coverage and 26 supporting peptides (Extended Data Fig. 5a–d). Importantly, protein quantification was unaffected by the missense mutation (Pro204Ser), which was not identified, probably because it would only produce a four-amino-acid sequence (NCPR) but would have been an outlier if it had. This example illustrates an important advantage of MS-based proteomics in navigating the complexities of protein quantification across variants.
Fig. 4: Variance in plasma protein levels explained by various factors.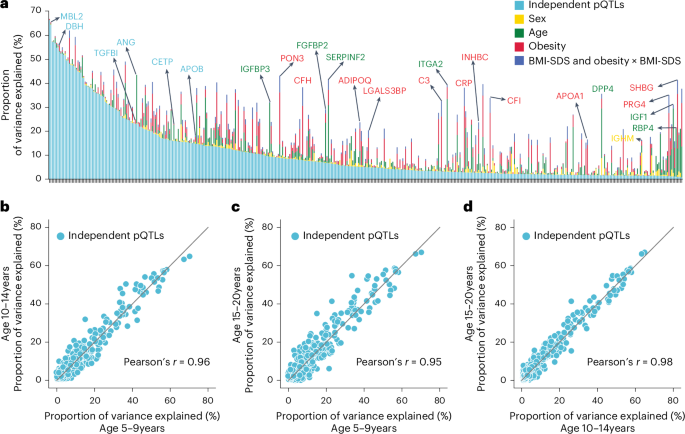
a, Proportion of variance explained by conditionally independent pQTLs, age, sex, obesity and BMI-SDS (summed variance from BMI-SDS and its interaction with obesity status). Proteins are ordered by decreasing variance attributable to independent pQTLs. b–d, Pairwise comparisons of variance explained by independent pQTLs across three age groups: 10-14 years vs. 5-9 years (b), 15-20 years vs. 5-9 years (c) and 15-20 years vs. 10-14 years (d); Pearson correlation coefficients are also shown.
Remarkably, 62% of discovered pQTLs were in cis and 60% of the proteins had at least one cis-pQTL associated, implying pervasive local regulation (Fig. 3e,f). The MS-based proteomics data recapitulated that the same genomic locus can regulate multiple proteins and that one protein can be regulated by multiple genomic loci. Specifically, 25% of the pQTLs were associated with more than one protein, while 64% of the proteins had multiple pQTLs associated with them and 26% of these had pQTLs located on different chromosomes (Fig. 3g,h).
We reasoned that higher plasma protein abundance would manifest in a higher number and signal of identifying peptides, increasing the likelihood of finding genetic associations. Indeed, as abundance increased, so did the proportion of proteins with genetic associations, a pattern also seen with increased technical reproducibility and peptide count per protein after quality control (Fig. 3i–k).
Decomposition of variance in plasma protein levels
Having established the quality of the pQTLs, we performed variance decomposition to understand the relative contribution of genetic variation and demographic factors to plasma protein levels (Methods). This revealed that independent pQTLs accounted for 1% to 66% of the variance in protein levels (average, 11%), and for 63% of proteins, pQTLs contributed more variance than age, sex, BMI-SDS and obesity combined (Fig. 4a and Supplementary Table 7). However, some proteins were primarily affected by other factors: SHBG by age and obesity; PRG4 by obesity; and IGF1 and RBP4 by age.
To address the important question of how stable the genetic influences are across pediatric development, we segmented the cohort into 5–9, 10–14 and 15–20-year-olds. This revealed a remarkable stability in genetic influences, with Pearson correlations between 0.95 and 0.98 (Fig. 4b–d). Our results establish that MS-based proteomics can provide unique insights into factors determining protein-level variance throughout pediatric development.
Characterization of pQTL effect sizes
Next, we investigated the effect size using beta statistics derived from the association tests and allelic fold change calculated on data before normalization43 (Methods). Although they were mostly mild, 143 pQTLs for 71 proteins exceeded twofold differences in protein levels (absolute log2(fold change) of >1) between homozygous reference (0/0) and alternative (1/1) genotypes (Supplementary Fig. 2a,b and Supplementary Table 4). These large genetic effect sizes led us to reason that protein levels could predict genotype, which was confirmed for eight proteins with a balanced accuracy of ≥0.8 (Supplementary Table 8 and Methods). Local (cis-pQTL) regulation generally had the largest effect sizes (Supplementary Fig. 2c,d). Furthermore, missense mutations, variants in the 5′ and 3′ untranslated regions and transcription factor binding sites had greater average effect sizes than intronic and intergenic variants (Supplementary Fig. 2e), supporting an important role of these regions in transcriptional regulation. Large effect sizes for proteins like MST1, PROCR, BST1, IL1RAP, APOE and LPA may have important implications for clinical and biomarker research (Fig. 5a–f). Notably, the rs2232613-T missense mutation reduced levels of LBP fourfold (Supplementary Table 4). Given the important role of this protein in innate immunity, we speculate that individuals with the mutant form have compromised immunity, which has indeed been reported44. The observed substantial genetic effects emphasize the importance of considering pQTL information when interpreting findings from clinical and biomarker research, particularly for proteins under strong influence of genetic variation.
Fig. 5: Effect sizes and integration of pQTLs with known variant–trait associations.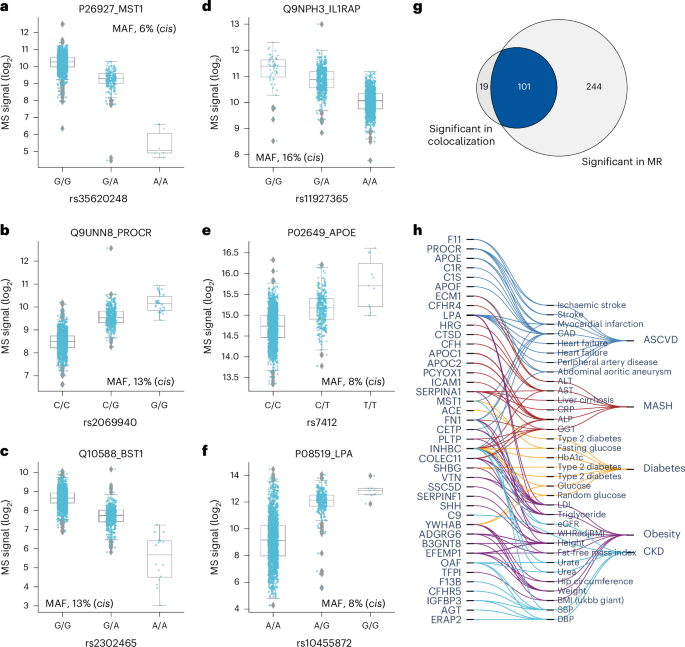
a–f, Distribution of log2 intensity values of the top six proteins with the highest absolute beta value in genome-wide association analysis. The gray line in the middle of the box is the median, the top and bottom of the box represent the upper and lower quartile values of the data and the whiskers represent the upper and lower limits for consideration of outliers (Q3 + 1.5 × IQR, Q1 – 1.5 × IQR); IQR, interquartile range (Q3 – Q1); MAF, minor allele frequency. For genotype 0/0:0/1:1/1, the numbers of biological replicates are n = 1278:328:6, 1708:191:0, 1490:399:23, 1225:410:35, 1637:260:15 and 1227:606:79, respectively. Only non-imputed values are shown. g, Venn diagram showing the number of protein–outcome pairs that are significant in colocalization analysis (HyPrColoc method) and two-sample Mendelian randomization (MR), using a two-sided Wald ratio test implemented in the twoSampleMR package with significance defined as P −6 (correcting for the number of protein-coding genes). h, Protein–trait pairs that are colocalized and with supporting evidence for causation from MR. CAD, coronary artery disease; ALT, alanine aminotransferase; AST, aspartate aminotransferase; CRP, C-reactive protein; ALP, alkaline phosphatase; GGT, gamma-glutamyl transferase; HbA1c, hemoglobin A1c; LDL, low-density lipoprotein; eGFR, estimated glomerular filtration rate; SBP, systolic blood pressure; DBP, diastolic blood pressure; WHRadjBMI, waist-to-hip ratio adjusted for BMI; ASCVD, atherosclerotic cardiovascular disease; MASH, metabolic dysfunction-associated steatohepatitis; CKD, chronic kidney disease.
Integrating pQTLs with variant–trait associations
To investigate whether our MS-based study had discovered previously unreported pQTLs, we compared it to 35 published studies (Extended Data Fig. 6a, Supplementary Table 9 and Methods). This revealed 643 such pQTLs regulating 213 proteins, of which 140 proteins had no previously reported genetic regulation (Supplementary Table 4). Of the remaining pQTLs, 55% were replicated in at least five studies, with cis-pQTLs showing higher replication rates than trans-pQTLs, indicating stronger and more consistent evidence for cis-pQTLs across studies (Extended Data Fig. 6b,c).
Fig. 6: Replication of pQTLs in children and adults.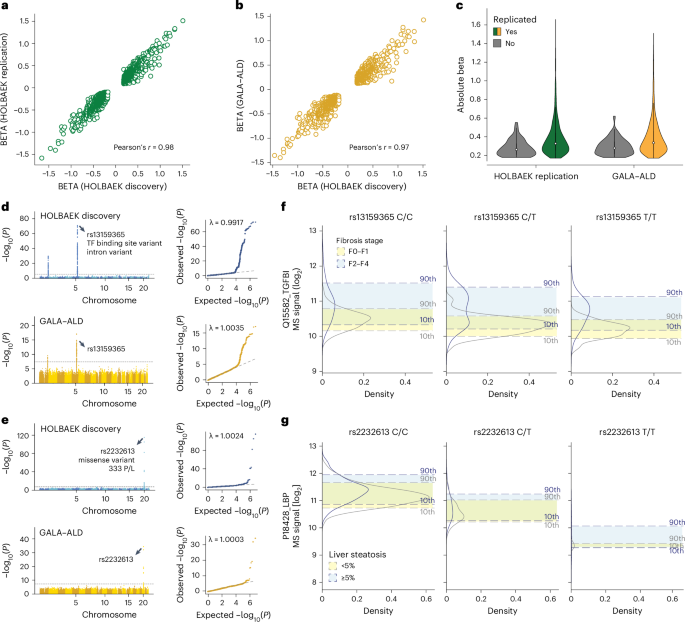
a, Correlation of beta coefficient for replicated pQTLs in the children replication cohort. b, Correlation of beta coefficient for replicated pQTLs in the adult cohort. c, Distribution of absolute beta coefficient of replicated and non-replicated pQTLs. d, Manhattan plot of association between SNPs and plasma levels of TGFBI in the discovery cohort (upper panel) and adult replication cohort (lower panel) with the lead variant annotated. e, Manhattan plot of association between SNPs and plasma levels of LBP in the discovery cohort (upper panel) and adult replication cohort (lower panel) with the lead variant annotated. f, Distribution of plasma levels of TGFBI stratified by the genotype of its lead-associated variant and fibrosis stage in the adult replication cohort. For genotype 0/0:0/1:1/1, n = 96:181:90 and 55:93:43 for fibrosis stage F0–F1 and F2–F4, respectively. g, Distribution of plasma levels of LBP stratified by the genotype of its lead-associated variant and steatosis stage in the adult replication cohort. For genotype 0/0:0/1:1/1, n = 318:52:3 and 157:25:3 for steatosis
GWAS provide increasingly detailed associations between genomic loci and phenotypes but often lack mechanistic insights into the proteins mediating the effects43,45,46. To close this gap, we investigated whether our novel pQTLs were associated with phenotypic traits. Mapping our protein-associated variants to the GWAS Catalog revealed 162 such cases (Supplementary Table 10 and Methods). Many connections were immediately biologically plausible; for example, rs73001065 has been associated with a decreased risk for non-alcoholic fatty liver disease, which our data indicates may happen through reduced APOB levels. Individuals with the bone mineral density-lowering allele rs13469-T in POLDIP2 had reduced levels of SPP2, a protein crucial for bone metabolism healing47. Similarly, children with the type 2 diabetes risk allele rs529565-C in ABO had higher MASP1 levels in our data, consistent with elevated MASP1 levels in patients with type 2 diabetes48,49. Colocalization analysis supported all these associations (Supplementary Table 11).
Our analysis identified 24 proteins associated with missense variants in various genes, including 11 linked to APOE, a key gene in Alzheimer’s and cardiovascular disease. Specifically, the APOE-ε4 allele (rs7412-C and rs429358-C), a major Alzheimer’s disease risk factor, was associated with lower plasma levels of SPTBN4, a brain-expressed protein implicated in neurodevelopmental disorder50. Therefore, we speculated that there is a downregulation of SPTBN4 in Alzheimer’s disease, which is indeed supported by previous reports and its epigenetic silencing in patients with Alzheimer’s disease51,52. Additionally, our data suggests that APOE-ε4 allele’s link to depression53 may involve elevated HTR1D levels, a target of approved treatments for depression and anxiety. These observations offer additional hypotheses for understanding disease mechanisms and potentially alternative therapeutic strategies.
In addition, we performed systematic two-sample Mendelian randomization using the top cis-pQTLs from 267 proteins on 47 cardiometabolic GWAS outcomes including obesity, diabetes, atherosclerotic cardiovascular disease, metabolic dysfunction-associated steatohepatitis, Alzheimer’s disease and chronic kidney disease (Methods and Supplementary Note 7). This analysis reported 345 causal relationships between 106 proteins and 36 traits related to these six highly prevalent diseases (P −6) (Extended Data Fig. 7a and Supplementary Table 12). Of these, 101 (29%) causal relationships between 41 genes and 33 traits were further validated by colocalization (posterior probability above 70%) (Fig. 5g,h, Supplementary Table 11 and Methods). Interestingly, our data causally connect SHH to height, which may be connected to its crucial role in embryonic development. These results illustrate how integrating high-confidence pQTLs with GWAS results helps to understand the molecular mechanisms between variant–disease and variant–trait associations.
Highly replicated pQTLs in children and adults
We assessed the replication rate of the pQTLs in 1,000 children and adolescents and 558 adults, respectively. Around 90% of the pQTLs were eligible for replication owing to independent quality control on proteomics and genomics data (Supplementary Note 8). Of these, we successfully replicated 97% of pQTLs in children (99% of the cis, 92% of the trans and 92% of the novel) and 91% in adults (92% of the cis, 88% of the trans and 90% of the novel) with nominal significance (P 3a,b and Supplementary Tables 13 and 14). The high replication rate in adults suggests that the vast majority of detected pQTLs are not life-stage-specific. To detect such potential pQTLs would probably require larger cohorts with similar sizes and health status. Furthermore, the direction and magnitude of effects aligned well between the discovery and replication cohorts (Pearson’s r = 0.97 and 0.98; Fig. 6a,b), with larger effects observed in the replicated pQTLs (Fig. 6c).
We next asked whether pQTL information could improve biomarker performance, building on our previously reported biomarkers for liver fibrosis, inflammation and steatosis5. For half of these biomarkers, including TGFBI and LBP, which showed the largest genetic effect sizes, we identified and replicated pQTLs (Fig. 6d,e). Our data revealed that TGFBI protein levels shifted depending on its corresponding pQTL in both disease and control groups (Fig. 6f). Incorporating genotype information further improved the accuracy of classifying patients with fibrosis stages F0–F1 versus F2–F4 using TGFBI (Extended Data Fig. 8a). Similarly, we observed a marked decrease in LBP levels associated with the rs2232613 variant (Fig. 6g and Extended Data Fig. 8b). These findings suggest that pQTLs should be integrated into biomarker research, especially for proteins with strong genetic effects, although their impact on classification performance should be evaluated individually.