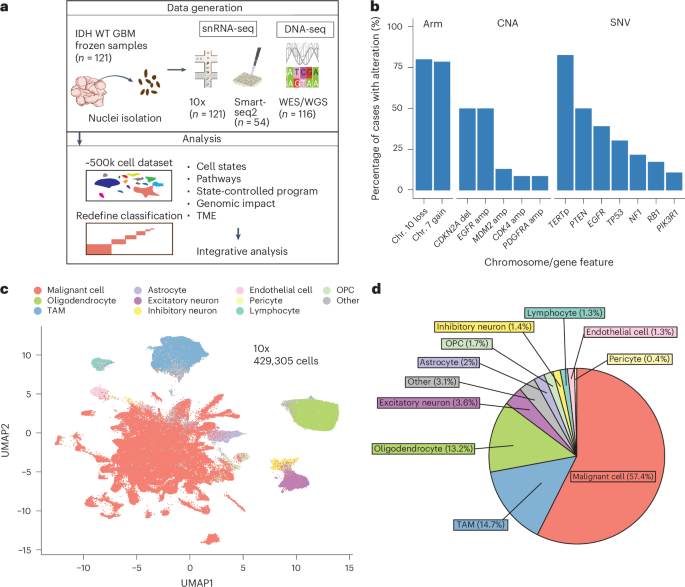
Participants and ethical approval
Frozen GBM specimens, diagnosed as ‘glioblastoma, IDH WT’ according to the WHO 2021 classification, were collected at seven institutions, as outlined in the sections below. Collection and genomic profiling were approved by the institutional review board (IRB) of each institution; all participants provided written informed consent accordingly. Cohorts were added to the IRB of the Dana-Farber/Harvard Cancer Center (no. 10-417). Patients were male and female. Clinical information of the cohorts is summarized in Supplementary Table 1. Additional clinical characteristics related to the longitudinal analyses are shown in the companion study by Spitzer et al.18.
MD Anderson Cancer Center cohort
For this cohort (n = 4), tumors were collected from MD Anderson Cancer Center. Collection was approved by the Institutional Review Board of MD Anderson Cancer Center under the protocol number 2012-0441.
Duke University cohort
For this cohort (n = 12), tumors were collected from the Preston Robert Tisch Brain Tumor Center Biorepository, Duke University Hospital. Collection was approved by the IRB of Duke University under protocol no. Pro0007434.
Tokyo University cohort
For this cohort (n = 30), tumors were collected from the Department of Neurosurgery, Tokyo University Hospital. Collection was approval by the IRB of Tokyo University Hospital under protocol no. G10028.
Pitié-Salpêtrière Hospital cohort
For this cohort (n = 28), tumors were collected from the Pitié-Salpêtrière Hospital and were approved by the Onconeurotek Brain Tumor bank of the hospital Pitié-Salpêtrière under certification no. 96-900.
St. Michael’s Hospital cohort
For this cohort (n = 14), tumors were collected from the Division of Neurosurgery, St. Michael’s Hospital, Unity Health Toronto. Collection was approved by the Research Ethics Board of St. Michael’s Hospital, Unity Health Toronto, under protocol no. REB 13-141; all patients provided signed informed consent accordingly.
Seoul National University cohort
For this cohort (n = 20), tumors were collected from the Department of Neurosurgery, Seoul National University Hospital, Seoul. Collection was approval by the IRB of Seoul National University Hospital (approval no. H-2004-049-1116).
NORLUX Neuro-oncology Laboratory
For this cohort (n = 13), tumors were collected from Centre Hospitalier de Luxembourg (Neurosurgical Department). Collection was approved by the National Committee for Ethics in Research Luxembourg, under protocol no. 201201/06. Cohorts were added to IRB protocol Dana-Farber/Harvard Cancer Center 10-417. Patients were male and female. Clinical information of the cohorts is summarized in Supplementary Table 1. Additional clinical characteristics related to longitudinal analyses are shown in the companion paper by Spitzer et al.18.
Nuclei isolation from frozen tissue
In protocol 1 (laboratory 1 and laboratory 2 for the cohorts from Duke University, MD Anderson Cancer Center, Tokyo University Hospital, St. Michael’s Hospital and Pitié-Salpêtrière Hospital), nuclei from frozen tumor tissue were isolated. Tissue was thawed and mechanically dissociated in ST buffer (10 mM Tris-HCl, pH 7.5, 146 mM NaCl, 1 mM CaCl2, 21 mM MgCl2) with 0.49% CHAPS (no. 28300, Merck Millipore). Single-nucleus suspensions were filtered using a 40-μm strainer, centrifuged at 500g for 5 min and resuspended in ST buffer supplemented with 0.01% BSA (cat. no. B9000S, New England Biolabs). Nuclear suspensions were inspected by microscope, counted using a hemocytometer and used for 10x Genomics workflow or fluorescence-activated cell sorting (FACS) for the Smart-seq2 workflow.
In protocol 2 (laboratory 3 for the cohorts from NORLUX and Seoul National (SNU) cohorts), tissue samples were thawed and mechanically dissociated in Nuclei EZ Lysis Buffer (NUC101, Sigma-Aldrich) using dounce homogenization. Solutions were incubated on ice for 5 min and mixed 1–2 times during incubation. Single-nucleus suspensions were filtered through a 70-μm strainer and centrifuged at 500g for 5 min at 4 °C, resuspended in Nuclei EZ Lysis Buffer and incubated on ice for 5 min. Solutions were centrifuged at 500g for 5 min at 4 °C and resuspended in 1% BSA, 0.2 U μl−1 RNase inhibitor and PBS buffer (three times). For the final resuspension, 4′,6-diamidino-2-phenylindole was added to the buffer; the solution was filtered through a 40-μm strainer, cells were counted on a Countess II Automated Cell Counter (Thermo Fisher Scientific) and nuclei were taken into the 10x Genomics workflow.
10x Genomics for single-nucleus sequencing
The Chromium Single Cell 3′ Reagent Kit Vv3 (cat. no. PN1000128, 10x Genomics) was used according to the manufacturer’s protocol. Briefly, nuclei were loaded on the Chromium Chip (cat. no. PN12000120, 10x Genomics) with a target cell recovery of 6,000–8,000 nuclei and processed in the Chromium Controller. Single nuclei were partitioned into Gel Beads-in-emulsion, followed by RNA reverse transcription with barcoding. Libraries were created by breaking the Gel Beads-in-emulsion and pooling barcoded fractions, complementary DNA amplification, fragmentation and attachment of sample index and adapter, and sequenced on the NextSeq 500 or NovaSeq (Illumina) platform, with paired-end 28–91 bp reads. For the NORLUX and SNU cohorts, nuclei were loaded on a Chromium Chip with a target cell recovery of 6,000 nuclei for single-cell multi-omic assay for transposase-accessible chromatin and gene expression according to the manufacturer’s protocol. The gene expression chemistry for the 10x multi-ome possesses the same chemistry as the 10x v3 3′ snRNA-seq.
Nucleus sorting for Smart-seq2
The nuclear suspension was stained using the Vybrant DyeCycle Ruby Stain (cat. no. V10309, Thermo Fisher Scientific) immediately before FACS. Single-nucleus sorting was performed on a FACSAria Fusion Sorter (Becton Dickinson) using a 640-nm laser (Ruby, 670/14 filter) (Extended Data Fig. 2d). After doublet discrimination, intact nuclei were selected with ruby+ and were sorted into 96-well plates containing TCL buffer (cat. no. 1031576, QIAGEN) with 1% 2-mercaptoethanol (cat. no. M6250, Sigma-Aldrich). Plates were frozen on dry ice immediately after sorting and stored at −80 °C before whole-transcriptome amplification, library preparation and sequencing.
Smart-seq2
Whole-transcriptome amplification, library construction and sequencing were performed as previously published with slight modification for the nucleus as follows4,19. Briefly, on 96-well plates, RNA derived from single nuclei was first purified with Agencourt RNAClean XP beads (cat. no. A66514, Beckman Coulter). Then, Oligo(dT)-primed reverse transcription was performed using Maxima H Minus Reverse Transcriptase (cat. no. EP0753, Thermo Fisher Scientific) and locked TSO oligonucleotide (5′-AAGCAGTGGTATCAACGCAGAGTACATrGrG+G-3′, QIAGEN). This was followed by PCR amplification (22 cycles for snRNA-seq) using the KAPA HiFi HotStart ReadyMix (cat. no. K2602, KAPA Biosystems) with subsequent Agencourt AMPure XP Bead (cat. no. A63882, Beckman Coulter) purification. Libraries were tagmented using the Nextera XT Library Prep Kit (cat. no. FC-131-1096, Illumina) with custom barcode adapters. Libraries from 768 cells with unique barcodes were pooled and sequenced on a NextSeq 500 or NovaSeq 6000 sequencer (Illumina), with paired-end 38 bp reads.
WES
WES for the samples from Duke University, the MD Anderson Cancer Center, Tokyo University Hospital and St. Michael’s Hospital was performed as follows. DNA was extracted from each frozen tumor sample and blood samples corresponding to the patients using the DNeasy Blood & Tissue Kit (cat. no. 69504, QIAGEN). Genomic DNA (100–250 ng) was acoustically sheared using an ultrasonicator (Covaris), targeting 150-bp fragments. Library preparation was performed using the KAPA HyperPrep Kit (cat. no. KK8504, KAPA Biosystems) followed by enzymatic cleanup using AMPure XP beads. Exome capture was performed using a custom exome bait (manufactured by Twist Bioscience to Broad Institute’s specifications). Captured libraries were sequenced with 150 bp paired-end sequencing on a NovaSeq 6000. For the samples from Pitié-Salpêtrière Hospital, after DNA was fragmented by a LE220 ultrasonicator (Covaris) and size-selected, library preparation and capture were performed using Twist Human Core Exome kit (Twist Bioscience) according to manufacturer’s protocol. Sequencing was performed on a NovaSeq 6000, with 200-bp paired-end sequencing.
WGS
Newly generated whole-genome DNA sequencing data were collected for a cohort of frozen samples from the NORLUX Neuro-oncology Laboratory. Briefly, DNA was extracted from each tumor sample using the AllPrep DNA/RNA Mini Kit (cat. no. 80204, QIAGEN) for samples with sufficient tumor tissue and matched normal blood when it was available. Selected tissue for bulk DNA isolation was adjacent to tissue used for single-nucleus data generation. Briefly, DNA was sheared to 400 bp using an LE220 ultrasonicator (Covaris) and size-selected using AMPure XP beads. Whole-genome libraries were prepared and sequenced with 150 bp paired-end sequencing on a NovaSeq 6000 platform. WGS data for the SNU cohort was prepared in an identical manner and was previously reported in ref. 9. Data for the SNU cohort are available on Synapse (https://www.synapse.org/glass).
Statistics and reproducibility
No statistical method was used to predetermine sample size. All available samples were provided by the aforementioned centers and no data were excluded from the analyses. For figures containing box plots, the box spans from the first to third quartiles, median values are indicated by a horizontal line and the whiskers show 1.5× the interquartile range; individual sample points are presented. The statistical analysis described in this work was done using R v.4.0.1 and above.
Somatic variant detection and copy number calling
DNA sequencing alignment, fingerprinting, somatic variant detection (Mutect2) and copy number segmentation was performed in accordance with the Genome Analysis Toolkit best practices using the Genome Analysis Toolkit v.4.0.10.1, as described previously9,48. Briefly, whole-exome and whole-genome reads were aligned to the b37 genome (human_g1k_v37_decoy) using the Burrows–Wheeler Aligner MEM v.0.7.17. DNA fingerprint analysis using ‘CrosscheckFingerprints’ (Picard) confirmed that all samples belonging to a patient came from the same individual, indicating that there were no sample mismatches in this study. Somatic mutations were detected using Mutect2 (v.4.1.0.0) for tumor samples with a matched normal blood sample. A panel of normals was constructed for each sequencing batch to account for differences in DNA library preparation (for example, whole-genome versus whole-exome) and used to filter out common artifactual and germline variants. Patient tumor samples without matched normal blood were analyzed for copy number alterations but not for SNV detection.
Single-cell and single-nucleus data processing of human glioma samples
For Smart-seq2 sequencing data, the reads were mapped to the UCSC hg19 human transcriptome using Bowtie with the following parameters:-q-phred33-quals -n -e 99999999 -l 25 -I 1 -X 2000 -a -m 15–best -S -p 6. For droplet-based sequencing data, the Cellranger v.3.1.0 pipeline provided by 10x Genomics was used for alignment (GRCh38 release 93) and to generate count matrices. Smart-seq2 gene expression levels were quantified as \({E}_{i,\,j}=\log 2(\frac{{{\mathrm{TPM}}}_{i,\,j}}{10}+1)\) where TPMi,j refers to transcripts per million for gene i in sample j, as calculated using RSEM. For droplet-based sequencing data, we quantified the gene expression levels as \({E}_{i,\,j}=\log 2(\frac{{{\mathrm{CPM}}}_{i,\,j}}{10}+1)\), where CPMi,j refers to counts per million for gene i in sample j. We divided the TPM and CPM values by ten as the size of single-cell libraries is estimated to be in the order of 100,000 transcripts; therefore, we wanted to avoid inflating the expression levels by counting each transcript approximately ten times. After these normalization steps, initial filtering of low-quality cells was done based on the low number of detected genes (fewer than 200 genes) or the high expression of mitochondrially encoded genes (more than 3%). Most low-quality cells were removed downstream in case they could not be robustly classified as malignant or nonmalignant (see the later sections on the CNA analysis). Lastly, we computed the average expression of each gene i as \(\log 2[(\frac{1}{n}{\sum }_{j=1}^{n}{{\mathrm{TPM|CPM}}}_{i,\,j})+1]\) and filtered out lowly expressed genes by limiting the analyzed genes to the top 3,000 most highly expressed genes (using the Seurat v.4.0.4 (ref. 49) function CreateSeuratObject). For the cells and genes that passed these quality control filters, we defined relative expression levels by centering the expression levels for each gene across all cells in the dataset as follows: \({{Er}}_{i,\,j}={E}_{i,\,j}-\,\frac{1}{N}{\sum }_{k=1}^{N}{E}_{i,k}\) where N is the number of cells in the dataset.
Clustering and cell type annotation
To facilitate clustering, cell type annotation and scoring of droplet-based data, we used the R package Seurat v.4.0.4 (ref. 49). Unique molecular identifier count data were normalized and scaled (using the NormalizeData and ScaleData functions) and then clustered by projecting the data to a lower dimensional space using PCA and then running the FindNeighbors and FindClusters functions. Initial classification of tumor-associated macrophages, T cells, oligodendrocytes and endothelial cells was based on the expression of known marker genes22,23,24,25,26, whereas the rest of the cells were annotated as presumed malignant. After classification of cells as malignant or nonmalignant (see the following two sections), cells classified as nonmalignant were scored (using the AddModuleScore function) for known cell-type-signatures and assigned a cell type using the method explained in the section ‘Assignment of cells to states’. Finally, heterotypic doublets were filtered our using the R package scDblFinder50.
Inferring CNAs from gene expression data
CNAs were estimated as described previously4,13,14,21 using the function infercna from the R package infercna (an implementation of the original method presented in ref. 3, which is available at https://github.com/jlaffy/infercna) with default parameters. Briefly, the algorithm sorts the analyzed genes in each sample according to their chromosomal location and applies a moving average with a sliding window of 100 genes in each chromosome to the relative expression values. The scores computed for the cells classified as nonmalignant (oligodendrocytes, macrophages and endothelial cells) define the baseline of the normal karyotype and their average CNA values are used to center the values of all cells.
Classification of cells into malignant or nonmalignant cell types
In cells classified using single-nucleus droplet-based sequencing, we generally encountered a lower CNA signal and continuous signal distributions related to (1) lower data quality relative to that observed in single-cell data, and (2) inclusion of nonmalignant cell types, such as astrocytes and neurons, in the presumed malignant group as these cell types could not be classified a priori as nonmalignant because of transcriptional similarity with malignant cells.
Therefore, we used a multi-step classification scheme for the droplet-based, single-nucleus sequencing data.
Step 1: cell classification using detection of copy number events
For each cell j, we computed the CNA signal on each chromosome separately as \({{\mathrm{CNA}}}_{j}^{C}=\frac{1}{n}{\sum }_{i=1}^{n}{{\mathrm{CNA}}}_{i,\,j}^{C}\) where n is the number of genes on chromosome C included in the analysis. We fitted a normal distribution (that is, a classifier) to the signal distributions of the reference cells for each chromosome (using the function fitdistr from the R package MASS v.7.3-56). This enabled assigning each cell with a P value for each chromosome using a two-sided z-test (function pnorm from the R package stats) reflecting whether the cell had a CNA signal that was significantly different than expected from nonmalignant cells. These P values were further corrected for multiple testing (for each chromosome) using the Benjamini–Hochberg method; cells with Benjamini–Hochberg-adjusted P P
Step 2: exclusion of questionable cells based on CNA correlation
We defined the CNA correlation as the Pearson correlation between each cell and the average CNA profile of the tumor sample the cell originated from. We limited the computation to the chromosomes on which ‘real’ events were detected and a control panel of ~1,000 genes from the other chromosomes. Based on the distribution of CNA correlations across the cells classified as malignant, we defined 0.5 as the lower threshold of malignancy. To determine the upper threshold for nonmalignancy, we performed SNV calling from the snRNA-seq data to estimate the algorithm misclassification rate. Briefly, for each sample with available WES data, we called SNVs for each cell using the Vartrix tool (https://github.com/10XGenomics/vartrix) from the FASTQ files. Misclassified cells were defined as cells harboring a malignant mutation that were classified as nonmalignant in step 1 of the algorithm. After a cost-effectiveness analysis (misclassification rate versus percentage of excluded cells), we set 0.35 as the upper threshold for nonmalignancy. Finally, cells classified as malignant with CNAcor 0.35 were reclassified as ‘unresolved’ and excluded from the downstream analysis.
Step 3: refining classification by setting confidence levels
To refine the classification, we defined confidence levels. Confidence level 1 includes cells classified as malignant that harbored a malignant SNV, cells in which at least 50% of the expected CNA events were detected including chromosome 7 amplification or chromosome 10 deletion, and cells classified as nonmalignant with CNAcor
Deriving MPs from gene expression data
To capture the heterogeneity between cells from the same cell type, we leveraged the NMF51. NMF was performed on the relative expression values of each sample independently after setting negative values to zero. The NMF algorithm requires defining a priori the ‘k’ parameter, reflecting the expected number of latent features in the data. Since k varies between samples and is largely unknown, we ran the NMF algorithm on each sample using different values (3–10), thereby generating 52 programs for each sample. Each of these NMF programs was summarized using the top 50 genes based on the NMF coefficients. Derivation of the MPs from the NMF programs was described thoroughly by in ref. 30 and is described briefly here. The method first filters out NMF programs that are not robust (do not recur in the sample they originated from or across several samples) or are redundant in the sample (that is, they highly overlap other NMF programs in that sample). Then, robust NMF programs are clustered according to Jaccard similarity using a customized clustering algorithm that iteratively considers the degree of overlap between robust NMF programs and combines highly overlapping ones to form a cluster. The R 50 most-recurring genes in each cluster define an MP.
Overall, the algorithm yielded 16 MPs that were annotated based on functional enrichment analysis (using GO terms, Molecular Signatures Database Hallmark gene sets and gene sets derived from normal brain development datasets). MP16 included genes from several cell types resulting in an MP that fitted almost all cells and thereby did not reflect any heterogeneity; thus, it was excluded from the analysis. This same procedure was independently repeated for each nonmalignant cell type.
Assignment of cells to states
Malignant cells were scored for the NMF MPs using the Seurat function AddModuleScore. To facilitate cell classification, we generated 20 shuffled expression matrices by sampling each time 5,000 cells and shuffling the expression values for each gene. We then scored each shuffled matrix for the NMF MPs, thereby yielding 100,000 normally distributed scores for each expression program. These served as null distributions for cell-state classification. For each original cell, we computed a P value for each of the expression programs with a z-test (using the R pnorm function) using the statistics of the null distributions that we generated previously. We adjusted all P values for multiple testing using the Benjamini–Hochberg method. Each cell was classified into a specific state if the adjusted P value computed for that state was smaller than 0.05. Cells that achieved Padj Padj
Cells were assigned a ‘cycling’ state on top of their cellular state if they achieved Padj
Hybrids detection and classification
We define hybrids as cells scoring significantly (that is, with Padj
To estimate the expected frequency of technical hybrids, we first computed for each pair of states (A, B) the expected frequency of hybrids, defined as \({\mathrm{Exp}}\left({\mathrm{A,B}}\right)={\mathrm{Freq}}\left({\mathrm{A}}\right)\times {\mathrm{Freq}}\left({\mathrm{B}}\right)\) and the observed/expected ratio defined as \({\log }_{2}(\frac{{\mathrm{Obs}}({\mathrm{A,{B}}})}{{\mathrm{Exp}}({\mathrm{A,B}})})\). As this is an overestimation of the expected frequency attributed to technical effects, we estimated this technical factor (TF) by averaging across observed/expected ratios of hybrid pairs detected less than expected by chance (that is, observed/expected \({\log }_{2}(\frac{{\mathrm{Obs}}({\mathrm{A,{B}}})}{{{\mathrm{TF}}}\times {\mathrm{Exp}}({\mathrm{A,B}})})\). Finally, we filtered out insignificant hybrid pairs with large observed/expected ratio (attributed to small numbers) using a one-sided Fisher’s test. The hybrid lineage model was generated using the R package igraph, with cell states as nodes and edges connecting the states that formed significant hybrid pairs. We did not include the ‘cycling’ state in this analysis because we did not view ‘cycling’ as an independent state but rather as an additional feature that cells can have on top of their neurodevelopmental identity (that is, AC-like, OPC-like, and so on).
BP derivation
Each tumor sample was decomposed to up to seven pseudo-bulk profiles (one for each of the common states—AC-like, MES-like, hypoxia, GPC-like, OPC-like, NPC-like, NEU-like—given at least 25 cells classified to that particular state) by averaging across the normalized unique molecular identifier counts and log2-transforming. Genes were included if their mean log2 expression value across all pseudo-bulks was at least 1 and if their median variance (computed separately within state) was at least 2.5. Overall, 1,005 genes passed these filters. Then, pseudo-bulks were analyzed within state to remove the state-specific signal using PCA. We then derived six gene programs from each state (top and bottom 50 genes of the first three principal components), computed the Jaccard similarity index between each pair of programs and hierarchically clustered the similarity matrix using the ConsensusClusterPlus package (v.1.56.0). Analysis of the cumulative distribution function revealed minor increases in area under the curve for k > 5 (where k is the number of clusters); therefore, k = 5 was chosen as the number of clusters. Then, we derived five consensus signatures by including genes that recurred in at least 25% of programs in each of the clusters (with a hard minimum of at least three times). Using manual inspection and GO enrichment, we annotated the consensus signatures. Two signatures were excluded because of short length or high suspicion of reflecting a technical artifact. To exclude the possibility that ambient RNA had a role in driving the BPs, we estimated the contamination by ambient RNA per sample using the R package SoupX (v.1.6.2). There was no difference in the estimated contamination level across the different BPs and no significant overlap between the top most contaminated genes per sample and the MP or BP signatures (data not shown).
Assigning tumors to composition groups
To measure the differences in tumor composition, we generated for each tumor sample a composition vector reflecting the proportion of each cell type in the tumor sample. This enabled assigning tumors to three main composition groups: high malignant fraction (percentage of malignant cells > 75%); intermediate malignant fraction (percentage of malignant cells 50–75%); and low malignant fraction (percentage of malignant cells 40%, or mixed in case of no dominant TME cell type). Similarly, we defined the proportion vectors for the malignant cell states and assigned tumors to six groups according to the dominant cell state (at least 25% of cells assigned to the particular state)—AC, MES/hypoxia, GPC, OPC/NPC, NEU and mixed (in case of no dominant state). Tumors were classified according to the BP with maximal score and to the mixed category if the maximal score was less than 0.25.
Multilayer group definition
The association between each pair of features (A, B) was computed using a binomial test with the number of times the pair was observed as the number of successes, the number of tumor samples as the number of experiments and the frequency of feature A times the frequency of feature B as the expected probability of success (under the assumption that the features were independent). We then generated an undirected graph by defining each feature as a node and connecting the nodes with edges when a statistically significant association (P
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.